本文主要是介绍Ansys Zemax | 如何将光栅数据从Lumerical导入至OpticStudio(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

附件下载
联系工作人员获取附件
本文介绍了一种使用Ansys Zemax OpticStudio和Lumerical RCWA在整个光学系统中精确仿真1D/2D光栅的静态工作流程。将首先简要介绍方法。然后解释有关如何建立系统的详细信息。
本篇内容将分为上下两部分,上部将首先简要介绍方法工作流,下部将详细阐述示例部分。
介绍
在此工作流程中,设计人员首先在Lumerical FDTD或RCWA中模拟光栅,然后将数据导出到扩展名为json的文件。在OpticStudio中,用户可以导入这些数据,以精确模拟在整个宏观系统中的光栅特性。
示例
本文提供了8个示例供用户参考。第一个示例是用于演示如何建立光栅的简单光栅。接下来的3个示例(2-4)演示了文章Speos Lumerical Sub-wavelength Model中提供的同样的json示例。最后4个示例(5-8)模拟了CMOS背向衍射效应。该系统包含一个手机镜头模型和一个衍射表面,该表面读取一个json文件,用于模拟CMOS传感器上的背向衍射效应。
1. Simple_period_4um-2023R1.zar
在此示例中,请特别检查我们对光源使用的波长是否与.json文件中定义的波长相同。此外,衍射面两侧的折射率也应与.json文件中定义的相同。
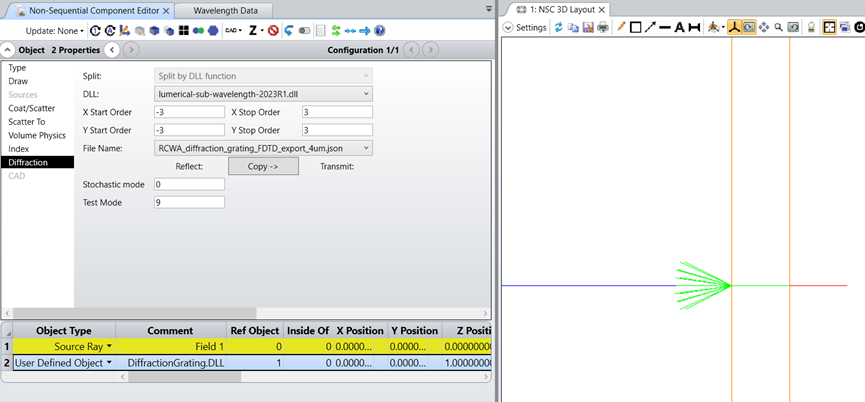
2. triangular_lattice_reflector.zar
在此示例中,json文件加载到了物体2衍射光栅的表面1上。
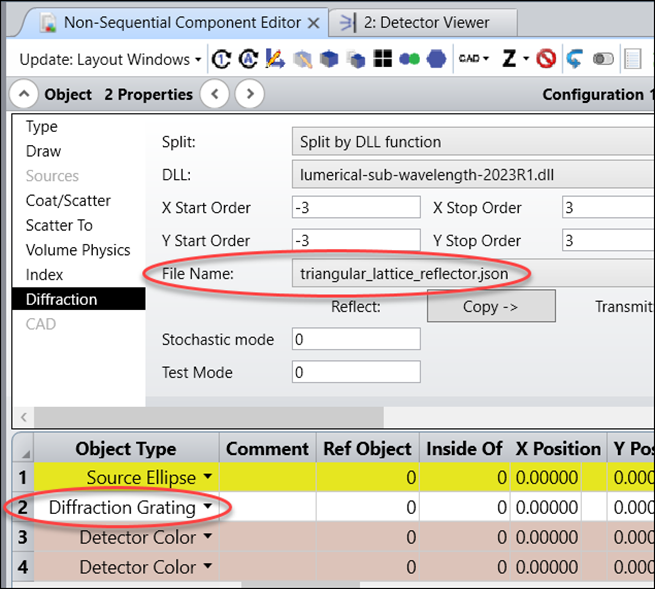
由于我们将光源设置为宽带波长,因此可以看到衍射光栅引起的“彩虹”。
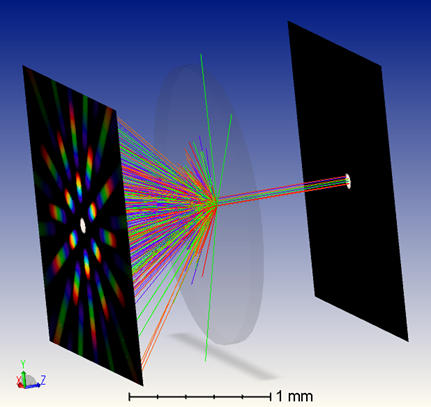
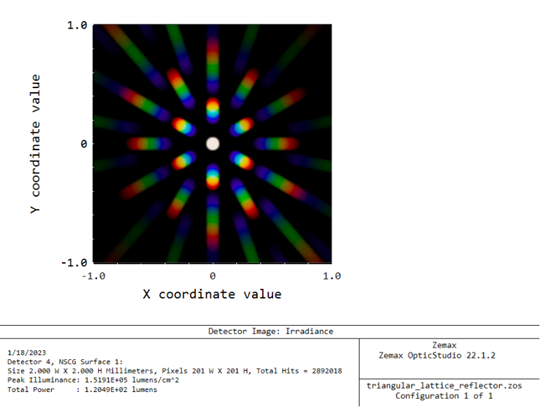
3. grating1D_x.zar
此示例与上一个示例类似。唯一的区别是我们将json文件替换为一维光栅示例。
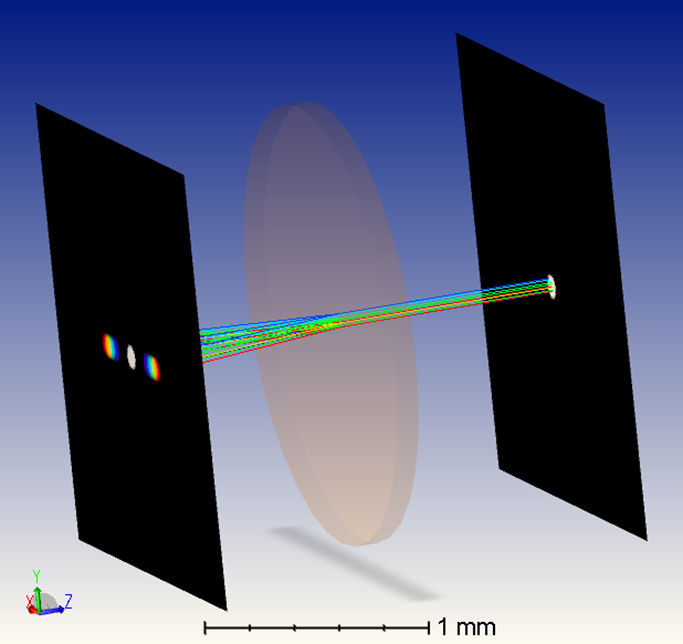
4. FDTD_1D_diffraction_grating_export.zar
在此示例中,我们在玻璃平板上放置了一个圆形光栅。准直光束入射到该光栅上,光栅将光线衍射到一个满足全反射条件的大角度,然后衍射光线在玻璃平板内传播。这展现了关于AR光波导如何工作的非常基本的概念。

