本文主要是介绍RDF 和 Jena RDF API 的介绍(An Introduction to RDF and the Jena RDF API),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
这篇文章将对资源描述框架RDF和java用于操作RDF的api:jena 进行介绍。本文假设你已经对XML 和 java比较熟悉,适合于那些不太了解RDF,希望快一点实现语义网络的建议的人。
在没有理解RDF数据模型的情况下,过快的实现会导致挫败和失望。但是,如果单独研究数据模型也是枯燥的,而且往往会导致错综复杂的形而上学难题。最好的方法就是学习数据模型和学习如何使用相结合,并行开展。学习一点数据模型就试一试,再多学一点,就再多试一下。数据模型都非常简单,所以不会花费太长时间。
RDF具有XML语法,许多熟悉XML的人会根据该语法来考虑RDF,这其实是错误的。RDF需要根据它的数据模型来理解。RDF数据可以用XML来表示,但是相比理解数据模型,理解这个语法是次要的。
Jena API的实现,包括本教程中使用的所有示例的源代码,可以从这里下载:http://jena.apache.org/download/index.cgi
引言
RDF是描述资源的标准。那么什么是资源?这个问题很深入,仍存在不同的看法。我们可以将资源理解成任何我们可以识别的东西。
在本教程中,我们以人为例,他们使用vCard的RDF表示(vCard Ontology:用于表示人或单位)。RDF最好使用节点图和弧图的形式表示。一个简单的vcard在RDF中的表示如下图:
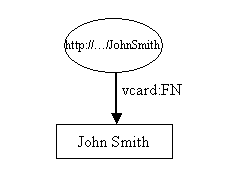
这里的资源是John Smith,表示为椭圆状,并由统一资源标识符URI标识。在这个例子中是:“http://…/JohnSmith”。如果你用自己浏览器去访问这个资源,估计是不会成功的。
资源拥有属性,在我们这个例子中,我们比较关注出现在John Smith’s名片上的属性。图中只有一个属性,就是他的全名John Smith。属性用一个圆弧来表示,圆弧上标有属性的名称。属性的名称也是一个URI,但是由于URI的名称相当长,图中就用了XML的形式显示。“:”前面成为名称空间前缀,表示名称空间。后面的成为本地名称,表示在该名称空间中的名称。属性一般都是以RDF XML的形式表示在图和文本中。但严格来说,属性还是以URI标识的。当浏览器访问某个属性的时候,不需要将其URI解析为任何内容。
每一个属性都有一个值,在这个例子中,这个值是文本,我们可以将它看做是字符串。文本表示成矩形状。
Jena是一个java API,可以用来创建和操作这样的RDF图。Jena有对象类来表示图、资源、属性和值。表示资源、属性和值的接口分别称为Resource、Propety和Literal。在Jena中,一个图被成为模型,由Model接口表示。
创建图/模型的简单代码为:
// some definitions
static String personURI = "http://somewhere/JohnSmith";
static String fullName = "John Smith";// create an empty Model
Model model = ModelFactory.createDefaultModel();// create the resource
Resource johnSmith = model.createResource(personURI);// add the propertyjohnSmith.addProperty(VCARD.FN, fullName);
在定义了常量之后,利用createDefaultModel()建立了一个memory-based模型,Jena中包含了模型接口的其他实现。比如:要使用一个关系数据库,也可以通过ModelFactory来建立。
这个例子的代码在Jena发行版的/src-examples/jena/examples/rdf/Tutorial01.java目录下。
以上创建资源,再添加属性更简洁的写法如下:
Resource johnSmith =model.createResource(personURI).addProperty(VCARD.FN, fullName);
接下来,我们向vcard添加更多细节,以此探索RDF和Jena的更多特性。
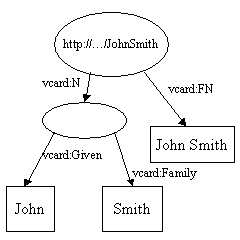
在第一个例子中,属性值是一个文本。RDF属性还可以将其他资源作为其属性值。下面这个例子展示了如何使用RDF的一种通用技术来表示John Smith名字的不同部分。

上图中,我们添加了一个新的属性:vcard:N,用来表示John Smith这个名字的结构。这个模型有几个有趣的地方,我们注意到vcard:N将资源作为它的属性值。而且这个椭圆内是没有内容的,这就是一个空节点。
上面这个例子的Jena代码也很简单,如下:
// some definitions
String personURI = "http://somewhere/JohnSmith";
String givenName = "John";
String familyName = "Smith";
String fullName = givenName + " " + familyName;// create an empty Model
Model model = ModelFactory.createDefaultModel();// create the resource
// and add the properties cascading style
Resource johnSmith= model.createResource(personURI).addProperty(VCARD.FN, fullName).addProperty(VCARD.N,model.createResource().addProperty(VCARD.Given, givenName).addProperty(VCARD.Family, familyName));
这个代码在Tutorial02中可以找到。
语句(Statements)
