本文主要是介绍【论文阅读——Profit Allocation for Federated Learning】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.摘要
由于更为严格的数据管理法规,如《通用数据保护条例》(GDPR),传统的机器学习服务生产模式正在转向联邦学习这一范式。联邦学习允许多个数据提供者在其本地保留数据的同时,协作训练一个共享模型。推动联邦学习实际应用的关键在于如何将联合模型产生的利润公平地分配给每个数据提供者。为了实现公平的利润分配,衡量每个数据提供者对联合模型贡献的度量标准至关重要。Shapley值是合作博弈论中的一项经典概念,用于分配所有玩家联盟所创造的整体盈余,并已被应用于机器学习服务中的数据估值。然而,先前基于Shapley值的数据估值方案要么不适用于联邦学习,要么涉及额外的模型训练,导致高昂的成本。
我们提出了一种新的基于Shapley值的指标——贡献指数,用于评估各个数据提供者对于通过联邦学习训练出的联合模型的贡献程度。贡献指数具备与Shapley值相同的属性。但是,直接计算贡献指数耗时较长,因为需要训练和评估大量包含不同数据集组合的联合模型。为解决这一问题,我们提出了两种基于梯度的方法。
这两种方法的核心思想是利用联邦学习训练过程中的中间结果来近似重建不同数据集组合上的模型,从而避免额外的训练。
第一种方法通过在联邦学习的不同轮次中更新初始全局模型的梯度来重构模型,随后根据这些重构模型的性能来计算贡献指数。
第二种方法则在每一轮中通过用当前轮次的梯度来更新前一轮的全局模型来计算贡献指数,然后将多轮的贡献指数按精心设计的权重累加起来得出最终结果。
2.贡献
- 基于Shapley值,我们正式定义了贡献指数(CI)这一概念,用于量化水平型联邦学习任务中数据提供者的贡献程度。
- 我们设计了两种高效的近似算法来计算CI,这些方法仅利用联邦学习过程中的中间结果,无需额外的模型训练步骤。
- 我们在不同设置下对MNIST数据集进行了广泛实验,以验证所提方法的有效性和效率。实验结果表明,我们的方法能够很好地逼近精确的CI值,并实现高达2倍至100倍的时间加速。
3.目标场景
在本文中,假设存在n个拥有数据集D1, D2, …, Dn的数据提供者,一个联邦学习算法A以及一个标准测试集T。
4.方法
4.1 Contribution Index(CI贡献指数)
- 有n个数据提供者 D 1 , D 2 , . . . , D n D_1,D_2,...,D_n D1,D2,...,Dn,一个机器学习算法 A A A和一个标准的测试集 T T T。
- 我们用 D S D_S DS代表由联盟S组成的符合数据集。
- 在数据集 D S D_S DS上训练得到的模型记为 M S ( A ) M_S(A) MS(A),在没有歧义的情况下可以记为 M S M_S MS。
- 模型 M M M在标准测试集 T T T上的表现记为 U ( M , T ) U(M,T) U(M,T),在没有歧义的情况下可以记为 U M U_M UM。