值得一提的是此示例的设置。如下所示,物体2和3重叠。根据嵌套规则,重叠部分的表面属性将由编辑器中物体编号较大的物体决定。在此示例中,此重叠部分的表面属性将由物体3的表面1决定,提供衍射功能。
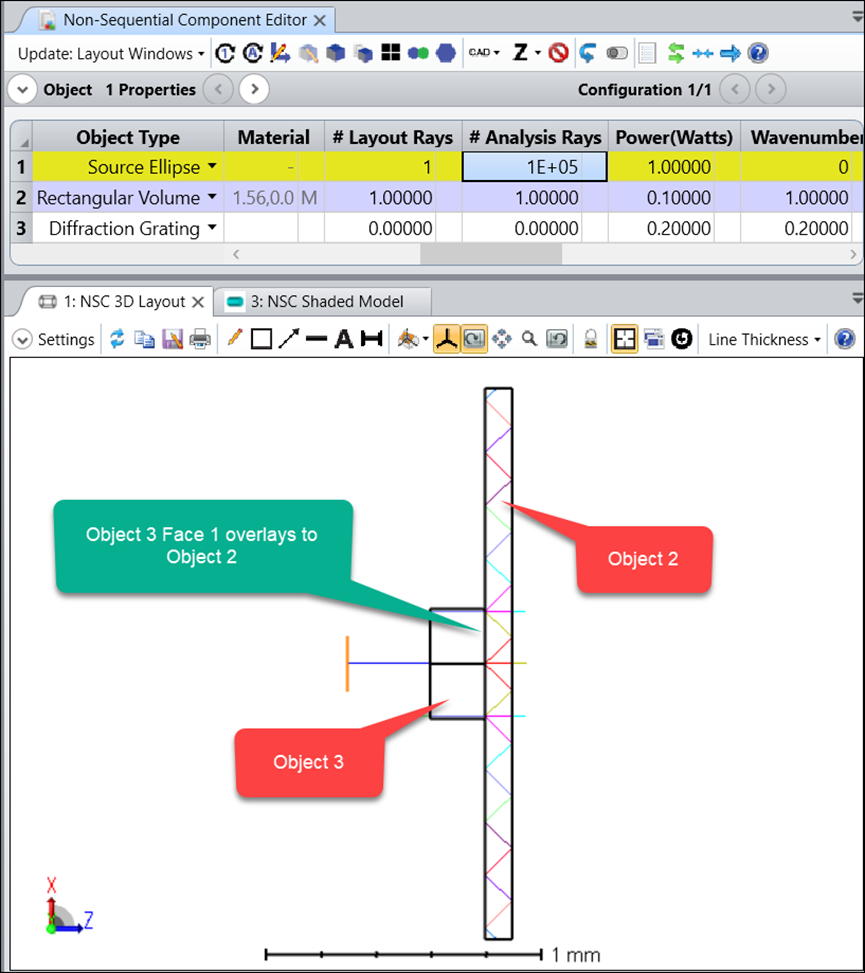
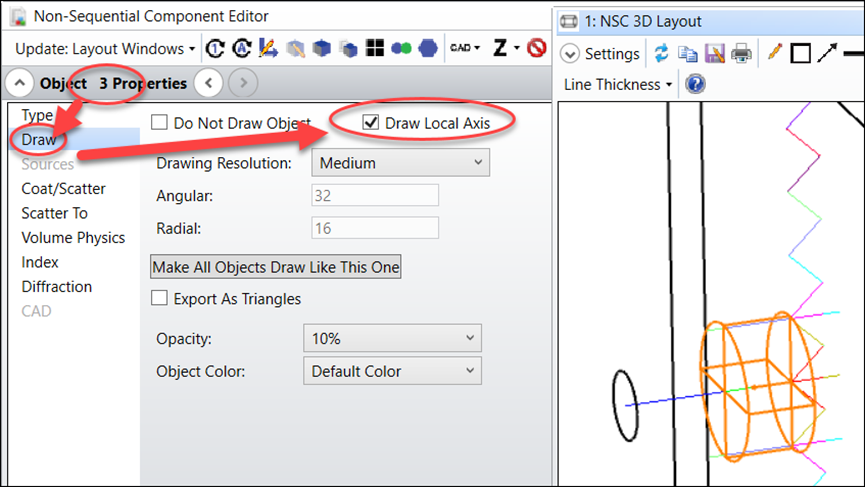
另外值得一提的是,我们之所以这样建立系统,是因为坐标系统。首先,我们可以通过从物体属性中选中“绘制局部坐标轴”选项来查看物体3的局部坐标,如下所示。可以看到,物体3的z轴指向内侧。
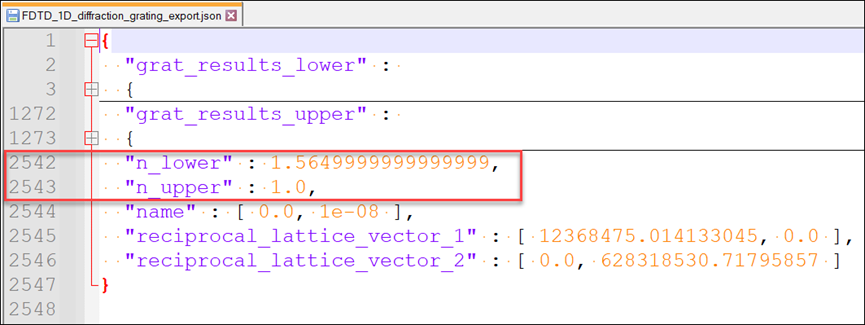
另一方面,如果我们查看json文件,可以看到它假设-z侧(n_lower)的折射率为1.565,+z侧(n_upper)的折射率为 1.0。这就是为什么我们需要将物体3放置在玻璃平板之外,但将其与玻璃平板(物体2)重叠。另请注意,这也是为什么物体3的材料是空白的,意味着折射率为1.0,这确保了+z侧的折射率为1.0。同样地,物体3的-z侧折射率为1.565,来自物体2(玻璃平板)的材料属性。
