本文主要是介绍【ARMv7-M】| 01——阅读笔记 | 简介|应用程序级编程和内存模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
【ARMv7-M】| 01——阅读笔记 | 简介|应用程序级编程和内存模型
| 失败了也挺可爱,成功了就超帅。 |
文章目录
- 前言
- 1、简介
- 2、应用程序级编程模型
- 2.1 编程模式和访问等级
- 2.2 数据类型和运算操作
- 2.3 寄存器和执行状态
- 1.2.4 异常和中断
- 1.2.5 浮点单元寄存器
- 3、内存模型
- 3.1 地址空间
- 3.2 对齐
- 3.3 大小端
- 3.4 同步和信号量
前言
本文为ARMv7-M参考手册的阅读笔记
1、简介
ARMv7架构根据不同应用场景和性能 分为三个分支 -A -R -M
ARMv7-A:用于高性能应用型SOC 支持ARM和Thumb指令集 内存管理单元使用 MMU 支持虚拟内存
ARMv7-R:用于实时性要求很高的SOC 支持ARM和Thumb指令集 内存管理单元使用 MPU支持内存保护
ARMv7-M:用于低成本低功耗性能够用的MCU 只支持Thumb指令集(Thumb-2) 如扩展浮点运算单元的MCU 会在此基础上加入浮点指令
ARMv7-M架构支持两种扩展功能:DSP和FP浮点指令
DSP扩展:包含 饱和指令及SIMD指令(单指令多数据)
FP扩展:可选单精度和双精度
基于Cortex-M4带FPU的MCU 支持DSP和FP单精度
2、应用程序级编程模型
2.1 编程模式和访问等级
两种:处理模式和线程模式
程序正常运行在线程模式 执行异常中断时会处于处理模式
程序运行又分为两种访问权限:特权访问和非特权访问
特权:所有资源都可以控制 非特权:有限制
线程模式可以通过程序控制处于特权/非特权运行 处理模式总是特权模式
2.2 数据类型和运算操作
该架构中 支持 字节、半字、字类型的数据。
当加载字节、半字大小的指令时可以通过加载指令指定零/符号扩展
可以对64位整数数据直接操作 一般情况通过两个指令合并它们。
指令集提供了对寄存器中值的一些操作指令:按位逻辑与或非、移位、加减乘 和我们编程语言中支持的运算操作符类似 只不过使用方式不同
使用方式如下:使用内置函数/ARM指令(ARM汇编)
LSL逻辑左移: 将一个寄存器中的值进行逻辑左移
eg:LSL R1, R2, #3 将R2寄存器中的值逻辑左移3位 写入R1中
LSR逻辑右移:将一个寄存器中的值进行逻辑右移
eg:LSR R1, R2, #3 将R2寄存器中的值逻辑右移3位 写入R1中
ASR算术右移:将一个寄存器中的值进行算术右移
eg:ASR R1, R2, #3 将R2寄存器中的值算术右移3位 写入R1中
ROR循环右移:指令把所有位都向右移,最低位复制到进位标志位和最高位
eg:ROR R1, R2, #3 将R2寄存器中的值循环右移3位 写入R1中
RRX循环右移:对寄存器中的内容进行带扩展的循环右移的操作。是一种协处理器指令。按操作数所指定的位数向右循环移位,左端用进位标志位C来填充。其中,操作数可以是寄存器,也可以是立即数(0~31)。例如,MOV R0,R1,RRX#2;将R1中的内容进行带扩展的循环右移两位后传送到R0中。
2.3 寄存器和执行状态
一共有16个32位寄存器 其中13个通用寄存器(R0-R12) 和 3个特殊功能寄存器(SP/LR/PC)
SP:R13 堆栈指针 指向栈顶
LR:R14 链接寄存器 存储程序返回地址
PC:R15 程序计数器 程序执行向地址
程序执行状态寄存器 APSR 32位

1.2.4 异常和中断
中断是异常的一种 可以由异常/中断行为触发 也可通过软件触发
系统异常如 SVC/PendSV systick等
它们的控制都用 中断控制状态寄存器 ICSR决定 后面章节详解
1.2.5 浮点单元寄存器
只有支持该扩展的MCU才有 Cortexm4带FPU的会有
32个单精度寄存器 S0-S31 两两一组 16个双精度寄存器 D0-D15
更多关于浮点扩展先不看了
3、内存模型
3.1 地址空间
后面章节详解
3.2 对齐
支持非对齐访问
非对齐指令

3.3 大小端
支持大端和小端 默认小端
通过SCB系统控制寄存器 可以修改
加载寄存器数据/存储数据到寄存器的指令
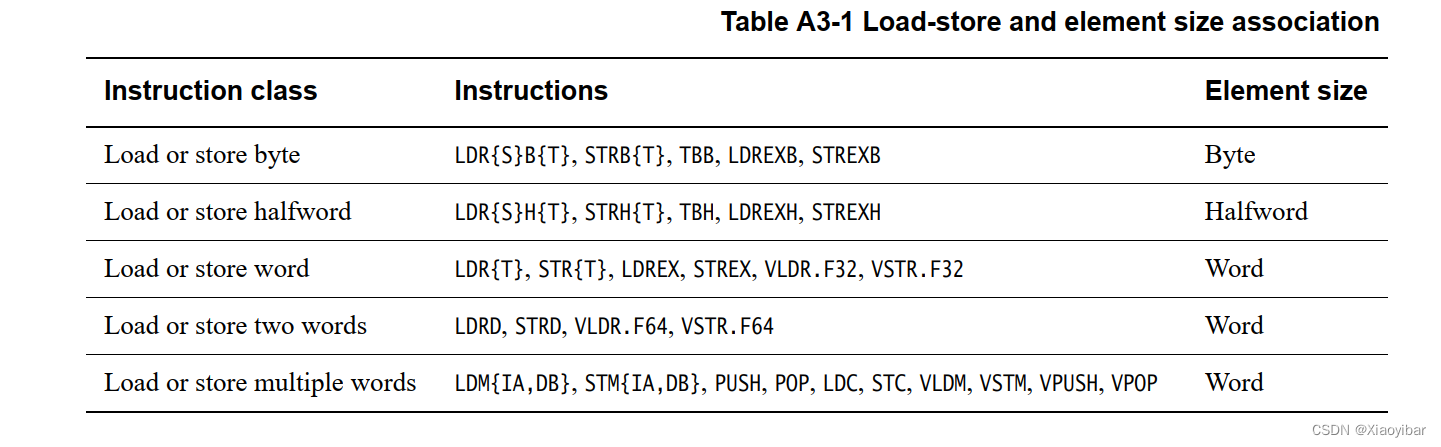
对通用寄存器翻转字节的指令

3.4 同步和信号量
在多线程运行下 信号量同步操作时我们常见的 线程间通信的方式
排他访问 指令具有原子操作 很好的满足了信号量的实现

待
这篇关于【ARMv7-M】| 01——阅读笔记 | 简介|应用程序级编程和内存模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



