本文主要是介绍avro c++编译与使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、arvo介绍
Avro 是 Hadoop 中的一个子项目,也是一个数据序列化系统,其数据最终以二进制格式,采用行式存储的方式进行存储。
Avro提供了:
1)、丰富的数据结构。
2)、可压缩、快速的二进制数据格式。
3)、一个用来存储持久化数据的容器文件。
4)、远程过程调用。
5)、与动态语言的简单集成,代码生成不需要读取或写入数据文件,也不需要使用或实现 RPC 协议。代码生成是一种可选的优化,只值得在静态类型语言中实现。
schema(模式)
Avro 依赖 schema(模式)来实现数据结构的定义,schema 通过 json 对象来进行描述表示,具体表现为:
一个 json 字符串命名一个定义的类型。
一个 json 对象,其格式为
{"type":"typeName" ... attributes ...},其中 typeName 为 原始类型名称 或 复杂类型名称。
一个 json 数组,表示嵌入类型的联合。
schema 中的类型由 原始类型(也就是 基本类型)
(null、boolean、int、long、float、double、bytes 和 string)和 复杂类型(record、enum、array、map、union 和 fixed)组成。
1、原始类型
原始类型包括如下几种:
null:没有值
boolean:布尔类型的值
int:32 3232 位整形
long:64 6464 位整形
float:32 3232 位浮点
double:64 6464 位浮点
bytes:8 88 位无符号类型
string:unicode 字符集序列
原始类型没有指定的属性值,原始类型的名称也就是定义的类型的名称,因此,schema 中的 "string" 等价于 {"type":"string"}。
2、复杂类型
Avro 支持 6 种复杂类型:records、enums、arrays、maps、unions 和 fixed。
2.1)records
reocords 使用类型名称 "record",并支持以下属性。
name:提供记录名称的 json 字符串(必选)
namespace:限定名称的 json 字符串
doc:一个 json 字符串,为用户提供该模式的说明(可选)
aliases:字符串的 json 数组,为该记录提供备用名称
fields:一个 json 数组,罗列所有字段(必选),每个字段又都是一个 json 对象,并包含如下属性:
name:字段的名称(必选)
doc:字段的描述(可选)
type:一个 schema,定义如上
default:字段的默认值
order:指定字段如何影响记录的排序顺序,有效值为 "ascending"(默认值)、"descending" 和 "ignore"。
aliases:别名
一个简单实例:
{"type": "record","name": "face","aliases": ["faceattribute"],"fields", [{"name": "score", "type": "float"},{"name": "feature", "type": ["null", "string"]}]
}2.2)maps
values:map 的值(value)的 schema,其 key 被假定为字符串。
一个实例,声明一个 value 为 long 类型,(key 类型为 string)的 map:
{"type": "map","values": "long","default": {}
}avro文件格式
Avro 格式是 Hadoop 的一种基于行的存储格式,被广泛用作序列化平台。
Avro 格式以 JSON 格式存储模式,使其易于被任何程序读取和解释。数据本身以二进制格式存储,使其在 Avro 文件中紧凑且高效。
Avro格式是语言中立的数据序列化系统。它可以被多种语言处理(目前是 C、C++、C#、Java、Python 和 Ruby)。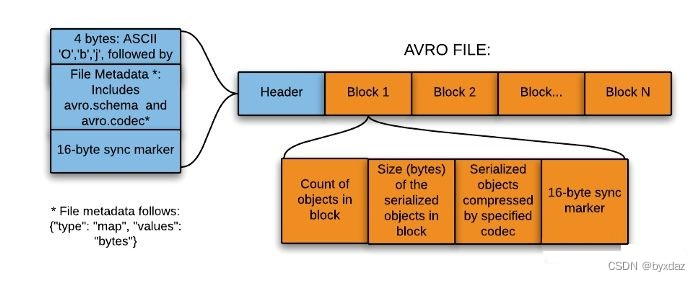
二、avro c++编译
1、avrocpp下载地址
https://avro.apache.org/project/download/里面找到download连接。
https://dlcdn.apache.org/avro/
2、api文档
https://avro.apache.org/docs/
3、编译
需要准备文件:
cmake
avro-cpp-1.11.3.tar.gz
boost_1_66_0
zlib、sanppy 压缩算法库,可选。
通过cmake生成vs解决方案文件。其中的build文件夹是通过cmake创建的,这个是用来编译程序,编译的时候在build里执行。如下图: 进入build文件夹,打开Avro-cpp.sln文件,可以编译avrocpp、avrocpp_s、avrogencpp等等工程。如下图:
进入build文件夹,打开Avro-cpp.sln文件,可以编译avrocpp、avrocpp_s、avrogencpp等等工程。如下图:
avro库中还提供了4中文件的压缩方式,sanppy、default、lzma和null
Snappy 是一个 C++ 的用来压缩和解压缩的开发包,其目标不是最大限度压缩,而且不兼容其他压缩格式。Snappy 旨在提供高速压缩速度和合理的压缩率。Snappy 比 zlib 更快,但文件相对要大
20% 到 100%。
snappy zlib lzma 对比
snappy, zlib 和 lzma都是数据压缩算法,但它们各有优势和不同的使用场景。
snappy:
优势:速度快,适合需要快速压缩和解压缩的场景。
缺点:压缩比不如其他算法高,不支持跨平台。
zlib:
优势:压缩比高,支持压缩和解压缩,支持动态数据。
缺点:压缩速度稍慢,解压缩时需要预先加载整个数据。
lzma:
优势:极高的压缩比,支持压缩和解压缩,支持分块处理。
缺点:解压速度慢,初始化时间较长,内存需求较高。
在选择压缩算法时,需要考虑数据大小、压缩比、速度要求以及是否需要跨平台等因素。
三、avro c++使用
1、创建schema
创建一个schema,比如:cpx.json
{
"type": "record",
"name": "cpx",
"fields" : [
{"name": "re", "type": "double"},
{"name": "im", "type" : "double"}
]
}2、使用avrogencpp生成数据结构代码。
avrogencpp -i cpx.json -o cpx.hh或
avrogencpp -i cpx.json -o cpx.hh -n myselfnamespace注意:-n表示使用特殊的命名空间。
3、数据序列化到avro文件实例。
#include "cpx.hh"
#include "avro/Encoder.hh"
#include "avro/Decoder.hh"
#include "avro/ValidSchema.hh"
#include "avro/Compiler.hh"
#include "avro/DataFile.hh"
#include "avro/Specific.hh"
#include <fstream>avro::ValidSchema loadSchema(const char* filename)
{std::ifstream ifs(filename);avro::ValidSchema result;avro::compileJsonSchema(ifs, result);return result;
}int main()
{//将数据序列化到avro文件、从avro文件反序列化数据avro::ValidSchema cpxSchema = loadSchema("cpx.json");//write file{avro::DataFileWriter<c::cpx> dfw("./test.bin", cpxSchema);c::cpx c1;c1.re = 1.0;c1.im = 2.13;dfw.write(c1);for (int i = 0; i < 10; i++) {c1.re = i * 100;c1.im = i + 100;dfw.write(c1);}dfw.close();}//read file{avro::DataFileReader<c::cpx> dfr("./test.bin", cpxSchema);c::cpx c2;while (dfr.read(c2)) {std::cout << '(' << c2.re << ", " << c2.im << ')' << std::endl;}}return 0;
}
4、数据序列化到内存实例。
#include "cpx.hh"
#include "avro/Encoder.hh"
#include "avro/Decoder.hh"
#include "avro/ValidSchema.hh"
#include "avro/Compiler.hh"
#include "avro/DataFile.hh"
#include "avro/Specific.hh"
#include <fstream>avro::ValidSchema loadSchema(const char* filename)
{std::ifstream ifs(filename);avro::ValidSchema result;avro::compileJsonSchema(ifs, result);return result;
}int main()
{//将数据序列化到内存、从avro内存反序列化数据avro::ValidSchema cpxSchema = loadSchema("cpx.json");//write streamstd::string strOutput = "";{std::stringstream ssOutput;avro::DataFileWriter<c::cpx> dfw(avro::ostreamOutputStream(ssOutput, 8 * 1024),cpxSchema);c::cpx c1;c1.re = 1.0;c1.im = 2.13;dfw.write(c1);for (int i = 0; i < 10; i++){c1.re = i * 100;c1.im = i + 100;dfw.write(c1);}dfw.close();strOutput = ssOutput.str();printf("OutputSize:%d\n", strOutput.size());//临时保存文件std::ofstream ofs("./test2.bin", std::ios::binary);if (ofs.is_open()){ofs.write(strOutput.data(), strOutput.size());ofs.close();}}//read stream{std::stringstream ssOutput;int n = 0;for (n = 0; n < strOutput.size(); n++){ssOutput << strOutput[n];}avro::DataFileReader<c::cpx> dfr(avro::istreamInputStream(ssOutput, 8 * 1024) , cpxSchema);c::cpx c2;while (dfr.read(c2)) {std::cout << '(' << c2.re << ", " << c2.im << ')' << std::endl;}}return 0;
}这篇关于avro c++编译与使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





