本文主要是介绍Cortex-M4架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一章 嵌入式系统概论
1.1 嵌入式系统概念
用于控制、监视或者辅助操作机器和设备的装置,是一种专用计算机系统。
更宽泛的定义:是在产品内部,具有特定功能的计算机系统。
1.2 嵌入式系统组成
硬件
①处理器:CPU
②存储器: Flash、SRAM
③外围电路:复位/时钟/AD/DA
软件
①底层驱动:IIC/SPI
②操作系统:FreeRTOS、linux
③中间件(API):应用程序接口
④应用程序:GUI
系统外设包括:电源模块、GP时钟模块和存储模块、网络接口、USB接口、IO设备接口以及其他外围设备。
网络接口:有线、无线接口。
有线:以太网、RS485、USB
无线:wifi、蓝牙
第二章 微处理器体系结构
2.1 嵌入式微处理体系结构
2.1.1 冯诺依曼结构
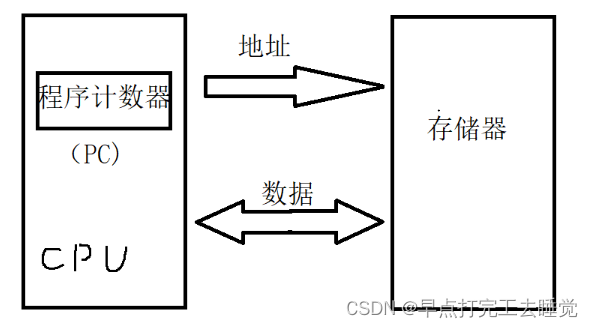
指令和数据存储在同一个存储器的不同物理单元。CPU通过地址总线,访问存储器相应地址单元中的内容。内容既可以是指令,也可以是数据,然后通过数据总线,将指令或数据传输给CPU。
2.1.2 哈佛结构
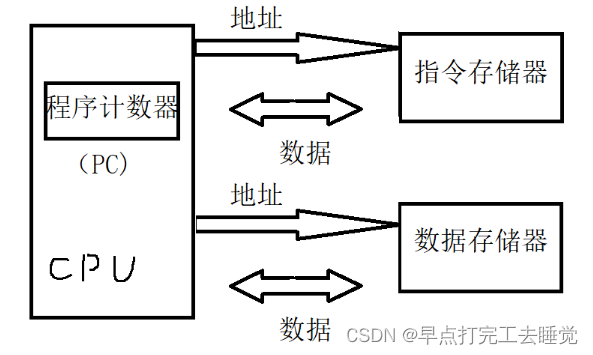
将数据和指令分别存储在不同的物理存储器,并通过两套总线分别传输。CPU首先到指令存储器中读取指令,解码后得到数据地址,再到对应的数据存储器中读取数据。
指令和数据可以同时访问,并且指令和数据可以有不同的带宽。
使用两组独立的总线,分别作为CPU与各存储器之间的专属通信通道,分别存储指令和数据。所以执行效率就高。
Cortex-M4的处理器架构采用哈佛结构,为系统提供个三套总线,独立发起总线传输读写操作。
①:I-Code总线用于取指令
②:D-code总线用于操作数据
③:系统总线用于访问其他系统空间,包括指令、数据访问,CPU及调试模块发起的访问和支持位访问。
2.2 嵌入式微处理器类型
2.2.1 MCU(嵌入式微控制器)
将整个计算机系统集成到一块芯片上,在芯片内部集成了各种必要的功能部件和外设。CPU+内存+外设。
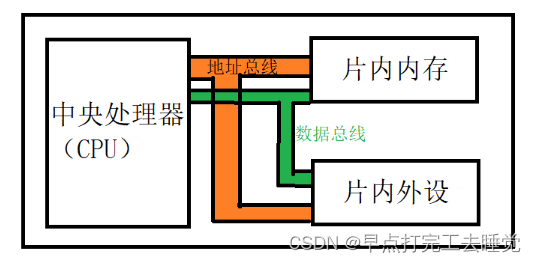