RDF模型中的每一个箭头都叫做一个语句,每一个语句维护了资源的一个事实(a fact)。一个语句包括三个部分:
- 主语subject
- 谓语predicate
- 宾语object
一个语句有时也成为一个三元组triple,因为它是由三部分组成。
一个RDF模型可以用一系列语句的集合来表示,addProperty表示向模型中加了一个语句。Jena模型接口定义了一个listStatements()方法,这个方法可以返回一个StmtIterator,就是java迭代器的子类型,可迭代模型中所有语句。StmtIterator有一个方法是nextStatement()可以返回迭代器中的下一个语句。(The same one that next() would deliver, already cast to Statement)。Statement接口提供了对于语句中的主语谓语和宾语的访问方法。
现在我们使用这些接口去扩展Tutorial02,以此来列出所有的语句,并且打印出来,完整的代码在Tutorial03中。
// list the statements in the Model
StmtIterator iter = model.listStatements();// print out the predicate, subject and object of each statement
while (iter.hasNext()) {Statement stmt = iter.nextStatement(); // get next statementResource subject = stmt.getSubject(); // get the subjectProperty predicate = stmt.getPredicate(); // get the predicateRDFNode object = stmt.getObject(); // get the objectSystem.out.print(subject.toString());System.out.print(" " + predicate.toString() + " ");if (object instanceof Resource) {System.out.print(object.toString());} else {// object is a literalSystem.out.print(" \"" + object.toString() + "\"");}System.out.println(" .");
}
因为语句的宾语可以为文本或者资源,所以getObject()方法返回的类型是RDFNode,这种类型是Resource和Literal的公共超类。代码中使用instanceof来判断其类型并对它进行适当的处理。
运行后,这个程序的结果为:
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#N 413f6415-c3b0-4259-b74d-4bd6e757eb60 .
413f6415-c3b0-4259-b74d-4bd6e757eb60 http://www.w3.org/2001/vcard-rdf/3.0#Family "Smith" .
413f6415-c3b0-4259-b74d-4bd6e757eb60 http://www.w3.org/2001/vcard-rdf/3.0#Given "John" .
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#FN "John Smith" .
现在你应该知道为什么画模型会更加清晰了。如果你看的仔细,你会发现每一行都包含了语句的三个部分,即主语、谓语和宾语。在这个模型中,共有四个箭头,所有四个语句,“14df86:ecc3dee17b:-7fff”是Jena内部的标识符,它不是一个URI,它只是Jena实现使用的一个内部标签。
W3C RDFCore工作组定义了一个列斯的简单符号,称为N-triples. 意思是三元组的符号。在下一个部分中,我们将看到Jena内置了一个N-triples编写器。
写RDF(Writing RDF)
Jena中有将RDF读写为XML的方法,这样的方法可以将RDF模型保存为一个文件,之后再读出来。
Tutorial03创建了一个模型,然后以三元组的形式写出来。Tutorial04修改了Tutorial03的内容,将XML格式的RDF模型写入标准输出流。代码依然很简单,model.write可以接受OutputStream的参数。
// now write the model in XML form to a file
model.write(System.out);
输出是这样的:
<rdf:RDFxmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'><rdf:Description rdf:about='http://somewhere/JohnSmith'><vcard:FN>John Smith</vcard:FN><vcard:N rdf:nodeID="A0"/></rdf:Description><rdf:Description rdf:nodeID="A0"><vcard:Given>John</vcard:Given><vcard:Family>Smith</vcard:Family></rdf:Description>
</rdf:RDF>
RDF说明书中详细说明了怎样将RDF表示为XML,RDF XML的语法是很复杂的。读者可以参考RDFCore WG正在开发的初级读本,以获得更详细的介绍。我们还是先来快速了解一下如何解释上述内容。
RDF通常嵌在<rdf:RDF>元素中,如果有其他标识可以知道一些XML是RDF,那么这个元素可以是其他标识,总之这样的元素一定是存在的。在上面的代码中,RDF元素定义了两个命名空间。紧接着是一个<rdf:Description>的元素,表示资源的URI是http://somewhere/JohnSmith。如果rdf:about的属性缺失,那么这个元素就代表一个空节点。
