本文主要是介绍pandas,polars,pyspark的df对象常见用法对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
案例背景
最近上班需要处理的都是百万,千万级的数据,pandas的性能已经不够看了(虽然它在处理数据上是真的很好用),公司都是用的polar和pyspark,我最近也学习了一些,然后写篇文章对比一下他们的常见用法。虽然他们都有数据框dataframe这个数据结构,但是具体用法还是有很多差异的。
数据选取
都是做数据分析的,那么就用最简单的机器学习数据集波士顿房价数据集吧,演示以下常见的数据处理的用法。,然后画个图,简单机器学习一下。
pyspark自己电脑装了也用不了,要分布式的虚拟机。。我这里spark都是用公司环境跑的。和pd和pl本地跑的不一样。
代码实现
我这里就用data1表示pandas的数据结构,data2表示polar数据结构。data3表示pyspark 的数据结构。3个数据结构的相同功能都用各种对应的语法展示。(data3用的不是波士顿房价的数据,是随便从公司sql里面找的一个数据....)
导入包:
import numpy as np
import pandas as pd
import polars as pl
import matplotlib.pyplot as plt
import seaborn as snsplt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号数据读取
首先是pandas的
data1=pd.read_excel('Boston.xlsx')
data1.head(2)
这个其实polar差不多:
data2=pl.read_excel('Boston.xlsx') #要装一个什么csv2xlsx的包
data2.head(2)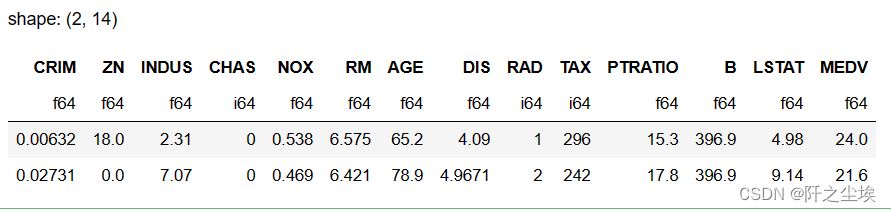
pyspark也差不多,但是我读不了本地数据....一直路径不对,可能公司虚拟机里面的的pyspark 的环境不一样。
#df = spark.read.csv("path/to/csv/file.csv", header=True, inferSchema=True)一般来说你都用pyspark了,肯定不会从本地csv读取数据,一般都是直接从sql里面掏:
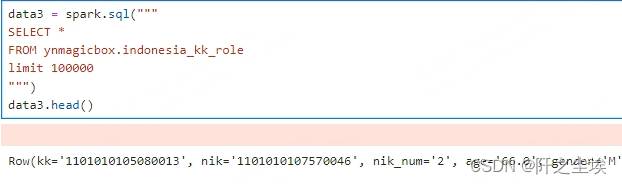
pyspark里面的.head()是只展示一行数据。
一般他们都是这样show()
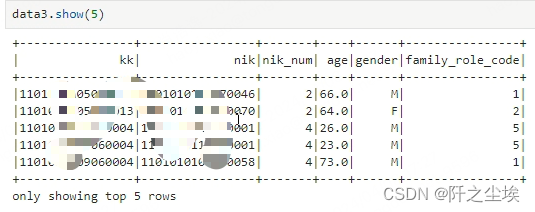
敏感信息打了个码。
写入文件
#data1.to_csv(filepath)
#data2.write_csv(filepath)
#data3.write.csv(filepath,header=True)这里就没运行了,但是是可用的,语法差不多。
查看数据基本信息
pandas很方便的info就行
data1.info() 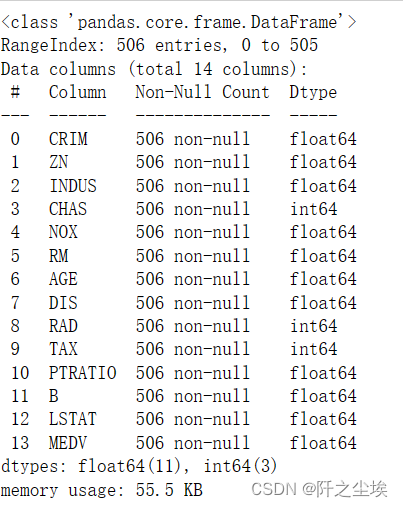
polar里面具有没有这个方法,见鬼,我只找到一个差不多的:
data2.schema
这个只有数据类别,没得非空值什么的信息,差评。
pyspark是这样的:
data3.printSchema()
其他的类型,变量名,数据形状,都是差不多:
print(data1.dtypes) ;print(data2.dtypes) #类型
print(data1.shape) ;print(data2.shape) #形状
print(data1.columns);print(data2.columns) #列名称
pyspark是这样的:
print(data3.dtypes)
print((data3.count(), len(data3.columns)))
print(data3.columns)
描述性统计
这是也是一样的,都是data.describe()就行
