本文主要是介绍【一场由TiCDC异常引发的GC不干活导致的Tikv硬盘使用问题】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当大家看到这个标题时,就已经知道了下面几点:
(1)出了撒子问题?ok,集群所有KV节点存储硬盘使用80%以上,凌晨触发频繁报警,搞DB的兄弟们还能不能愉快的睡觉?
(2)谁搞的?ok,GC不干活。
(3)真正导致问题的原因是啥?OK,TiCDC背锅。
完了,看到这里本篇文章就基本介绍完了,会不会被劝退?但是老铁千万别走,且听我将细节娓娓道来,后面有“干货”,我会说明我到底做了啥子操作降低硬盘使用;GC为啥不干活?GC的原理是啥?还有为啥是TiCDC背锅。
凌晨的报警和处理
晚上11点收到多条tikv集群硬盘空间报警,爬起来打开电脑看看到底出了啥问题,一般TiKV使用磁盘空间一般都有下面几个原因:
-
本来硬盘空间就比较紧张,是不是有哪个业务又晚上“偷偷”灌数据了?这种情况一般看下grafana的overview监控就能定位。
-
tikv日志暴涨,之前遇到过集群升级后tikv日志由于静默reigon开启导致的日志量过大。这个看下tikv日志产生情况,如果是日志过量,直接rm日志即可,另外tikv支持配置日志保留策略来自动删除日志。
-
其他情况
本次就是“其他情况”的类型,这个集群本来使用方就多,写入也没有突增啥的,tikv日志也没有啥异常,因为知道是测试集群,所以就是删除了一些2021年的tikv日志先将KV存储降低到80%以内不报警了。
第二天.......
好好收拾下测试TiDB集群,解决Tikv存储问题,靠2种方法:
(1)找资源扩容KV
(2)看看是不是有表过大或者其他异常。
因为是测试集群,不着急直接扩容,万一是有一些大表可以清理下数据啥的,资源就有了。所以我先通过下面的命令来统计库表资源使用情况(不太准,可以参考):
如果不涉及分区表用下面的方式查看表的使用情况:
select TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS,(DATA_LENGTH+INDEX_LENGTH)/1024/1024/1024 as table_size from tables order by table_size desc limit 20;
另外partition表提供了分区表和非分区表的资源使用情况(我们使用分区表较多):
select TABLE_SCHEMA,TABLE_NAME,PARTITION_NAME,TABLE_ROWS,(DATA_LENGTH+INDEX_LENGTH)/1024/1024/1024 as table_size from information_schema.PARTITIONS order by table_size desc limit 20;另外官方也提供了接口来统计table使用情况(比较准确):
tidb-ctl table disk-usage --database(-d) [database name] --table(-t) [table name]先看下SQL的统计结果,我发现有些表都几亿,并且有些表rows为0,竟然也有size,因为我之前经常遇到统计信息的不准导致的tables系统表信息不准的情况,为此,我竟然回收了下集群所有table的统计信息。
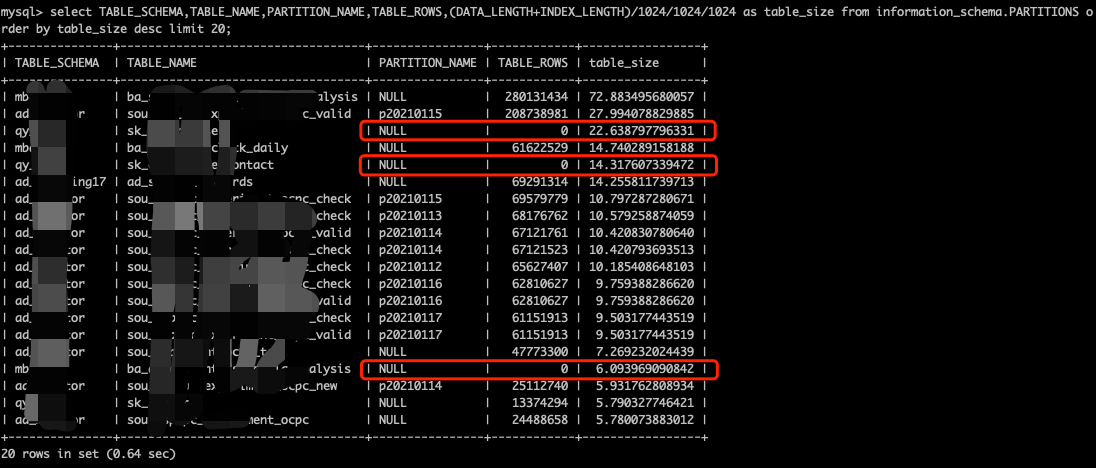
然后做的操作就是跟业务沟通,删除一个没用的分区,或者turncate一些table数据,然后我就等待着资源回收了。但是我都等了半个多小时,在没有多少新写入的情况下,region数量和磁盘空间丝毫没有动静,难道GC出了问题?
