本文主要是介绍如何试用 Ollama 运行本地模型 Mac M2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先下载 Ollama
https://github.com/ollama/ollama/tree/main
安装完成之后,启动 ollma 对应的模型,这里用的是 qwen:7b
ollama run qwen:7b
命令与模型直接交互

我的机器配置是M2 Pro/ 32G,运行 7b 模型毫无压力,而且推理时是用 GPU 进行运算的,可能就是 Ollama 底层是用 llama C++ 实现的,底层做了性能优化,对 Mac特别友好。
- 纯C/C++实现,没有任何依赖
- Apple Silicon 支持 - 通过ARM NEON、Accelerate和Metal框架进行优化
- 对x86架构支持AVX、AVX2和AVX512
- 支持1.5位、2位、3位、4位、5位、6位和8位整数量化,以加快推理速度并减少内存使用
- 为NVIDIA GPU运行LLMs的自定义CUDA核心(通过HIP支持AMD GPU)
- 支持Vulkan、SYCL和(部分)OpenCL后端
- CPU+GPU混合推理,部分加速超过总VRAM容量的模型
下次再试试lammafile,就是前两天Google 那个女大神说跟比llama.cpp相比,她把 llamafile 的性能提高了 1.3x 到 5x。
API 调用Ollama
stream 参数控制是否是流式输出,非流式的速度会慢一些。
curl http://localhost:11434/api/generate -d ‘{
“model”: “qwen:7b”,
“prompt”: “你好”,
“stream”: true
}’
启动客户端访问本地 Ollama
首先把客户端代码 clone 到本地,这里我用的是 https://librechat.ai/ ,选择挺多的,Ollama github 仓库首页有个列表可以选择。
Clone 仓库
Docker env 配置
根目录下有个配置文件 .env.example,复制一个新的 .env,如果是本地运行,不对外服务,默认配置就可以。
Ollama 配置
配置 Ollama 的相关参数,将librechat.example.yaml复制一个到librechat.yaml,添加 ollama 的相关配置信息。
两个地方要注意修改一下
- /opt/env开始路径要改为本机正确的位置。
- Ollama API 的访问地址。
version: "3.4"# Do not edit this file directly. Use a ‘docker-compose.override.yaml’ file if you can.
# Refer to `docker-compose.override.yaml.example’ for some sample configurations.services:api:container_name: LibreChatports:- "${PORT}:${PORT}"depends_on:- mongodb- rag_apiimage: ghcr.io/danny-avila/librechat-dev:latestrestart: alwaysuser: "${UID}:${GID}"extra_hosts:- "host.docker.internal:host-gateway"environment:- HOST=0.0.0.0- MONGO_URI=mongodb://mongodb:27017/LibreChat- MEILI_HOST=http://meilisearch:7700- RAG_PORT=${RAG_PORT:-8000}- RAG_API_URL=http://rag_api:${RAG_PORT:-8000}volumes:- type: bindsource: /opt/env/docker/ollama/librechat.yamltarget: /app/librechat.yaml- type: bindsource: /opt/env/docker/ollama/.envtarget: /app/.env- /opt/env/docker/ollama/images:/app/client/public/images- /opt/env/docker/ollama/logs:/app/api/logsmongodb:container_name: chat-mongodbimage: mongorestart: alwaysuser: "${UID}:${GID}"volumes:- /opt/env/docker/ollama/data-node:/data/dbcommand: mongod --noauthmeilisearch:container_name: chat-meilisearchimage: getmeili/meilisearch:v1.7.3restart: alwaysuser: "${UID}:${GID}"environment:- MEILI_HOST=http://meilisearch:7700- MEILI_NO_ANALYTICS=truevolumes:- /opt/env/docker/ollama/meili_data_v1.7:/meili_datavectordb:image: ankane/pgvector:latestenvironment:POSTGRES_DB: mydatabasePOSTGRES_USER: myuserPOSTGRES_PASSWORD: mypasswordrestart: alwaysvolumes:- pgdata2:/var/lib/postgresql/datarag_api:image: ghcr.io/danny-avila/librechat-rag-api-dev-lite:latestenvironment:- DB_HOST=vectordb- RAG_PORT=${RAG_PORT:-8000}restart: alwaysdepends_on:- vectordbenv_file:- .envvolumes:pgdata2:
启动 librechat
docker-compose up -d
进入 librechat
浏览器进入http://localhost:3080/,选择 Ollama,模型 qwen:7b,很像 chatgpt。
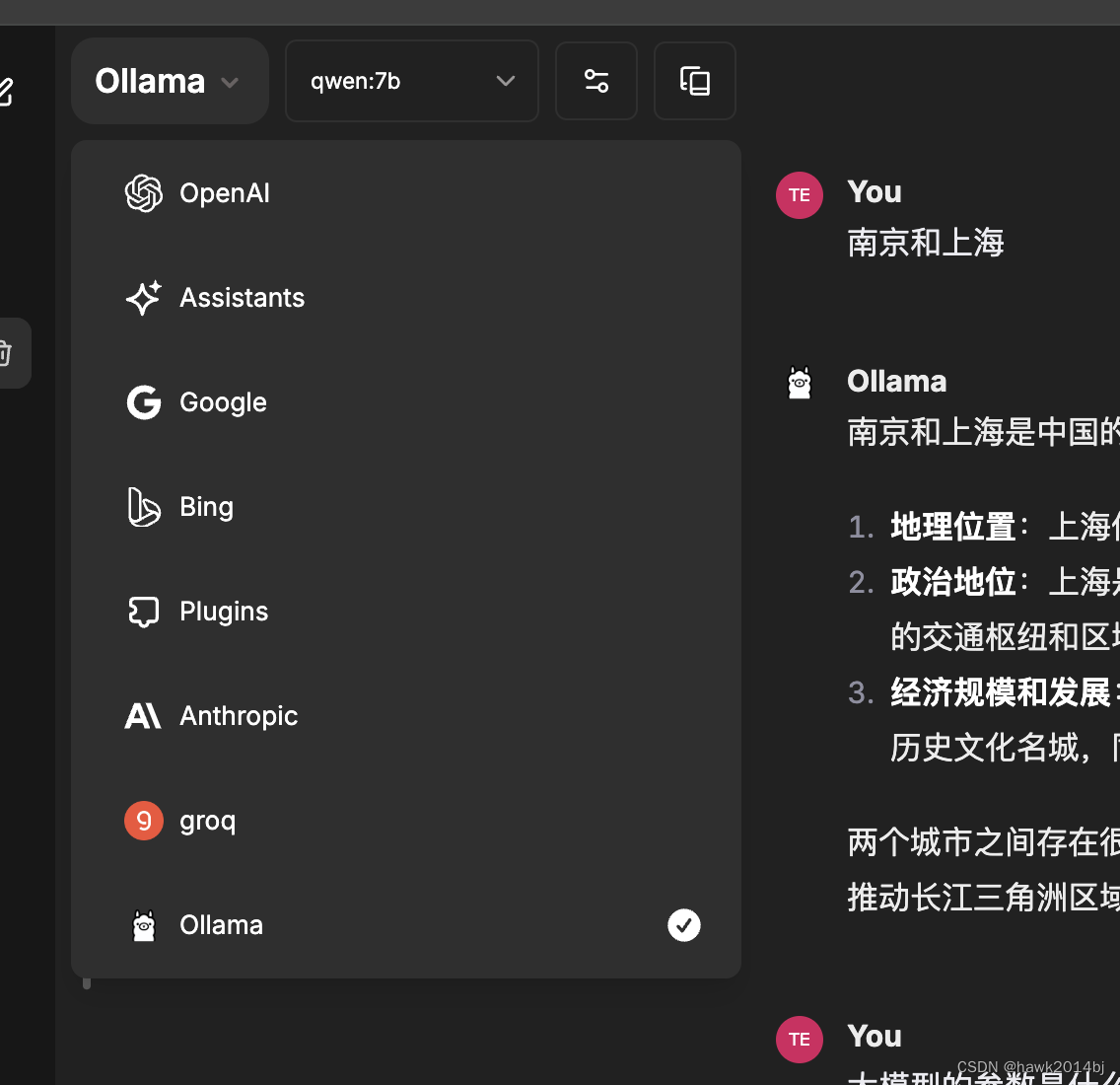
Ollama 搭建完成,可以在本地使用模型了,我机器上可以比较顺畅的运行 qwen:14b。
这篇关于如何试用 Ollama 运行本地模型 Mac M2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