data1.describe() 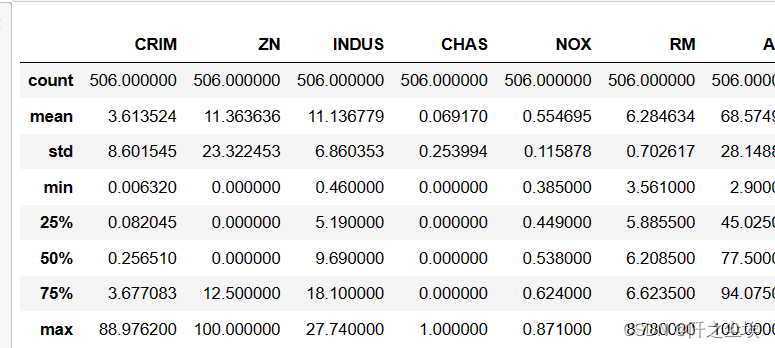
data2.describe()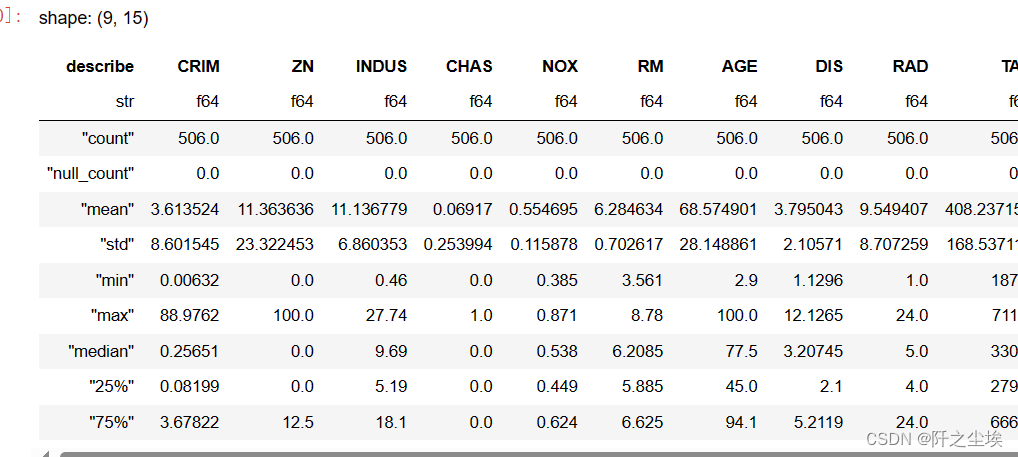
pyspark是这样的
data3.describe().show()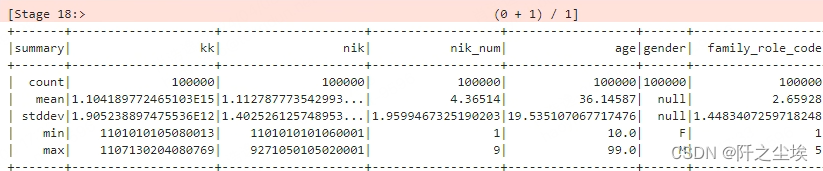
查看缺失值和填充
pandas 的我很熟悉
print(data1.isnull().sum())
data1.fillna('2')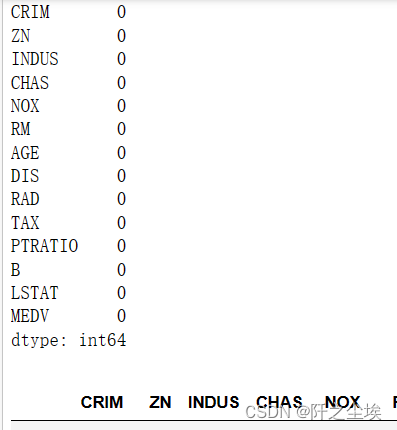
polars有些变化
print(data2.null_count())
data2.fill_null('2')
pyspark贼复杂
from pyspark.sql.functions import col, sum,expr,split,substring,when
data3.agg(*[sum(col(c).isNull().cast("int")).alias(c) for c in data3.columns]).show()
# 显示每列的缺失值数量
填充倒是一样的
data3.fillna(2)数据切片
我觉得pandas 的数据切片真的很厉害,很逻辑完善。
data1.loc[10:15,['CRIM','ZN']]
polars还没怎么用熟,不好评价
data2.slice(10, 5).select(['CRIM', 'ZN']) ##10是开始,5是行数
这里就得提一下了,polars没有索引这个东西,所以他的切片是用开始的位置和长度来穿入参数的。太离谱了,pandas的多层索引简直是诺贝尔奖发现好不好,polars居然没得索引这个东西,虽然简化一些东西,但是很多功能都丢失了。
pyspark就更加离谱了,还需要加个辅助列表示行数才能切片。。。
from pyspark.sql.functions import monotonically_increasing_id
df_with_row_index = data3.withColumn("row_index", monotonically_increasing_id()) #新增辅助列
# 切片操作
df_with_row_index.filter((col("row_index") >= 10) & (col("row_index") <= 15)).drop("row_index").select("age", "gender").show()
可能pyspark这种对大数据处理的只会动列,不会动行,也就没得行索引这个东西,连切片都没对应的方法。
数据筛选
语法差不多,各有优缺点吧
pandas
data1[data1['MEDV'] >49.9 ]polars
data2.filter(data2['MEDV'] >49.9)pyspark
data3.filter(data3.age>90).show()
选两列数据
data1[['NOX', 'RAD']]data2.select(['NOX', 'RAD'])data3.select("age", "gender")数据合并
pandas 的方法太多了:
data1.merge(pd.Series(np.random.randint(0, 10, size=len(data1)),name='new'),left_index=True, right_index=True)
## 还可以pd.concat([]),还可以直接data1['new']=
polars这个名称是真离谱啊,合并了之后名称不知道怎么给,只能重命名
##### 也是新增一列的用法
data2.with_columns(pl.Series('new1',np.random.randint(0, 10, size=len(data1)))).rename({'new1':'new'})
pyspark就是这样子加一列。