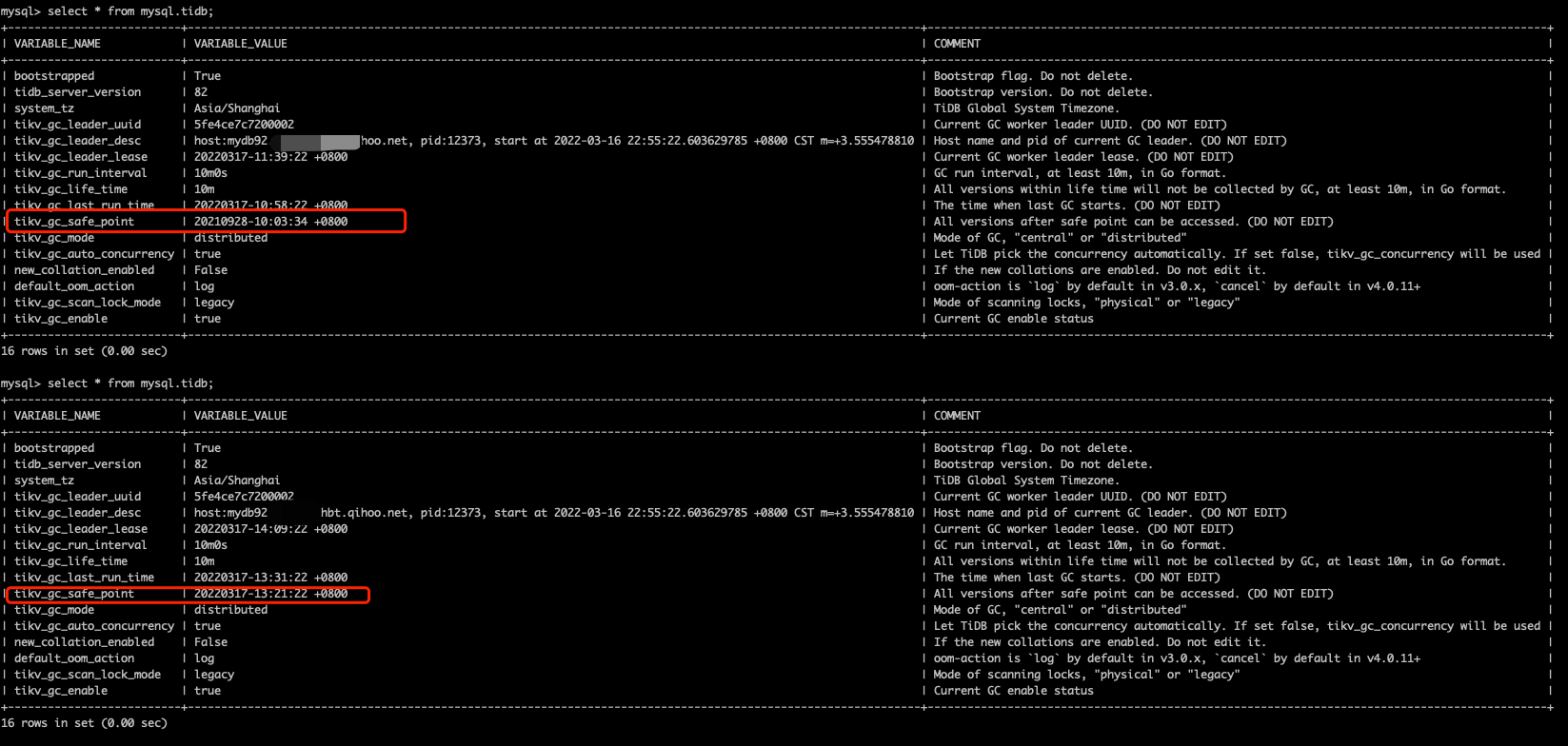
OK,那我就先从mysql.tidb表看下GC的情况,不看不知道,一看吓一跳啊,我的gc-save-point竟然还在2021年的4月份,那集群中到底累积了多少MVCC版本??我的天。
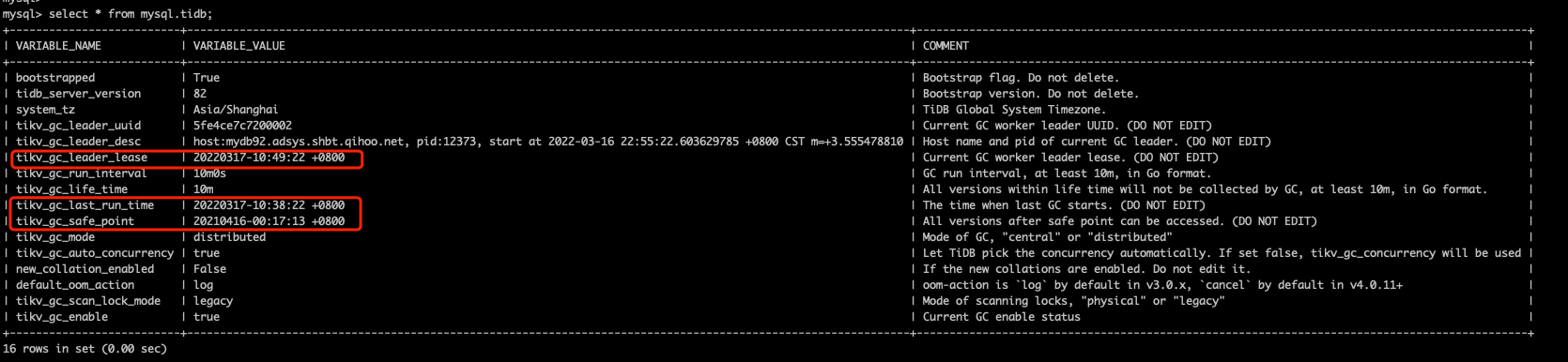
分析和解决GC的问题
通过上图已经可以发现是GC的问题,我们需要找出GC出了什么问题。一般通过日志和监控。先查看tidb server的日志:
{"level":"INFO","time":"2022/03/16 22:55:06.268 +08:00","caller":"gc_worker.go:230","message":"[gc worker] quit","uuid":"5fdb15468e00003"}
{"level":"INFO","time":"2022/03/16 22:55:22.603 +08:00","caller":"gc_worker.go:202","message":"[gc worker] start","uuid":"5fe4ce7c7200002"}
{"level":"INFO","time":"2022/03/16 22:58:22.629 +08:00","caller":"gc_worker.go:608","message":"[gc worker] there's another service in the cluster requires an earlier safe point. gc will continue with the earlier one","uuid":"5fe4ce7c7200002","ourSafePoint":431867062548692992,"minSafePoint":424280964185194498}
{"level":"INFO","time":"2022/03/16 22:58:22.637 +08:00","caller":"gc_worker.go:329","message":"[gc worker] starts the whole job","uuid":"5fe4ce7c7200002","safePoint":424280964185194498,"concurrency":5}
{"level":"INFO","time":"2022/03/16 22:58:22.639 +08:00","caller":"gc_worker.go:1036","message":"[gc worker] start resolve locks","uuid":"5fe4ce7c7200002","safePoint":424280964185194498,"concurrency":5}
{"level":"INFO","time":"2022/03/16 22:58:41.268 +08:00","caller":"gc_worker.go:1057","message":"[gc worker] finish resolve locks","uuid":"5fe4ce7c7200002","safePoint":424280964185194498,"regions":81662}
{"level":"INFO","time":"2022/03/16 22:59:22.617 +08:00","caller":"gc_worker.go:300","message":"[gc worker] there's already a gc job running, skipped","leaderTick on":"5fe4ce7c7200002"}