2.2.2 MPU (嵌入式微处理器)
只保留和嵌入式应用紧密相关的功能硬件,删除其他冗余功能部件。是一个单芯片CPU,芯片内部没有存储器和外设接口等部件。只有CPU。
2.2.3 SOC (嵌入式片上系统)
可实现一个完整的软件和硬件系统,在单一芯片中实现软硬件的无缝结合,直接在处理器内部嵌入操作系统的代码模块,集成度高,处理能力强。
2.2.4 DSP (数字信号处理器)
专门用于信号处理的处理器,其系统结构和指令进行了特殊设计。
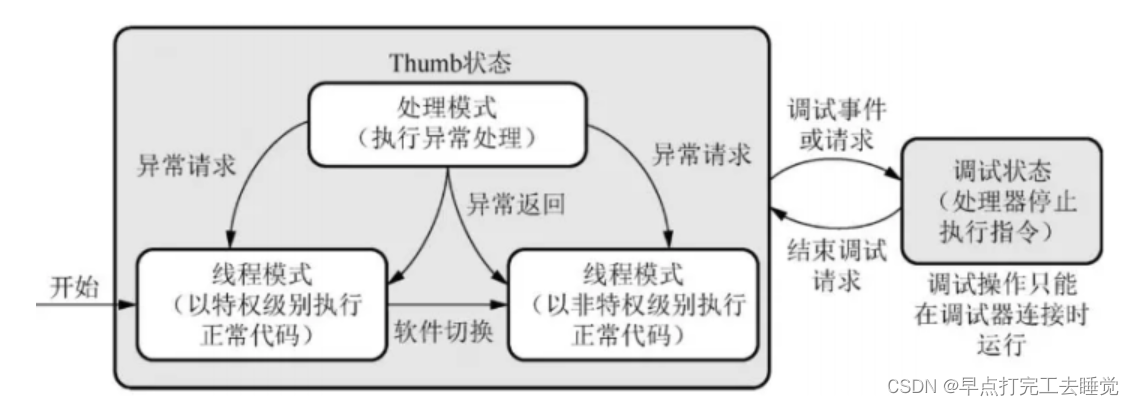
2.3 Cortex-M4处理器操作模式
2.3.1 线程模式
用于处理正常代码。处于特权级别的线程模式可以通过软件切换为非特权级别的线程模式。反之不行。
当系统复位时从线程模式中开始执行,遇到异常时自动变为特权级处理模式,异常处理程序完成后再回到线程模式。
2.3.2 处理模式
必须在特权级下执行,用于异常处理程序
| 代码类型 | 特权级 | 用户级 |
|---|---|---|
| 异常服务例程代码 | 处理模式 | 错误用法 |
| 主应用程序代码 | 线程模式 | 线程模式 |
2.4 ARM中的寄存器(可编程模式)
Cortex-M4处理器的可编程模式主要包括核心寄存器、堆栈和异常中断所涉及的寄存器。核心寄存器包括16个寄存器(R0~R15),其中R0~R12为32位通用寄存器,R13是堆栈指针,R14是链接寄存器,R15是程序计数器。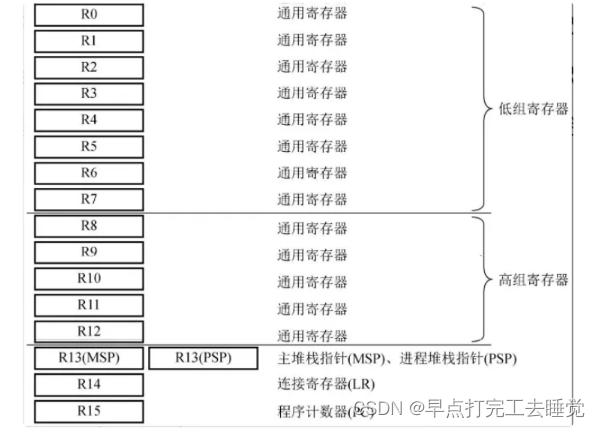
2.3.1 通用寄存器 R0~R12
通用寄存器分为两组:低组寄存器(R0~R7)和高组寄存器(R8~R12)。
低组寄存器,大小32位,能够被所有访问通用寄存器的指令访问,复位后初始值不变。
高组寄存器,大小32位,也能够被所有32位通用寄存器指令访问,但不能被所有16位指令访问,复位后初始值不定。
复位后初始值不变:即使系统重新启动或复位,寄存器中存储的数据仍然保持之前的数值,不会被重置或清零。
R0~R3:用做传入函数参数,传出函数的返回值。在子程序调用之间,可将R0~R3用于任何用途。被调用函数在返回之前不必恢复R0~R3。如果调用函数再次使用R0~R3的内容的话,则必须保留这些内容。当参数多于4时,会将多出的参数压入栈中进行传递(在函数调用过程中也会把R0,R1,R2,R3传递的参数压入栈)。
