本文主要是介绍植物糖基转移酶数据库-23年-地表最强系列-文献精读-6,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pUGTdb: A comprehensive database of plant UDP-dependent glycosyltransferases
pUGTdb:植物UDP依赖糖基转移酶的全面数据库
一篇关于植物糖基转移数据库的综述,地表最强,总结的最全面的版本之一,各位看官有推荐请留言评论区~
植物UDP依赖糖基转移酶(UGTs)属于碳水化合物活性酶糖基转移酶1家族(Louveau和Osbourn,2019),不仅在适应各种环境中发挥重要作用(Cai等,2020;Pastorczyk-Szlenkier和Bednarek,2021),还赋予植物天然产物极大的药用和生态学意义(Margolin等,2020)。近年来,越来越多的植物UGTs已被确定为参与许多生物活性化合物的生物合成,例如人参皂苷(Wei等,2015)、短葶黄芩素(Liu等,2018)和山桃苷(Xu等,2022)。然而,植物基因组中编码的大多数UGTs仍然待表征。我们构建了一个全面的植物UGT数据库(pUGTdb,http://pugtdb.biodesign.ac.cn/),并研究了已表征的UGTs与底物和糖供体的相互作用机制。我们还构建了一个用于未知UGT的虚拟筛选和糖供体预测的网络工具。
基因注释和数据库构建
为了从国家生物技术信息中心(NCBI)基因组数据库中获取未注释基因组中的UGTs,我们开发了一个快速注释流程,命名为GMind(图1A)(补充方法1–3)。简要地说,我们首先使用NCBI数据库中所有已注释植物UGTs作为查询进行blast,以获取植物基因组中的潜在UGTs的基因组区域;其次,我们使用多种基因注释方法独立地对提取的基因组区域进行de novo注释;第三,我们使用HMMER过滤和准确度评分对已注释的UGTs进行评估(补充方法4和5);最后,我们结合多种方法的结果,并将最佳候选人定义为UGTs。与NCBI基因组数据库中注释的UGTs相比(补充方法6),我们注释了额外的28.5%的UGTs(22.5%的完整UGTs)(补充图1)。仅有1%的NCBI注释UGTs由于极长的内含子而被GMind遗漏(补充表1;补充图2)。总共,GMind从574个未注释的植物基因组中注释了110,702个UGTs。总之,通过整合转录组注释(补充方法7)、GMind注释、NCBI基因组注释以及其他资源中已知的UGTs(包括碳水化合物活性酶数据库和糖基转移酶数据库)构建了一个全面的植物UGT数据库(pUGTdb)(图1B)。根据已发表的文献和数据库收集,pUGTdb包含285,293个UGTs,几乎是NCBI基因组数据库中UGTs数量的9倍(补充图3);然而,到目前为止,只有0.1%的UGTs(381个已表征的UGTs)已进行了功能研究(图1C;补充方法10)。
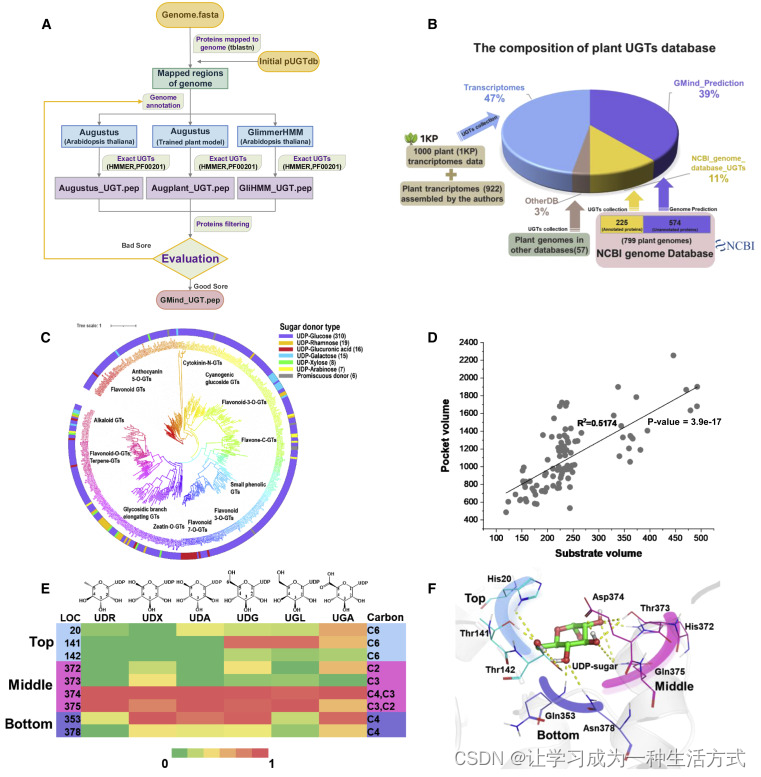
图1 植物UGT数据库的构建和分析
UGT的底物分析
基因家族分类有助于对未知UGT的功能研究。根据序列相似性和系统发育关系,所有植物UGT被分成了90个UGT家族(补充方法8和9)。约78%的植物UGT属于20个UGT家族,其中至少包含一个已功能表征的UGT(图1C)。此外,通过比较分析已表征的UGT和相应底物,我们观察到蛋白质的相似性与底物的分子相似性之间有一个有趣的正相关关系(补充图4;R2 = 0.25)。为进一步研究UGT中底物识别的潜在机制,我们通过一个快速的AlphaFold2流程对所有已表征的UGT进行了蛋白质结构的预测(补充方法11),并分析了底物及其结合口袋的结构特征(补充方法12)。