{"level":"INFO","time":"2022/03/16 23:00:21.331 +08:00","caller":"gc_worker.go:701","message":"[gc worker] start delete ranges","uuid":"5fe4ce7c7200002","ranges":0}
{"level":"INFO","time":"2022/03/16 23:00:21.331 +08:00","caller":"gc_worker.go:750","message":"[gc worker] finish delete ranges","uuid":"5fe4ce7c7200002","num of ranges":0,"cost time":"677ns"}
{"level":"INFO","time":"2022/03/16 23:00:21.336 +08:00","caller":"gc_worker.go:773","message":"[gc worker] start redo-delete ranges","uuid":"5fe4ce7c7200002","num of ranges":0}
{"level":"INFO","time":"2022/03/16 23:00:21.336 +08:00","caller":"gc_worker.go:802","message":"[gc worker] finish redo-delete ranges","uuid":"5fe4ce7c7200002","num of ranges":0,"cost time":"4.016µs"}
{"level":"INFO","time":"2022/03/16 23:00:21.339 +08:00","caller":"gc_worker.go:1562","message":"[gc worker] sent safe point to PD","uuid":"5fe4ce7c7200002","safe point":424280964185194498}
{"level":"INFO","time":"2022/03/16 23:08:22.638 +08:00","caller":"gc_worker.go:608","message":"[gc worker] there's another service in the cluster requires an earlier safe point. gc will continue with the earlier one","uuid":"5fe4ce7c7200002","ourSafePoint":431867219835092992,"minSafePoint":424280964185194498}
{"level":"INFO","time":"2022/03/16 23:08:22.647 +08:00","caller":"gc_worker.go:329","message":"[gc worker] starts the whole job","uuid":"5fe4ce7c7200002","safePoint":424280964185194498,"concurrency":5}