R4~R11:被用来存放函数的局部变量。如果调用函数使用了这些寄存器,它在返回之前必须回复寄存器的值。
R12:是内部调用暂时寄存器(ip),在过程链接胶合代码中用此角色。
在中断程序中,所有寄存器都必须保护,编译器会自动保护R4~R11
2.3.2 堆栈指针
R13:栈指针(SP),存放的值在退出调用函数时必须与进入调用函数时的值相同。
堆栈指针在物理上存在两个堆栈指针寄存器:主堆栈指针(MSP)和进程堆栈指针(PSP)
主堆栈指针(MSP)
①是默认的堆栈指针,它供给操作系统内核、异常服务例程及所有特权级访问的应用程序代码使用,即用于管理异常处理和中断服务。
②当处理异常或中断时,系统会自动切换到MSP
③在启动时通常初始化为系统的顶部内存地址。
可以用于线程模式和处理模式。
进程堆栈指针(PSP)
①用于处理线程或进程的函数调用和局部变量等;
②在多线程或多任务环境下,每个线程/任务都有自己的PSP
③当切换到线程/任务时,系统会切换到PSP的值。
多数情况下,若应用不需要嵌入式操作系统,则没必要使用PSP。
堆栈功能
SP指针是用来指示系统的栈空间。栈空间一般用于上下文切换处理。
PUSH:入栈
POP:出栈
使用情况
①当正在执行的函数需要使用寄存器进行数据处理时,临时存储数据的初始值。
②向函数或子程序中传递信息。
③存储局部变量。
④在中断等异常产生时保存处理器状态和寄存器数值。
Cortex-M4处理器使用的栈模型
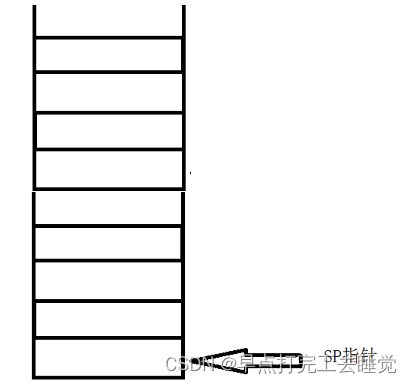
处理器启动后,SP被设置为栈存储空间的最后一个位置,每次使用PUSH操作时,处理器先减小SP的值,然后将数据存储在SP指向的存储器的位置。POP操作,则先将SP指向的存储器位置的数据读出,然后SP的值增加。
2.3.3 链接寄存器(LR)
R14:链接寄存器(LR),当调用一个函数时,返回地址被自动保存到链接寄存器中,在函数返回时有效。
①:调用子程序时用于保存调用返回地址②发生异常时用于保存异常返回地址。
函数或子程序结束时,程序控制可以通过将LR的数值加载到PC中,返回调用程序并继续执行。
2.3.4 程序计数器(PC)