data3_with_new = data3.withColumn("new", expr("rand() * 10")) # 使用rand()函数生成随机数列
分组聚合
分组聚合麻烦起来很麻烦,可以写得超级复杂,咱们就简单求和试试
pandas:
data1.groupby('RAD').sum()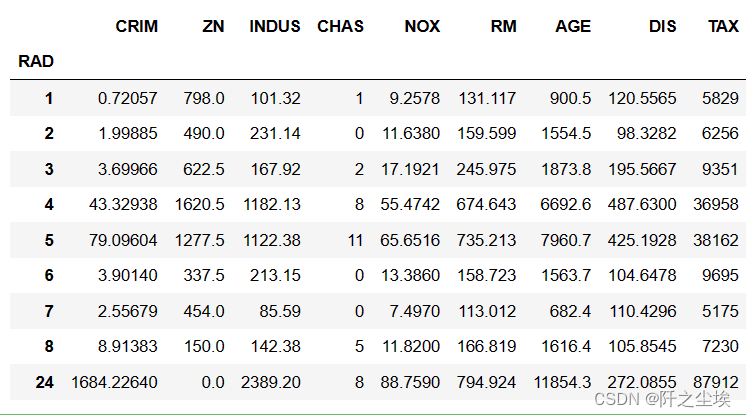
polars差不多
data2.groupby('RAD').sum()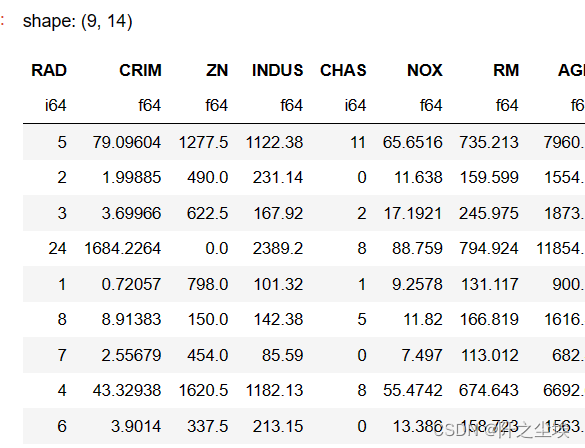
pyspark的
data3.groupBy('family_role_code').count().show()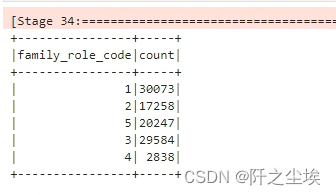
删除缺失值
数据是没缺失值的,就随便演示一下了
#data1.dropna()
data2.drop_nulls()
spark和pandas一样
data3.dropna()
数据排序
pandas长一些
data1.sort_values(['MEDV','B'],ascending=False)polars短一点,且参数名称可能有点不一样
data2.sort(by=['MEDV', 'B'],descending=True)
data3.orderBy([data3.age,data3.nik_num],ascending=False).show(5)
列名称重命名
panadas除了rename,其实还有很多方法的。
data1.rename(columns={'MEDV':'y'})
polars也有rename,但是不能传入columns,而且他也有很多别的方法
#data2.select(pl.col('MEDV').alias('10Medv')) #挑选一行数据出来重命名
data2.select([ pl.col('NOX').alias('no'),pl.col('RAD').alias('yes')]) #挑选2行数据出来重命名
data2.rename({'MEDV':'y'}) #没索引这个概念,所以就不用传入形参spark就是这样的:
data3.withColumnRenamed('kk','户口号')
应用函数
简单的函数应该是差不多的,复杂的可以有区别,但是后面遇到再说
data1['DIS'].apply(lambda x:str(x).split('.')[0])
data2['DIS'].apply(lambda x:str(x).split('.')[0]) 
我顺便验证一下pyspark切换数据类型的语法,多写了几个方法函数:
这个是年龄变成字符串切片整数
data3.withColumn("age_int", split(col("age").cast("string"), "\\.").getItem(0)).show(10) # 取age 的整数
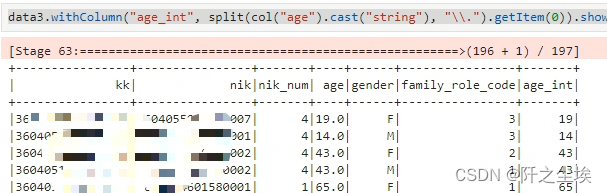
这是将年龄和nik_num变成整型数
data3=data3.withColumn("age", col("age").cast("integer"))#.show()
data3=data3.withColumn("nik_num", col("nik_num").cast("integer"))
data3.show()
这是将户口本变成数值型数据然后+4
data3.withColumn("kk_new", col("kk").cast("double") + 4).show(8) # 转为数值然后+1
这是 将身份证里面的2-4位切片出来(spark居然是从1开始,不是0开始,我人晕了)
data3.withColumn("nik_shi", substring(col("nik").cast("string"), 3, 2)).show() #
连接数据
pandas里面主要是merge函数
polars更像sql里面用join