<vcard:FN>元素表示资源的一个属性,属性名称是vcard命名空间中的FN。RDF通过连接命名空间前缀的URI引用vcard和明本地命名部门FN,将此转换为URI引用。vcard FN=http://www.w3.org/2001/vcard-rdf/3.0#FN,都表示John Smith。
<vcard:N>元素表示的是一个资源。在这个例子中,资源被表示成一个相对的URI引用。RDF通过连接基本URI和现在的路径,将它转换为一个绝对URI引用。
这个RDF XML中有一个错误,它并不是完全代表我们创建的模型。模型中的空节点已经给了一个URI引用,它就不再是空的。其实,RDF/XML语法并不能表示所有的模型,例如:它不能表示包含两个语句的空节点。
Jena有一个可扩展的接口,可以供新手方便的写入RDF不同的序列化语言。上例调用了标准的“dump”写入器。Jena也包括一个复杂的RDF/XML写入器,可以通过指定write()方法调用的另一个参数来调用:
// now write the model in XML form to a file
model.write(System.out, "RDF/XML-ABBREV");
这个写入器,称为PrettyWriter,用剪短的语言就可以写出复杂的模型,并且可以表示出空节点。但是它并不适合很大的模型,因为在处理大模型的时候性能是不能接受的。如果想要写大文件,并且需要保存空节点,需要写成N-Triples的形式:
// now write the model in N-TRIPLES form to a file
model.write(System.out, "N-TRIPLES");
这可以得到类似Tutorial03的结输出,它符合N-Triples规范。
读RDF(Reading RDF)
Tutorial05演示了如何将RDF XML格式记录的语句读入模型。我们也提供了一个小的RDF/XML形式的vcard数据库(有链接)。下面的代码可以读出并写出这些数据。注意:运行下面的代码,输入文件必须在当前目录下。
// create an empty modelModel model = ModelFactory.createDefaultModel();// use the FileManager to find the input fileInputStream in = FileManager.get().open( inputFileName );
if (in == null) {throw new IllegalArgumentException("File: " + inputFileName + " not found");
}// read the RDF/XML file
model.read(in, null);// write it to standard out
model.write(System.out);
read()方法的第二个参数时为了解析相对URI的URI,但因为我们的测试文件中没有相对URI,所以,它是空的。运行后,Tutorial05会产生XML形式的输出如下:
<rdf:RDFxmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'><rdf:Description rdf:nodeID="A0"><vcard:Family>Smith</vcard:Family><vcard:Given>John</vcard:Given></rdf:Description><rdf:Description rdf:about='http://somewhere/JohnSmith/'><vcard:FN>John Smith</vcard:FN><vcard:N rdf:nodeID="A0"/></rdf:Description><rdf:Description rdf:about='http://somewhere/SarahJones/'><vcard:FN>Sarah Jones</vcard:FN><vcard:N rdf:nodeID="A1"/></rdf:Description><rdf:Description rdf:about='http://somewhere/MattJones/'><vcard:FN>Matt Jones</vcard:FN><vcard:N rdf:nodeID="A2"/></rdf:Description><rdf:Description rdf:nodeID="A3"><vcard:Family>Smith</vcard:Family><vcard:Given>Rebecca</vcard:Given></rdf:Description><rdf:Description rdf:nodeID="A1"><vcard:Family>Jones</vcard:Family><vcard:Given>Sarah</vcard:Given></rdf:Description><rdf:Description rdf:nodeID="A2"><vcard:Family>Jones</vcard:Family><vcard:Given>Matthew</vcard:Given></rdf:Description><rdf:Description rdf:about='http://somewhere/RebeccaSmith/'><vcard:FN>Becky Smith</vcard:FN><vcard:N rdf:nodeID="A3"/></rdf:Description>
</rdf:RDF>
控制前缀(Controlling Prefixes)
明确的前缀定义
在之前的章节中,我们看到输出的XML声明了一个命名空间的前缀vcard,并用它来简写URI。但是RDF只使用全的URI,而不使用这种简单的形式。Jena提供了一种使用前缀控制输出上使用的命名空间的方法,这里有一个简单的例子:
Model m = ModelFactory.createDefaultModel();String nsA = "http://somewhere/else#";String nsB = "http://nowhere/else#";Resource root = m.createResource( nsA + "root" );Property P = m.createProperty( nsA + "P" );Property Q = m.createProperty( nsB + "Q" );Resource x = m.createResource( nsA + "x" );Resource y = m.createResource( nsA + "y" );Resource z = m.createResource( nsA + "z" );m.add( root, P, x ).add( root, P, y ).add( y, Q, z );System.out.println( "# -- no special prefixes defined" );m.write( System.out );System.out.println( "# -- nsA defined" );m.setNsPrefix( "nsA", nsA );m.write( System.out );System.out.println( "# -- nsA and cat defined" );m.setNsPrefix( "cat", nsB );m.write( System.out );
这段代码的输出是三个RDF/XML的片段,代表三个不同的前缀匹配。第一种是默认的,没有前缀的定义:
# -- no special prefixes defined<rdf:RDFxmlns:j.0="http://nowhere/else#"xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:j.1="http://somewhere/else#" ><rdf:Description rdf:about="http://somewhere/else#root"><j.1:P rdf:resource="http://somewhere/else#x"/><j.1:P rdf:resource="http://somewhere/else#y"/></rdf:Description><rdf:Description rdf:about="http://somewhere/else#y"><j.0:Q rdf:resource="http://somewhere/else#z"/></rdf:Description>
</rdf:RDF>
我们看到rdf命名空间被自动声明,因为它是<rdf:RDF>和<rdf:resource>标志所必须的。XML命名空间的声明还需要用到P/Q这两个属性,但是这个例子中它们的前缀没有引入模型,所以它们得到了虚构的命名空间名称:j.0和j.1。
setNsPrefix(String prefix, String URI)声明了URI可以通过前缀简化。Jena要求前缀是合法的XML命名空间名称,URI以非名称字符结束。RDF/XML编写器将把这些前缀声明转换成XML名称空间声明,并在其输出中使用它们:
# -- nsA defined<rdf:RDFxmlns:j.0="http://nowhere/else#"xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:nsA="http://somewhere/else#" ><rdf:Description rdf:about="http://somewhere/else#root"><nsA:P rdf:resource="http://somewhere/else#x"/><nsA:P rdf:resource="http://somewhere/else#y"/></rdf:Description><rdf:Description rdf:about="http://somewhere/else#y"><j.0:Q rdf:resource="http://somewhere/else#z"/></rdf:Description>
</rdf:RDF>
另一个命名空间仍然获得构造名称,但是现在在属性标记中使用nsA名称。前缀名称不需要与Jena代码中的变量有任何关系。
# -- nsA and cat defined<rdf:RDFxmlns:cat="http://nowhere/else#"xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:nsA="http://somewhere/else#" ><rdf:Description rdf:about="http://somewhere/else#root"><nsA:P rdf:resource="http://somewhere/else#x"/><nsA:P rdf:resource="http://somewhere/else#y"/></rdf:Description><rdf:Description rdf:about="http://somewhere/else#y"><cat:Q rdf:resource="http://somewhere/else#z"/></rdf:Description>
</rdf:RDF>
这两个前缀都用于输出,不需要生成前缀。
不明确的前缀定义
除了调用setNsPrefix提供的前缀声明外,Jena还将记住model.read()输入中使用的前。将之前的例子中产生的输出粘贴到某个文件中,并使用file:/tmp/fragment.rdf 的路径,运行代码:
Model m2 = ModelFactory.createDefaultModel();
m2.read( "file:/tmp/fragment.rdf" );
m2.write( System.out );
可以看到,输入中的前缀保存在输出中,且所有的前缀都会列出来,即使没有用到。如果你不想让一个前缀出现在输出中,那么久使用removeNsPrefix(String prefix)来移除它。由于N-Triples形式中没有任何URI的简短表示形式,所以它不关注输出的前缀也不提供输入的前缀。Jena也支持N3表示,它有简短的前缀名称,并在输入中记录在输出中使用。Jena对模型中的前缀映射进行了 进一步操作,例如:提取现有映射的java映射,或者一次添加整个映射组;有关前缀映射的详细信息,请参阅文档。
Jena RDF包