指向当前正在执⾏的指令的地址。是可读可写的寄存器。通过对PC的操作,改变程序直系那个的流程。
读PC时返回当前指令的地址加4:ARM处理器采⽤了指令流⽔线的执⾏⽅式,在执⾏阶段之前,处理器已经从存储器中取出了下⼀条指令,并且PC已经指向了下⼀条指令的地址。因此,当读取PC时,返回的是PC指向的下⼀条指令的地址。(由于ARM处理器采用的是32位指令集,每条指令通常占用4个字节的存储空间,所以返回的地址是当前指令地址加上4。)
写PC:当向程序计数器(PC)写入数据时,实际上是将新的地址值加载到程序计数器中,从而改变了程序流的执行路径。这会导致程序执行跳转到新的地址处,执行新的指令序列。
2.5 特殊寄存器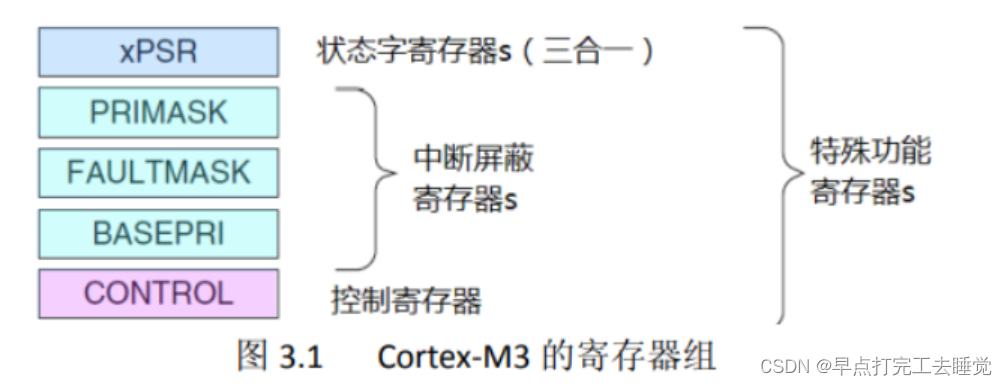
特殊寄存器分为程序状态寄存器、中断屏蔽寄存器和控制寄存器三大类。
2.4.1 程序状态寄存器
在其内部被分成3个子状态寄存器:应用APSR,中断IPSR,执行EPSR。这三个既可以单独访问,也可以2个或3个一起组合访问。一般我们通过MRS/MSR指令来访问特殊功能寄存器。
①应用状态寄存器(APSR)
是保持当前指令运算结果状态的寄存器。
②中断状态寄存器(IPSR)
主要字段是中断服务程序号,它指示了当前正在执行的中断服务程序的编号。这个编号对应着处理器的异常向量表中相应条目,用于确定中断服务程序的入口地址。
IPSR寄存器的内容在中断服务程序执行之前被自动保存在堆栈中,在中断服务程序执行结束后被自动恢复,以保证中断处理的正确性。
是Cortex-M处理器特有的,用于处理中断的相关状态信息。
③执行状态寄存器(EPSR)
包括中断继续指令为或IF-THEN指令状态位,以及Thumb指令设置位。
2.4.2 中断屏蔽寄存器
2.4.3 控制寄存器
用于定义处理器特权级别和用于选择堆栈指针。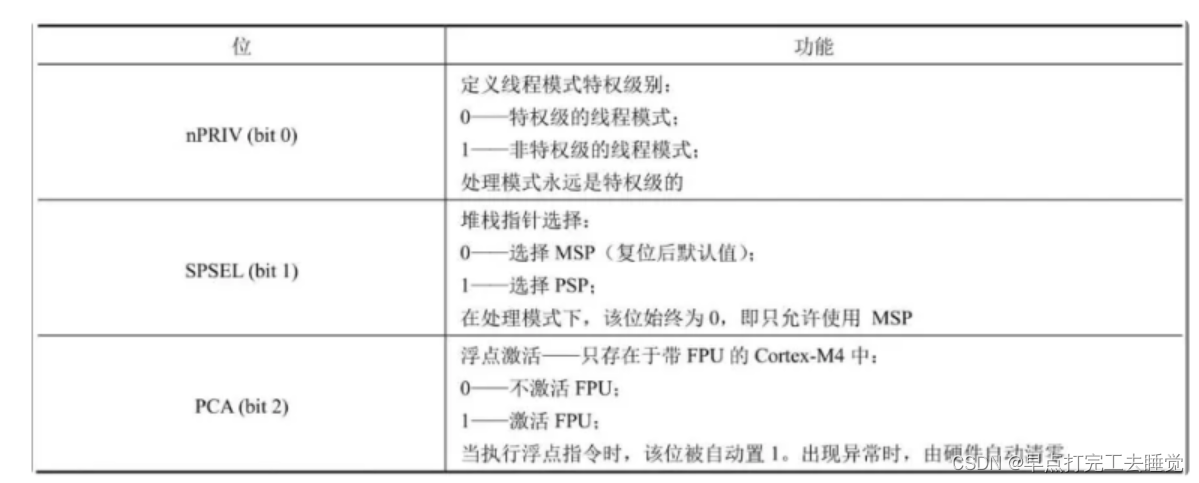
2.6 流水线技术
2.6.1 什么是流水线
一条指令的执行可以分解为多个阶段,各个阶段使用到的硬件不同,这样指令执行就可以重叠,可以多条指令并行处理。
2.6.2 三级流水线
包括取值、译码、执行三个阶段。 Cortex-M4采用三级流水线。
这样,⼀条指令需要3个时钟周期来完成,但吞吐率是每个周期1条指令。