通过这样做,我们可以确保 .json文件中的折射率条件与OpticStudio中的设置相匹配。请注意,json文件中的数据进一步来自Lumerical中的设置。从根本而言,在将json文件分配到物体时,我们是将Lumerical和OpticStudio中物体之间的坐标系相匹配。
5. Plan_B_period_1um-2023R1.zar
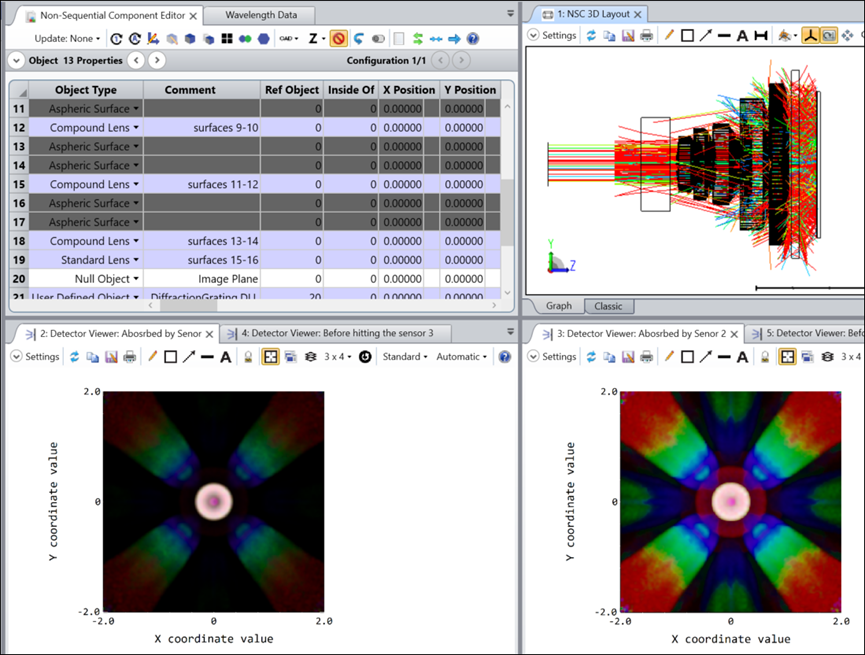
6. Plan_B_period_1um_use_real_IR_coating-2023R1.zar
下图展示了Plan_B_period_1um_use_real_IR_coating-2023R1.zar中的数据。
7. Plan_B_period_4um-2023R1.zar
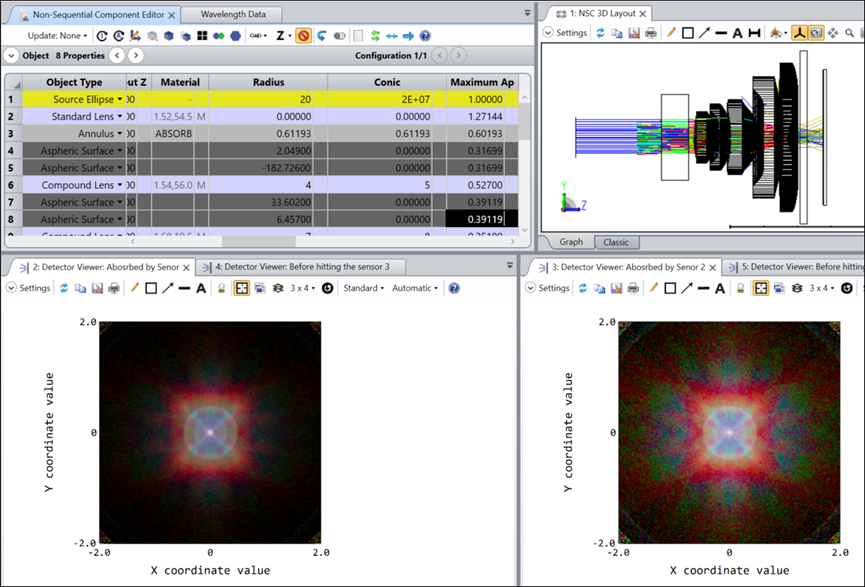
8. Plan_B_period_4um_use_real_IR_coating-2023R1.zar
下图展示了Plan_B_period_4um_use_real_IR_coating-2023R1.zar中的数据。
这篇关于Ansys Zemax | 如何将光栅数据从Lumerical导入至OpticStudio(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