- 我们使用 ϕ ( A , D N , T , D i ) \phi(A,D_N,T,D_i) ϕ(A,DN,T,Di)来代表 D i D_i Di数据集的贡献指数
有如下计算公式(引理1)
ϕ i = C ∑ S ⊆ N ∖ { i } U ( M S ∪ { i } ) − U ( M S ) ( n − 1 ∣ S ∣ ) \phi_i=C\sum_{S\subseteq N \setminus \{i\}}\frac{U(M_{S\cup \{i\}})-U(M_S)}{\tbinom{n-1}{|S|}} ϕi=CS⊆N∖{i}∑(∣S∣n−1)U(MS∪{i})−U(MS)
4.2 一轮重构算法(OR)
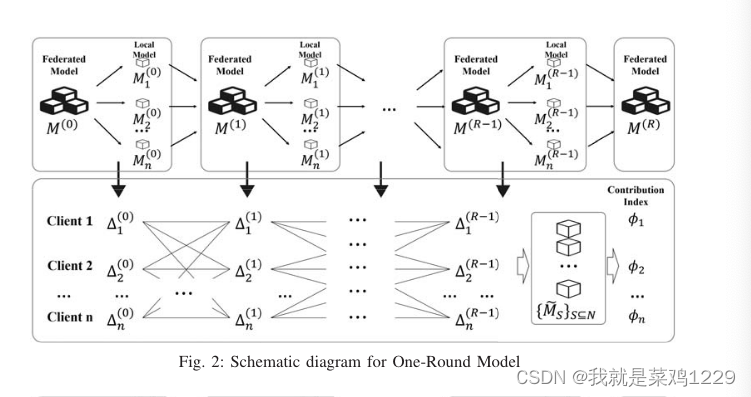

具体来说,
- 在2-3行中,我们使用N来表示{1, 2, ··· ,n}的集合,并使用相同的随机模型初始化全局模型 M ( 0 ) M^{(0)} M(0)和基于不同非空子集S⊆N的重构模型,表示为 { M ~ S ( 0 ) ∣ S ⊆ N } \{ \tilde{M}_S^{(0)} |S ⊆ N \} {M~S(0)∣S⊆N}。
- 在4-12行中,在每一轮训练中
- 服务器首先在第5行将初始模型 M ( t ) M^{(t)} M(t)传播给每个客户端,
- 然后在第6行接收来自客户端的更新的子模型 M i ( t ) i = 1 , 2 , ⋅ ⋅ ⋅ , n {M^{(t)}_i}_{i=1,2,··· ,n} Mi(t)i=1,2,⋅⋅⋅,n。
- 在第7行,计算客户端的梯度 { Δ i ( t ) } i = 1 , 2 , ⋅ ⋅ ⋅ , n \{Δ^{(t)}_i\}_{i=1,2,··· ,n} {Δi(t)}i=1,2,⋅⋅⋅,n用于模型聚合。
- 在第8行,我们更新由联邦学习维护的全局模型。
- 在9-11行中,我们不重新训练所有N的非空子集的模型,而是根据客户端的梯度大致重构这些模型。对于每个S⊆N,
- 在第10行,我们根据数据大小计算相应的梯度,
- 并在第11行使用聚合梯度来更新相应的模型。
- 在14-17行,计算不同客户端(数据提供者)的CI。
- 具体来说,对于每个客户端i,在第10行重构的模型基础上使用引理1计算其CI。
- 在第18行,返回训练好的联邦模型和CI。
- 客户端的第二部分显示在19-25行,其中客户端根据从服务器接收的模型使用其自己的数据训练本地模型,遵循经典的梯度下降算法,并将其本地模型 M i ( t ) i = 1 , 2 , ⋅ ⋅ ⋅ , n {M^{(t)}_i}_{i=1,2,··· ,n} Mi(t)i=1,2,⋅⋅⋅,n。报告给服务器。
4.3 多轮重构算法(OR)
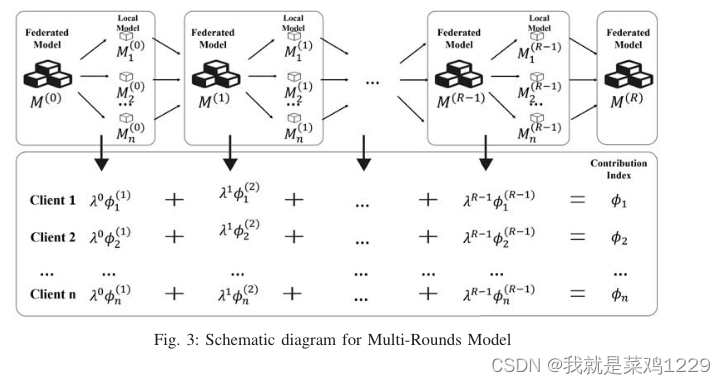

在MR中,我们不是一次性估计所有CI,而是在联邦学习的每个训练轮次中估计一组CI,并将它们聚合以获得最终结果。
在每一轮中,我们收集客户端向服务器更新的梯度。通过这些梯度,我们通过将梯度应用于当前轮次的全局模型来重构与数据集不同组合相关的模型。然后,根据引理1和每个重构模型的性能评估,计算不同数据提供者的CI。最后,利用来自不同训练轮次的这些CI集合,进行加权平均以获得最终结果。