周期为1时,取第一个指令;周期为2时,取第二个指令并译码第一条指令;周期为3时,取第三个指令,译码第二条指令并执行第一条指令,依次往下。
注意:流水线技术增加了CPU的吞吐量,但没有减少每条指令的延迟。
吞吐量:单位时间内执行的指令数
延迟:一条指令从进入流水线到流出流水线所花费的时间。
2.6.3 五级流水线
包括取值、译码、执行、缓冲/数据、回写五个阶段。
取指(Fetch):从内存中读取指令
译码(Decode):解析指令并确定执⾏所需的操作
执⾏(Execute):执⾏指令,包括运算、内存访问等
访存(Memory Access):如果指令需要访问内存,则在此阶段执⾏
回写(Write Back):将执⾏结果写回到寄存器中
2.6.4 超流水线
某款处理器内部的流水线超过了通常的5级或6级。
2.7 中断机制
2.7.1 什么是中断
在CPU正常执行过程中,外部发生了随机事件,CPU需要暂时中止正在执行的程序转而去处理所发生的事件。处理完成后,再返回到原来被中止的程序继续执行。
中断和异常
中断:CPU内核外部的片上外设产生的紧急事件。系统停止当前正在运行的程序转而其他服务,可能是程序接收了比自身高优先级的请求,属于正常现象。
异常:CPU内核内部产生的紧急事件。异常通常是微处理器内部发生的,大多是软件引起的,比如非法指令(除零)、地址访问越界等。属于不正常现象。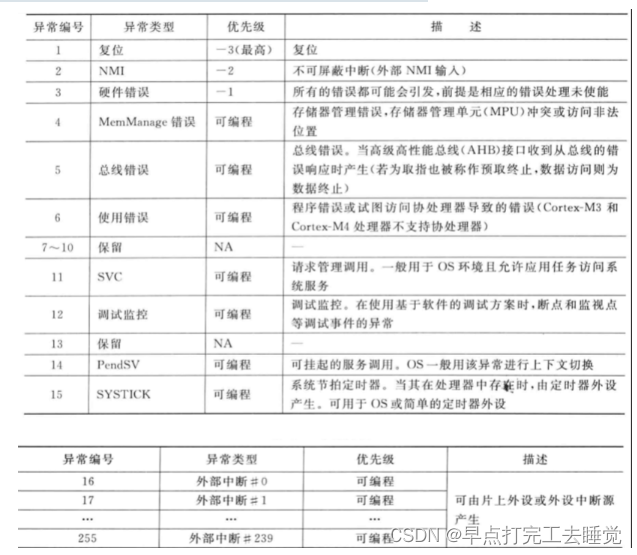
2.7.2 中断分类
①外部中断:由外部硬件设备为获得CPU的执行而产生的异步事件。
②软件中断:是程序中特殊指令产生的同步事件。
③内部中断:出现一些异常情况下,CPU自发生成的同步事件。
NVIC :总的中断控制器,专门管理中断,属于内核上的外设
2.7.3 中断管理机制
1、中断向量
中断服务程序的入口地址。
中断向量表:存放所有中断向量的存储区。
STM32的内部闪存地址起始于0x8000000,一般情况下,程序文件就从此地址开始写入。此外STM32其内部通过“中断向量表”来响应中断,程序启动后,将首先从“中断向量表”取出复位中断向量执行复位中断程序完成启动。而这张“中断向量表”的起始地址是0x8000004,当中断来临,STM32的内部硬件机制亦会自动将PC指针定位到“中断向量表”处,并根据中断源取出对应的中断向量执行中断服务程序。