我们发现催化口袋和底物之间存在着更强的正相关关系(图1D;R2 = 0.5174)。因此,我们提供了一个用于植物UGT虚拟筛选的工具,结合了底物相似性、催化口袋的体积和底物结合亲和力(补充方法12;补充图5)。为了测试我们工具的潜力,我们选择了最近报道的三个UGT作为例子(苹果酸槲皮素 4-O-葡萄糖转移酶[Xiong等,2022]、槲皮素 3-O-鼠李糖转移酶[Ren等,2022]和白藜芦醇 3-O-葡萄糖转移酶[Liu等,2021])。当使用相应物种的底物和所有UGT作为输入时,所有报告的UGT都排在前10位(补充图6)。总的来说,底物结合口袋的配置为未知UGT的底物预测和鉴定提供了可行线索,这将极大地节省实验筛选的时间和精力。
植物UGT的糖供体分析
对未知UGT的功能确定包括底物和糖供体。为了研究UGT中糖供体识别的潜在机制,我们对已表征的UGT与其糖供体进行了全面的结构分析(补充方法13;补充图10和11)。我们发现28个残基位点参与了通过氢键相互作用来结合和稳定UDP-糖的过程(补充图12)。除了与UDP相互作用的19个位点外,其余的9个位点观察到围绕着顶部、中部和底部的糖分子(图1E和1F)。在顶部区域,位于20、141和142位置的残基主要与三个六碳糖(包括UDP-葡萄糖、UDP-半乳糖和UDP-葡萄糖醛酸)中C6的羟基/羧基形成氢键。在中部,位于372–375位置的残基主要与糖分子的C2和C3位置的羟基形成氢键。374和375位置的残基与所有六种糖供体有相互作用,因为它们与糖分子的碳骨架平行。最后,从底部,353和378位置的残基维持着糖分子的骨架,并且主要与UDP-木糖、UDP-阿拉伯糖、UDP-葡萄糖、UDP-葡萄糖醛酸的C4-OH(S)的羟基形成氢键,但它们很少与UDP-半乳糖和UDP-鼠李糖的C4-OH(R)相互作用,因为羟基的上升取向。因此,我们的结果表明,这三个区域的残基起着不同的作用,稳定和识别糖供体,并且根据这些区域中氨基酸组成可以预测未知UGT的糖供体。
我们开发了一个通过整合上述关键残基位点的功能预测工具,用于UDP-糖供体的预测。简而言之,已知功能的UGT被嵌入到基于关键残基的特征向量中,并建立回归模型来拟合这些特征向量到糖供体类型(补充方法13;补充图13)。使用已知功能的UGT作为测试数据集,该工具获得了平均准确率达到89.6%。对于葡萄糖供体的准确率达到了95.5%,但对于其他糖供体的准确率仅为63.4%,这可能主要是因为只有约17%的已表征UGT参与了葡萄糖的转移。此外,我们通过设计突变体,将两个已表征的UGT(槲皮素 7-O-葡萄糖醇苷转移酶[Liu等,2018]和黄酮类化合物 7-O-葡萄糖醇苷转移酶[Ono等,2010])中的UDP-葡萄糖醛酸转化为UDP-葡萄糖供体。我们的实验验证了这些突变体显著提高了将UDP-葡萄糖醛酸作为糖供体的活性(补充图14;补充方法14–18)。最后,我们预测了我们数据库中所有未知UGT的糖供体:UDP-葡萄糖供体占94.7%,其他糖供体约占5.3%(补充表8),表明UDP-葡萄糖供体在自然界中起着主导作用。
总之,我们开发了一个UGT挖掘的基因组注释流程(GMind),并构建了一个包含285,293个植物UGT的全面植物UGT数据库(补充方法19和补充图15)。我们还研究了UGT对底物和糖供体识别的潜在机制,并开发了一个用于未知UGT的底物虚拟筛选和糖供体预测的网络工具。植物UGT的全面平台将成为社区的有用数据来源。
网址在这里
https://pugtdb.biodesign.ac.cn/ #官网这篇关于植物糖基转移酶数据库-23年-地表最强系列-文献精读-6的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