我们使用参数λ∈(0,1)来表示衰减因子,控制最终结果中轮次CI的权重。其背后的思想是随着迭代轮次的增加,全局模型越来越多地受到所有数据集的共同影响。因此,我们给予前几轮更高的权重。
5.实验
5.1 数据集的设置
- 具有相同数据大小和相同分布。
- 具有相同数据大小但不同分布。
- 具有不同数据大小但相同分布。
- 具有相同数据大小但标签有噪声
- 具有相同数据大小但特征有噪声
5.2 方法的比较
- Exact(准确算法)
- 扩展TMC-Shapley算法
- Extended-GTB
- OR
- MR
5.3 衡量的指标
- 时间
- 余弦距离
- 欧几里得距离
- 最大差异
5.4 实验结果
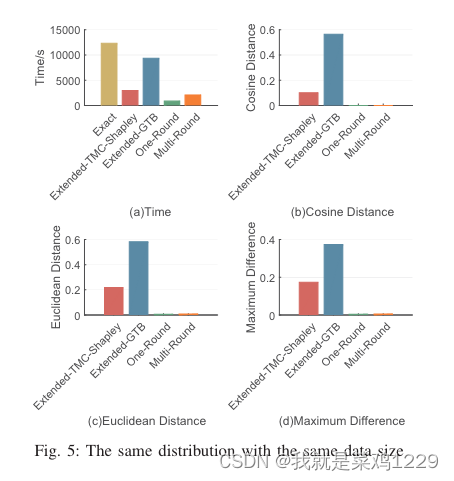
5.4.1 具有相同数据大小和相同分布
5.4.2 具有相同数据大小但不同分布
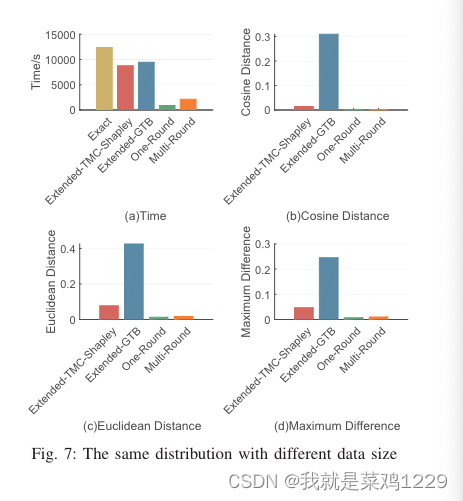
5.4.3 具有不同数据大小但相同分布
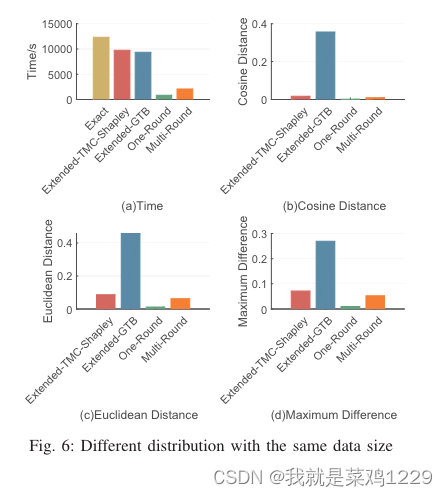
5.4.4 具有相同数据大小但标签有噪声
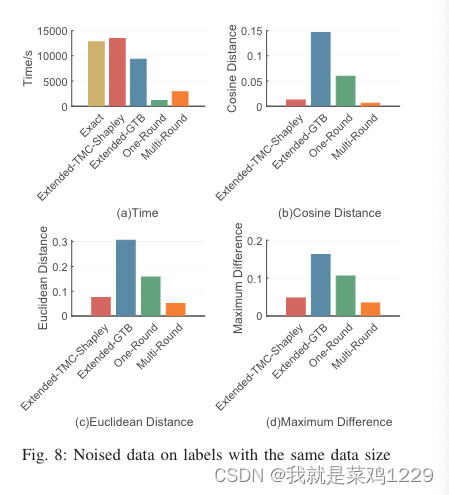
5.4.5 具有相同数据大小但特征有噪声
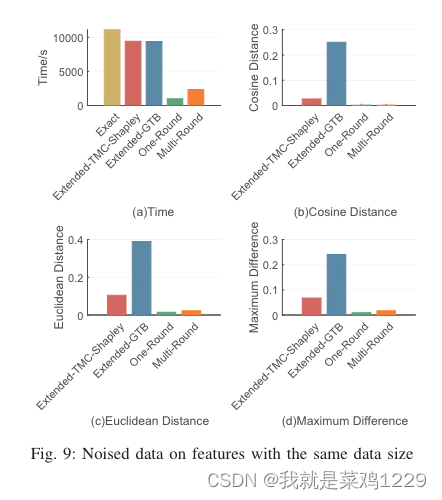
5.5 实验总结
根据上述实验,可以总结如下:
时间。Extended-TMC-Shapley 和 Extended-GTB 是耗时最长的。这两个基准算法在效率上相似。OR 和 MR 的耗时对不同设置具有鲁棒性,它们是最高效的。OR 要优于 MR。
性能。MR 的性能在所有设置中都是稳定且令人满意的。在大多数设置中,OR 在逼近精确 CI 方面表现最佳。然而,它对标签噪声敏感。Extended-TMC-Shapley 和 Extended-GTB 的性能最差。关于 Extended-GTB 的性能,我们做了一些简要的讨论。在解决 Extended-GTB 中的可行性问题时,我们发现一些不准确的约束可能会使问题无法解决。为了找到解决方案的实例,我们不得不重复放松所有不等式的约束,这会导致 CI 不准确。因此,需要专门设计的方法来解决 Extended-GTB 中的可行性问题。
6.思考
- 在企业级联邦学习场景中,由于数据量通常非常大,额外的模型训练轮次成本非常高昂
- OR没有指出数据提供方在中途加入/退出的问题,从指标上来看难以有吸引力。MR虽然可以支持各个参与方中途退出和加入,但对于贡献分配的公平性没有一个相对的概念评析。(举个例子来说:模型正确率从90上升到95,和95上升到98的贡献上来说,无法说明应该如何分配奖励)
- 该论文中并没有对模型的梯度数据进行保护,可能会存在一定的隐私泄露风险
这篇关于【论文阅读——Profit Allocation for Federated Learning】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