(1)STM32复位后,会从地址为0x8000004处取出复位中断向量的地址,并跳转执行复位中断服务程序,如图6中标号①所示。
(2)复位中断服务程序执行的最终结果是跳转至C程序的main函数,如图6中标号②所示,而main函数应该是一个死循环,是一个永不返回的函数。
(3)在main函数执行的过程中,发生了一个中断请求,此时STM32的硬件机制会将PC指针强制指回中断向量表处,如图6中标号③所示。
(4)根据中断源进入相应的中断服务程序,如图6中标号④所示。
(5)中断服务程序执行完毕后,程序再度返回至main函数中执行,如图6中标号⑤所示。
2、中断优先级
中断优先级通过优先级配置寄存器进行配置,本寄存器宽度为8位,STM32只用到了中断优先级寄存器的的高4位。
Cortex-M4为增强带有中断系统中的优先级控制,NVIC支持优先级分组。将每个中断优先级寄存器项分为两个字段:上部字段和下部字段。其中上部字段定义组优先级,下部字段定义组中的子优先级。
3、中断管理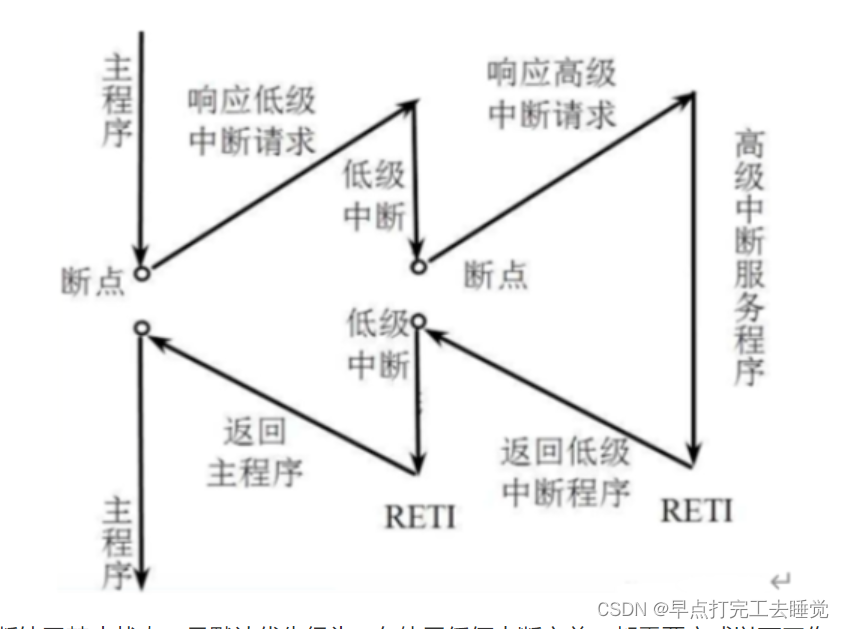
复位后:所有中断处于禁止状态,且默认优先级为0.在使用任何中断之前,都需要完成以下工作:
(1)设置所需的中断优先级;
(2)使能外设中可以触发中断的中断产生控制;
(3)使能NVIC中的中断;
当触发中断时,对应的ISR会执行相应的中断。编写程序时,相应ISR名称与向量表中的名称一致,这样链接器才能将该ISR入口地址放入向量表的正确位置。
进入中断:
(1)中断源发出请求,硬件判断处理器是否允许中断及该中断是否被屏蔽,若允许中断则当前运行的程序被打断; (2)处理器将各寄存器的内容压入堆栈保存,主要是PC, xPSR, R0-R3, R12, LR寄存器; (3)根据中断向量号,到中断向量表中找到中断服务程序的入口地址跳转执行。
中断处理:
(1)执行中断服务程序; (2)遵循中断优先级和中断嵌套的执行规则。
退出中断:
(1)将保存在堆栈中的现场信息弹出到原来的寄存器中; (2)返回被原先被中断的程序处继续执行。
目前是这样的,还得再下下功夫修炼内功
这篇关于Cortex-M4架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