Jena是一个用于语义网络应用的java API。应用程序开发人员最关键的RDF包是org.apache.jena.rdf.model。API是根据接口定义的,因此应用程序代码可以在不更改的情况下使用不同的实现。这个包中包含表示模型,资源,属性,文本,语句和其他所有RDF中的关键概念的接口,ModelFactory创建模型。所以,应用程序代码独立于实现,最好尽可能使用接口,而不是特定的类实现。
org.apache.jena.tutorial包中包含了本教程中使用的所有例子的源代码。
org.apache.jena…impl包中包含了许多已经实现的类,这些类对于很多应用来说都是通用的。例如:包中定义了ResourceImpl,PropertyImpl和LiteralImpl类,这些都可以直接使用或者子类化。应用程序其实很少直接使用这些类。比如:相比于创建一个ResourceImpl的实例,更好的方法是无论使用什么模型都用createResource方法。这样,如果模型实现使用了资源的优化实现,那么就不需要再这两种类型之间进行转换。
导航模型(Navigating a Model)
到目前为止,这个教程主要讨论了创建和读写RDF模型。现在是处理访问模型中保存的信息的时候了。
给定一个资源的URI,可以使用Model.getResource(String uri)方法检索模型中的资源对象。这个方法会返回一个Resource对象,如果模型中存在,则返回资源,不存在话,创建一个新的资源对象返回。例如:要从Tutorial05的文件中读取的模型中检索John Smith这个资源:
// retrieve the John Smith vcard resource from the model
Resource vcard = model.getResource(johnSmithURI);
Resource接口定义了一些方法用来获取资源的属性。Resource.getProperty(Property p)方法可以获取资源的属性,此方法不遵循通常的Java访问器约定,因为返回的对象类型是语句,而不是单个的属性。返回整个语句允许应用程序使用返回语句对象的访问器方法访问属性的值。例如:要检索具有属性vcard:N的资源。
// retrieve the value of the N property
Resource name = (Resource) vcard.getProperty(VCARD.N).getObject();
通常,语句的对象是一个资源或者文本,但应用程序知道返回值必须是一个资源,所以进行了强制转换。Jena尝试做的一件事情是提供特定于类型的方法,这样应用程序就不必强制转换,并且可以在编译时进行类型检查。上面的代码可以写成:
// retrieve the value of the N property
Resource name = vcard.getProperty(VCARD.N).getResource();
同样的,如果要返回一个文本值:
// retrieve the given name property
String fullName = vcard.getProperty(VCARD.FN).getString();
在这个例子中,vcard资源只有一个vcard:FN和一个vcard:N属性。其实,RDF允许一个资源有多个同样的属性,比如:Adam可能有不止一个的昵称:
// add two nickname properties to vcard
vcard.addProperty(VCARD.NICKNAME, "Smithy").addProperty(VCARD.NICKNAME, "Adman");
前面已经提到,Jena将RDF模型表示成一系列语句的集合,所以在模型中添加一个包含主语、谓语和宾语的语句不会有任何效果。Jena没有定义模型中存在两个昵称的情况如何返回。调用vcard.getProperty(VCARD.NICKNAME)方法的返回是不确定的。Jena会返回其中一个值,但是不保证两次调用返回的值是一样的。
如果一个属性出现多次,那么Resource.listProperty(Property p)方法可以用来列出所有的属性。这个方法返回一个迭代器,迭代器返回语句类型的对象。我们可以列出昵称:
// set up the output
System.out.println("The nicknames of \""+ fullName + "\" are:");
// list the nicknames
StmtIterator iter = vcard.listProperties(VCARD.NICKNAME);
while (iter.hasNext()) {System.out.println(" " + iter.nextStatement().getObject().toString());
}
这个代码可以在Tutorial06中找到,语句迭代器iter包含所有的主语为vcard,谓语为VCARD:NICKNAME的语句,所以循环执行nextStatement()可以访问到所有的语句,获取对象字段,并将其转换为字符串。代码执行的输出为:
The nicknames of "John Smith" are:SmithyAdman
可以使用listProperties()方法列出资源的所有属性,而无需参数。
模型的查询
上一节讨论了从已知URI的资源中导航模型的情况,这一节讨论搜索模型。核心的Jena API只支持有限的查询原语,而SPARQL提供了更强大的查询功能。
Model.listStatements()方法可以列出模型中所有语句,这是一搜索模型的暴力方法,在大兴的模型上,不推荐使用这种方法。Model.listSubjects()具有类似的功能,但是返回的是具有属性的所有资源的迭代器,即某些语句的主语。
Model.listSubjectsWithProperty(Property p, RDFNode o)方法会返回所有拥有属性p和o的资源。假设只有vcard这个资源有vcard:FN这个属性,并且在我们的数据中,所有这样的资源都具有这样的属性,那么我们可以找到所有这样的vcard:
// list vcards
ResIterator iter = model.listSubjectsWithProperty(VCARD.FN);
while (iter.hasNext()) {Resource r = iter.nextResource();...
