本文主要是介绍Day1 省选衔接题 思路总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Day1 省选题 思路
取数

可反悔的贪心。我们开一个双向链表记录此时每个数的前/后一个数是什么。一个简单但不一定正确的贪心策略即为:每次都取走当前值最大的且可取的数,并更新列表。考虑如何使这个贪心思路正确。
设 p r e x pre_x prex 表示 x x x 的前一个元素, n x t x nxt_x nxtx 表示 x x x 的后一个元素, w ( x ) w(x) w(x) 表示 x x x 的值。则在取走 x x x 后,显然 p r e x , n x t x pre_x,nxt_x prex,nxtx 在这之后都不能被选取。**但如果发现选择 p r e x , n x t x pre_x,nxt_x prex,nxtx 会比只选 x x x 更优呢?**考虑这个贪心每轮都至少新挑出一个元素出来,那么在选择 x x x 后放弃 x x x 选择了 p r e x , n x t x pre_x,nxt_x prex,nxtx,可以理解是将 x x x 替换为后两者中的一个(反悔操作),并新选出了后两者中的另一个。而将 x x x 替换为 p r e x , n x t x pre_x,nxt_x prex,nxtx 的收益为 w ( p r e x ) + w ( n x t t ) − w ( x ) w(pre_x)+w(nxt_t)-w(x) w(prex)+w(nxtt)−w(x),所以我们就可以将这个值也当作一个可选的点,继续进行贪心。
细节部分,在选择了 x x x 后,可以将链表中的 x x x 直接替换为 p r e x , n x t x pre_x,nxt_x prex,nxtx 两点综合起来。具体地,在计算完 x x x 的贡献后,标记 n x t x , p r e x nxt_x,pre_x nxtx,prex 这两个单独的点分别标记为已选,然后就可以更新 w ( x ) ← w ( p r e x ) + w ( n x t t ) − w ( x ) w(x)\gets w(pre_x)+w(nxt_t)-w(x) w(x)←w(prex)+w(nxtt)−w(x)。因为 n x t x , p r e x nxt_x,pre_x nxtx,prex 都不能再单独被选,所以按照正常的链表删除操作删除 p r e x , n x t x pre_x,nxt_x prex,nxtx 两个单独的点。
取数2

题意即为:从 n n n 个集合中各选出一个数求和,求出前 k k k 大的和。为了顺应大家的习惯,这里将 n , k n,k n,k 的意义调换了。
显然最大的取法就是从每个集合中取一个最大值求和,我们设这个最优值为 a n s ans ans。考虑其可能的后几个略小一些的状态。我们将每个集合按照最大值减次大值的差从小到大排序,每个集合内部按从大到小排序。假设当前状态 { i , j , w } \{i,j,w\} {i,j,w} 表示枚举到第 i i i 个集合中的第 j j j 个数,考虑将 a n s ans ans 中第 i i i 个集合取的数更换为 j j j,更换后的答案为 w w w。令 c ( i , j ) c(i,j) c(i,j) 表示集合 i i i 中第 j j j 大的值,最初始的状态即为 { 1 , 2 , a n s − c ( 1 , 1 ) + c ( 1 , 2 ) } \{1,2,ans-c(1,1)+c(1,2)\} {1,2,ans−c(1,1)+c(1,2)}。对于每个状态会有三个可能的分支:
- 如果 j < s i z i j<siz_i j<sizi,则一种可能的选择即为放弃更换为 j j j,考虑更换为 j + 1 j+1 j+1。新的状态为 { i , j + 1 , w − c ( i , j ) + c ( i + j ) } \{i,j+1,w-c(i,j)+c(i+j)\} {i,j+1,w−c(i,j)+c(i+j)}。
- 如果 i i i 不是最后一个集合:
- 一种可能的选择即为决定更换为 j j j,开始考虑 i + 1 i+1 i+1 集合的选择。新的状态为 { i + 1 , 2 , w − c ( i + 1 , 1 ) + c ( i + 1 , 2 ) } \{i+1,2,w-c(i+1,1)+c(i+1,2)\} {i+1,2,w−c(i+1,1)+c(i+1,2)}。
- 另外,如果 j = 2 j=2 j=2,则一种可能的选择即为放弃更换 i i i 中的元素,直接考虑 i + 1 i+1 i+1 集合的选择。新的状态为 { i + 1 , 2 , w − c ( i , 2 ) + c ( i , 1 ) − c ( i + 1 , 1 ) + c ( i + 1 , 2 ) } \{i + 1,2,w - c(i,2) + c(i,1) - c(i+1,1) + c(i+1,2)\} {i+1,2,w−c(i,2)+c(i,1)−c(i+1,1)+c(i+1,2)}。
开一个优先队列记录这些状态,从中取 k k k 轮即为答案。
文件列表