#data1.merge(data11, on='key')
#data2.join(data22, on='key')
#data3.join(data3_with_new, data3["kk"] == data3_with_new["kk"])
#pyspark一般用法: #df1.join(df2, df1['col'] == df2['col'])删除某一列数据
两个一模一样
data1.drop(columns=['MEDV'])data2.drop(columns=['MEDV'])pyspark可以不用传入形参,我先增加一列,然后删除一列。
data3.withColumn('newColumn',F.lit('new')).drop('newColumn')
相互转化
polars数据结构也可以变成pandas和numpy的
import pyarrow as pa
data2.to_pandas() #需要安装pyarrow
#data2.to_numpy() #也可以直接运行
data3.toPandas()pyspark变不成numpy,但变成了pandas再变numpy也是一样的。
链式法则
弄个复杂一点的代码段吧,来对比他们的区别
pandas的
(data1.assign(sum_B=data1['B'].sum()) # 求和的.assign(sorted_MEDV=data1['MEDV'].sort_values()) # 排序的.assign(first_name=data1['RAD'].iloc[0]) # 第一个.assign(Medv=data1['MEDV'].mean() * 10) # 10倍
)[['sum_B','sorted_MEDV','first_name','Medv']].sort_values('sorted_MEDV')
polars 的:
data2.select(pl.sum('B'), #求和的pl.col('MEDV').sort(), #排序的pl.col('RAD').first().alias('first name'), #第一个(pl.mean('MEDV')*10).alias('10Medv'), #10倍
)
spark就不写了,报错弄了半天也不知道为什么。。
画图
pandas 的对象可以直接.plot画图的,也可以plt画图,我发现polars对象也能直接plt画图,还不错。
plt.figure(figsize=(3,2))
data1['MEDV'].plot.box() # 只有padnas对象可以这样这个方法
#plt.boxplot(data1['MEDV']) #正常的plt画图
plt.boxplot(data2['MEDV']) #pl数据也能用plt画图
plt.show()
spark没得直接画图的方法,也是变成了pandas才能画图
plt.figure(figsize=(3,2))
plt.boxplot(data3.select(['age']).toPandas()) #sparkde 数据只能转为pd才能画图
plt.show()
机器学习
我们直接把polars数据结构扔到sklearn库里面去
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
X = data2.drop(columns=['MEDV'])
y = data2['MEDV']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)线性回归:
# 线性回归
model = LinearRegression()
model.fit(X_train, y_train)
model.score(X_test, y_test)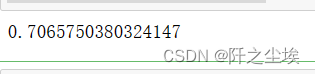
随机森林回归
# 随机森林
model = RandomForestRegressor()
model.fit(X_train, y_train)