}
所有这些查询方法都是建立在基本查询方法model.listStatements(Selector s)之上的。该方法返回一个迭代器,包含通过选择器选择的所有语句。selector接口是可以扩展的,但是目前它只有一个实现,就是org.apache.jena.rdf.model包中的SimpleSelector类。使用这个类是Jena中少有的需要使用特定类而不是接口的情况。这个类构造器有三个参数:
Selector selector = new SimpleSelector(subject, predicate, object)
这个选择器会选出所有主语、谓语、宾语都匹配的语句。如果在这三个参数的位置上是空的,它就不会进行匹配,否则就会匹配对应的相同资源或文本。
Selector selector = new SimpleSelector(null, null, null);
上面代码会选出模型中的所有语句。
Selector selector = new SimpleSelector(null, VCARD.FN, null);
上面代码会选出谓语为VCARD.FN的语句,作为一种特殊的速记法可以表示为:
listStatements(S, P, O)
等价于:
listStatements(new SimpleSelector(S, P, O))
下面代码可以列出数据库中所有vcard的全名,源码可以在Tutorial07中找到。
// select all the resources with a VCARD.FN property
ResIterator iter = model.listSubjectsWithProperty(VCARD.FN);
if (iter.hasNext()) {System.out.println("The database contains vcards for:");while (iter.hasNext()) {System.out.println(" " + iter.nextResource().getProperty(VCARD.FN).getString());}
} else {System.out.println("No vcards were found in the database");
}
输出如下:
The database contains vcards for:Sarah JonesJohn SmithMatt JonesBecky Smith
你的下一个练习是修改上面的代码,利用SimpleSelector代替listSubjectsWithProperty。下面来看一下如何更好地操作已选的语句。SimpleSelector可以被子类化,对其选择方法进行修改,进行进一步筛选:
// select all the resources with a VCARD.FN property
// whose value ends with "Smith"
StmtIterator iter = model.listStatements(new SimpleSelector(null, VCARD.FN, (RDFNode) null) {public boolean selects(Statement s){return s.getString().endsWith("Smith");}});
这个实例代码使用了一种简介的Java技术,即在创建类的实例时内联覆盖方法定义,这里的selects()方法保证了全名以“Smith”结尾。需要注意的是,主语、谓语和宾语的筛选在调用selects()方法之前进行,所以selects()只是用来匹配已选择的语句。
上面代码可以在Tutorial08中找到,输出如下:
The database contains vcards for:John SmithBecky Smith
这里,对SimpleSelector做一些解释:
StmtIterator iter =model.listStatements(new SimpleSelector(subject, predicate, object)
其实可以想成这样的过程:
// do all filtering in the selects method
StmtIterator iter = model.listStatements(newSimpleSelector(null, null, (RDFNode) null) {public boolean selects(Statement s) {return (subject == null || s.getSubject().equals(subject))&& (predicate == null || s.getPredicate().equals(predicate))&& (object == null || s.getObject().equals(object)) ;}}});
虽然它们在功能上是相同的,第一种形式允许维护索引以提高性能,而第二种形式是列出模型中的所有语句,并分别测试每一个语句。可以尝试在大规模模型上测试一下,不过在这之前最好先准备一杯咖啡,哈哈哈。
模型上的操作(Operations on Models)
Jena提供了三个操作来操作整个模型,它们和集合操作类似,是并集(union),交集(intersection)和差集(difference)。
两个模型之间的并集操作是表示两个模型的语句集的并集。这是RDF设计支持的关键操作之一,它可以将来自不同数据源的数据进行合并。考虑下面的两种模型:
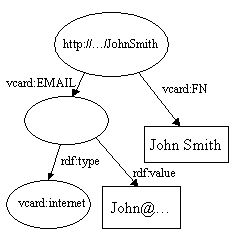
当它们合并时,两个http://…JohnSmith被合并成一个,vcard:N副本被删除,形成下面的合并结果:

合并操作的代码在Tutorial09中:
// read the RDF/XML files
model1.read(new InputStreamReader(in1), "");
model2.read(new InputStreamReader(in2), "");// merge the Models