{"level":"INFO","time":"2022/03/16 23:08:22.648 +08:00","caller":"gc_worker.go:1036","message":"[gc worker] start resolve locks","uuid":"5fe4ce7c7200002","safePoint":424280964185194498,"concurrency":5}
{"level":"INFO","time":"2022/03/16 23:08:43.659 +08:00","caller":"gc_worker.go:1057","message":"[gc worker] finish resolve locks","uuid":"5fe4ce7c7200002","safePoint":424280964185194498,"regions":81647}
{"level":"INFO","time":"2022/03/16 23:09:22.616 +08:00","caller":"gc_worker.go:300","message":"[gc worker] there's already a gc job running, skipped","leaderTick on":"5fe4ce7c7200002"}
{"level":"INFO","time":"2022/03/16 23:10:22.616 +08:00","caller":"gc_worker.go:300","message":"[gc worker] there's already a gc job running, skipped","leaderTick on":"5fe4ce7c7200002"}
{"level":"INFO","time":"2022/03/16 23:10:23.727 +08:00","caller":"gc_worker.go:701","message":"[gc worker] start delete ranges","uuid":"5fe4ce7c7200002","ranges":0}
{"level":"INFO","time":"2022/03/16 23:10:23.727 +08:00","caller":"gc_worker.go:750","message":"[gc worker] finish delete ranges","uuid":"5fe4ce7c7200002","num of ranges":0,"cost time":"701ns"}
{"level":"INFO","time":"2022/03/16 23:10:23.729 +08:00","caller":"gc_worker.go:773","message":"[gc worker] start redo-delete ranges","uuid":"5fe4ce7c7200002","num of ranges":0}
{"level":"INFO","time":"2022/03/16 23:10:23.730 +08:00","caller":"gc_worker.go:802","message":"[gc worker] finish redo-delete ranges","uuid":"5fe4ce7c7200002","num of ranges":0,"cost time":"710ns"}
{"level":"INFO","time":"2022/03/16 23:10:23.733 +08:00","caller":"gc_worker.go:1562","message":"[gc worker] sent safe point to PD","uuid":"5fe4ce7c7200002","safe point":424280964185194498}