model.score(X_test, y_test) 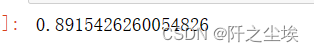
居然是和pandas一模一样的数据结果,还不错。
pyspark那差别就大了:
我们先转化数据都变成数值型:
data3=data3.withColumn("kk", col("kk").cast("double")).withColumn("nik", col("nik").cast("double"))
data3=data3.withColumn("family_role_code", col("family_role_code").cast("integer"))
data4=data3.withColumn("gender", when(col("gender") == "F", 1).otherwise(0))
data4.groupBy("gender").count().show()data4.agg(*[sum(col(c).isNull().cast("int")).alias(c) for c in data4.columns]).show()
确定没缺失值后,进行机器学习:也是随机森林
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator# 创建SparkSession对象
spark = SparkSession.builder.getOrCreate()
label_indexer = StringIndexer(inputCol="gender", outputCol="label")
data4=data4.na.drop()
# 特征向量转换器
feature_columns = data4.columns
feature_columns.remove('gender')
feature_assembler = VectorAssembler(inputCols=feature_columns, outputCol="features")# 随机森林分类器
rf = RandomForestClassifier(featuresCol="features", labelCol="label")# 构建Pipeline
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[label_indexer, feature_assembler, rf])# 拆训练集和测试集
train_data, test_data = data4.randomSplit([0.7, 0.3], seed=123)# 训练模型
model = pipeline.fit(train_data)
predictions = model.transform(test_data)
evaluator = MulticlassClassificationEvaluator(labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)
print("准确率:", accuracy)
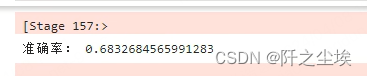
哇贼复杂,要变形编码数据后构建管道,感觉不好用。。不是数据量大到上千w我是不会想用这个来机器学习的。。。sklearn才是真神。
总结
感觉上来说,pandas和polars最大差异在于polars没得索引这个东西,并且很多 新增列,条件筛选,切片等等是存在一定的差异的,相似地方也有一些。最让我惊喜的是plt和sklearn可以完美兼容polars的数据结构,那就真的很不错了。
pyspark有的位置和pandas很像,但是有的位置又和他们差太远了,要用好这个东西还是得多练多写。
这篇关于pandas,polars,pyspark的df对象常见用法对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