Model model = model1.union(model2);// print the Model as RDF/XML
model.write(system.out, "RDF/XML-ABBREV");
运行后,输出如下:
<rdf:RDFxmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#"><rdf:Description rdf:about="http://somewhere/JohnSmith/"><vcard:EMAIL><vcard:internet><rdf:value>John@somewhere.com</rdf:value></vcard:internet></vcard:EMAIL><vcard:N rdf:parseType="Resource"><vcard:Given>John</vcard:Given><vcard:Family>Smith</vcard:Family></vcard:N><vcard:FN>John Smith</vcard:FN></rdf:Description>
</rdf:RDF>
即使你不了解RDF/XML的语法,也应该可以看出模型已经按照预期的那样进行了合并。集合的交集和差集也是类似的方法进行计算,模型中的方法分别为:.intersection(Model), .difference(Model),可以查看差集和交集的java文档获取更多信息。
容器(Containers)
RDF定义了一种特殊类型的资源来表示事物的集合,这些资源被称为容器。容器中的内容可以是文本或者资源。有三种类型的容器:
- BAG:无需集合
- ALT:无需集合,用来表示替代方案
- SEQ:有序集合
一个容器被表示成一个资源,资源会有一个属性rdf:type用来表示是哪种类型的容器。容器中的第一个成员是容器的rdf:_1属性值,第二个成员是rdf:_2属性值等,rdf:_nnn属性称为序号属性。
例如:一个包含Smith的vcards的简单的BAG模型可能是这样的:

BAG成员中的属性被表示成rdf:_1,rdf:_2,但是它们的顺序是不重要的。即:如果交换rdf:_1和rdf:_2,这个模型的结果是不变的。
ALT的目的是代表替代方案,例如:假设资源表示软件产品。它可能具有一个属性来指示从哪里获取它。该属性值可能是一个集合,其中包含可以下载该资源的所有站点。所以,ALT除rdf:_1属性之外,是无序的。rdf:_1表示的是默认的选择。
虽然容器可以使用资源和属性的基本机制来处理,但是Jena还是有显示的接口和实现类来处理它们。让一个对象来操作容器,同时使用低级方法来修改容器的状态,这不是一个好主意。
Tutorial08中创建BAG:
// create a bag
Bag smiths = model.createBag();// select all the resources with a VCARD.FN property
// whose value ends with "Smith"
StmtIterator iter = model.listStatements(new SimpleSelector(null, VCARD.FN, (RDFNode) null) {public boolean selects(Statement s) {return s.getString().endsWith("Smith");}});
// add the Smith's to the bag
while (iter.hasNext()) {smiths.add(iter.nextStatement().getSubject());
}
如果我们写出这个模型,它包含的内容应该类似下面的表示:
<rdf:RDFxmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'>
...<rdf:Description rdf:nodeID="A3"><rdf:type rdf:resource='http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag'/><rdf:_1 rdf:resource='http://somewhere/JohnSmith/'/><rdf:_2 rdf:resource='http://somewhere/RebeccaSmith/'/></rdf:Description>
</rdf:RDF>
上面这个表示BAG资源。
容器接口提供了一个列出容器中所有内容的迭代器。
// print out the members of the bag
NodeIterator iter2 = smiths.iterator();
if (iter2.hasNext()) {System.out.println("The bag contains:");while (iter2.hasNext()) {System.out.println(" " +((Resource) iter2.next()).getProperty(VCARD.FN).getString());}
} else {System.out.println("The bag is empty");
}
输出如下:
The bag contains:John SmithBecky Smith
代码可以在Tutorial10中找到,它将上面的片段粘合在一起形成一个完整的实例。
Jena类提供了操作容器的方法,包括:新增,插入,删除操作。Jena容器类目前确保使用的序号属性列表从rdf:_1开始,并且是连续的。RDFCore WG放宽了这个限制,允许容器的部分表示。因此,Jena可能也会在将来改变。
这篇关于RDF 和 Jena RDF API 的介绍(An Introduction to RDF and the Jena RDF API)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