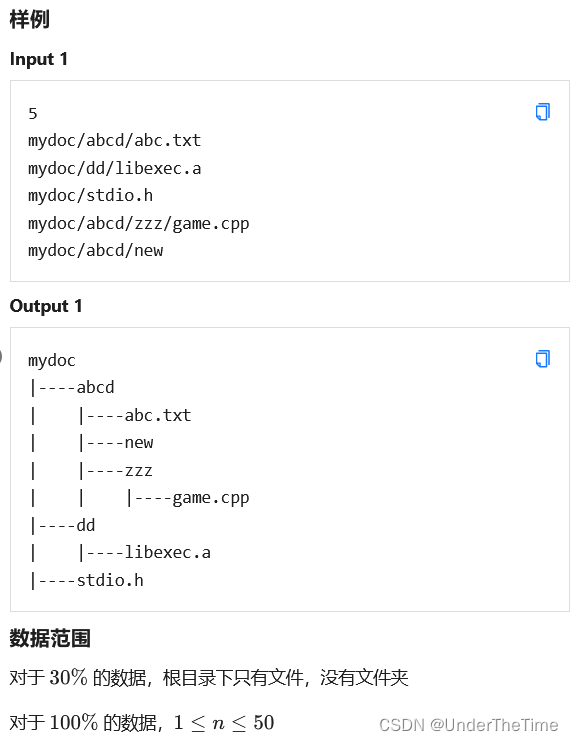
可以说是 C++ 语法题
直接按照题意模拟即可,注意文件(夹)名可能会重复。
巧置挡板
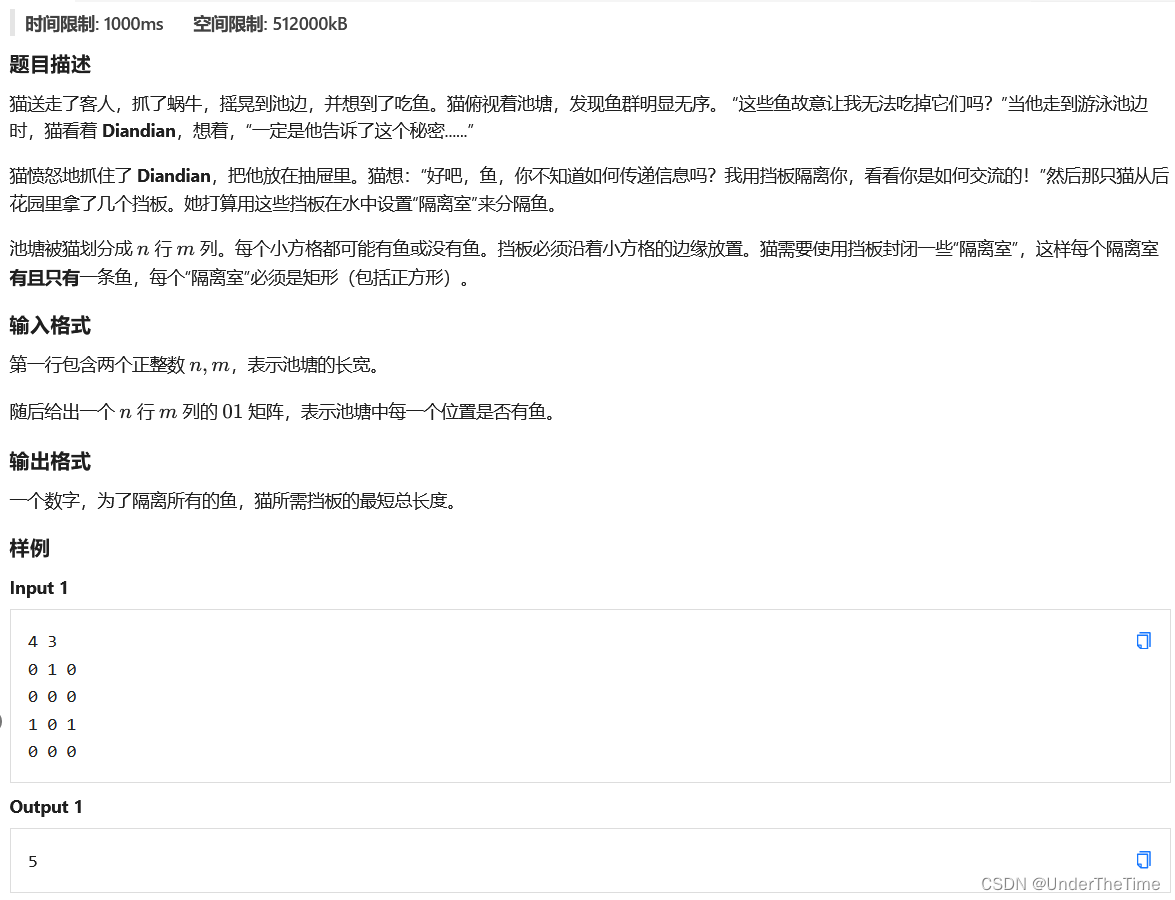

暴搜+剪枝。由于最终每一个矩形中都有且仅有一个 1 1 1,我们不妨在搜索的过程中,每次枚举所有包含某一个 1 1 1 的矩形。状态可以这样设计,我们用一个长度为 n n n 的序列来表示一条从右上到左下的单调分界线(序列中每一个元素表示该行分界线的位置),分界线左边为搜索过的区域,右边为未搜索的区域。这个状态的答案将表示完成右侧区域最少的边数。
为什么是单调的分界线?在任意一种分隔方案中,都一定存在一种矩形放置顺序,使得每次放置之后,分界线仍然是单调的。所以即使是仅考虑单调的分界线状态,也一定可以搜索到所有状态,这样可以简化状态降低复杂度。然而这样复杂度仍然较高。这里给出几种:剪枝的手段:
- 状态可以记忆化,哈希之后用
map存储; - 假设某一行有一个折角(分界线相比上一行发生左移),如果折角的右下方没有一个 1 1 1,则一定会出现空矩形,不合法;
- 枚举当前矩形时, 1 1 1 的个数超过 1 1 1 后可以直接停止,不合法。
这篇关于Day1 省选衔接题 思路总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