{"level":"INFO","time":"2022/03/16 23:18:22.647 +08:00","caller":"gc_worker.go:608","message":"[gc worker] there's another service in the cluster requires an earlier safe point. gc will continue with the earlier one","uuid":"5fe4ce7c7200002","ourSafePoint":431867377121492992,"minSafePoint":424280964185194498}通过日志发现GC一直等早期的safe point:424280964185194498
there's another service in the cluster requires an earlier safe point. gc will continue with the earlier one","uuid":"5fe4ce7c7200002","ourSafePoint":431870050977185792,"minSafePoint":424280964185194498查看下该TSO对应的系统时间,发现跟上面mysql.tidb截图的tikv-gc-safe-point对应的时间:2021-04-16 00:17:13一致。
$ tiup ctl:v5.4.0 pd -u http://10.203.178.96:2379 tso 424280964185194498
system: 2021-04-16 00:17:13.934 +0800 CST
logic: 2需要执行 pd-ctl service-gc-safepoint --pd 命令查询当前的 GC safepoint 与 service GC safepoint,发现卡住的 safe point 跟 ticdc 的 safe_point: 424280964185194498 一致。
$ tiup ctl:v5.4.0 pd -u http://10.xxxx.96:2379 service-gc-safepoint
{"service_gc_safe_points": [{"service_id": "gc_worker","expired_at": 9223372036854775807,"safe_point": 431880793651412992},{"service_id": "ticdc","expired_at": 1618503433,"safe_point": 424280964185194498}],"gc_safe_point": 424280964185194498
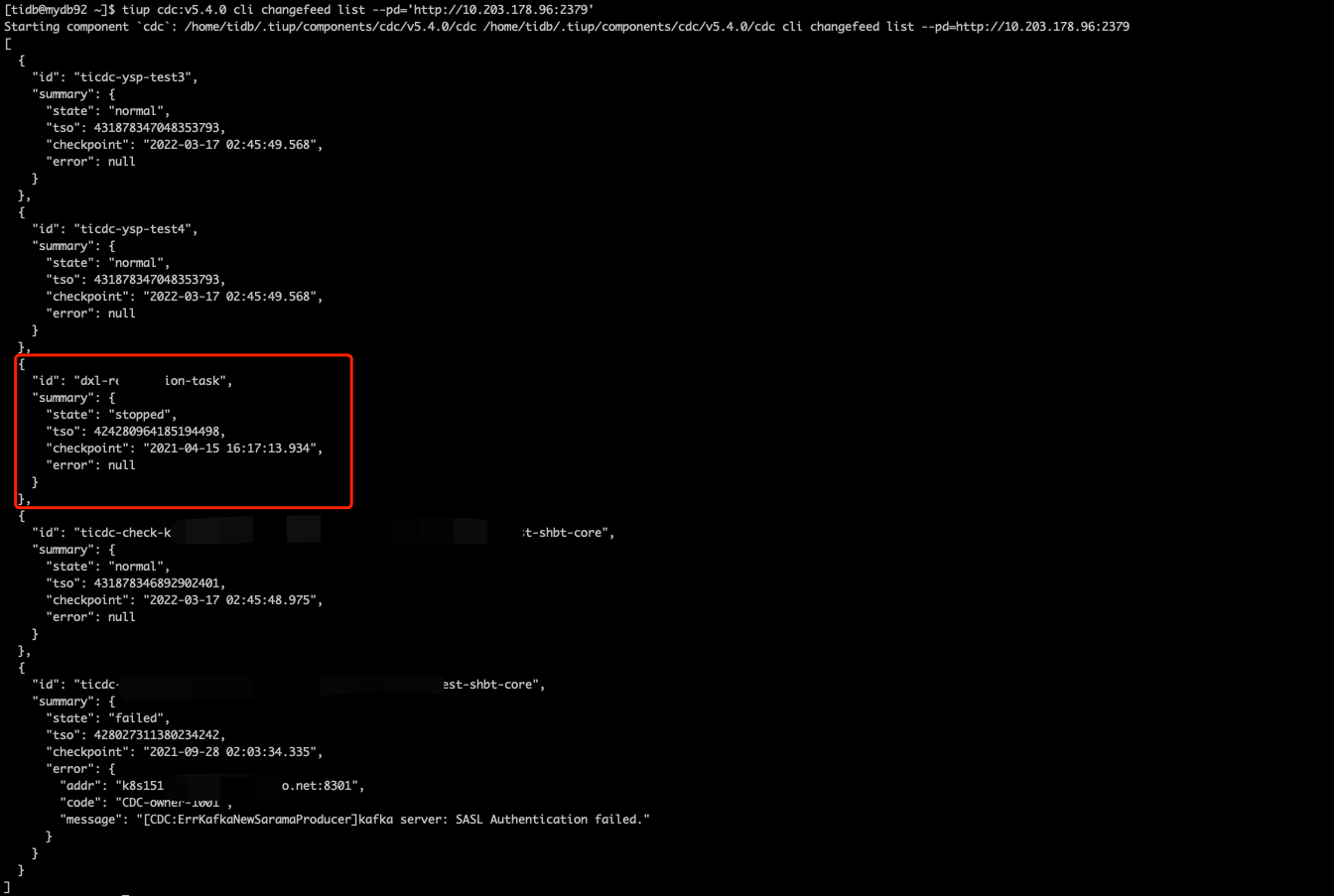
}查看该集群的ticdc任务,发现卡住的safe point跟changefeed id为dxl-xxxx-task这个同步任务的TSO一致:
![]()
到此终于找到GC问题的原因。ticdc同步任务没有及时删除导致的。解决方案:删除ticdc中该同步任务
tiup cdc:v5.4.0 cli changefeed remove --pd='http://10.xxxx.96:2379' --changefeed-id=dxl-replication-task等一段时间观察safe-point的变化,发现已经开始GC:
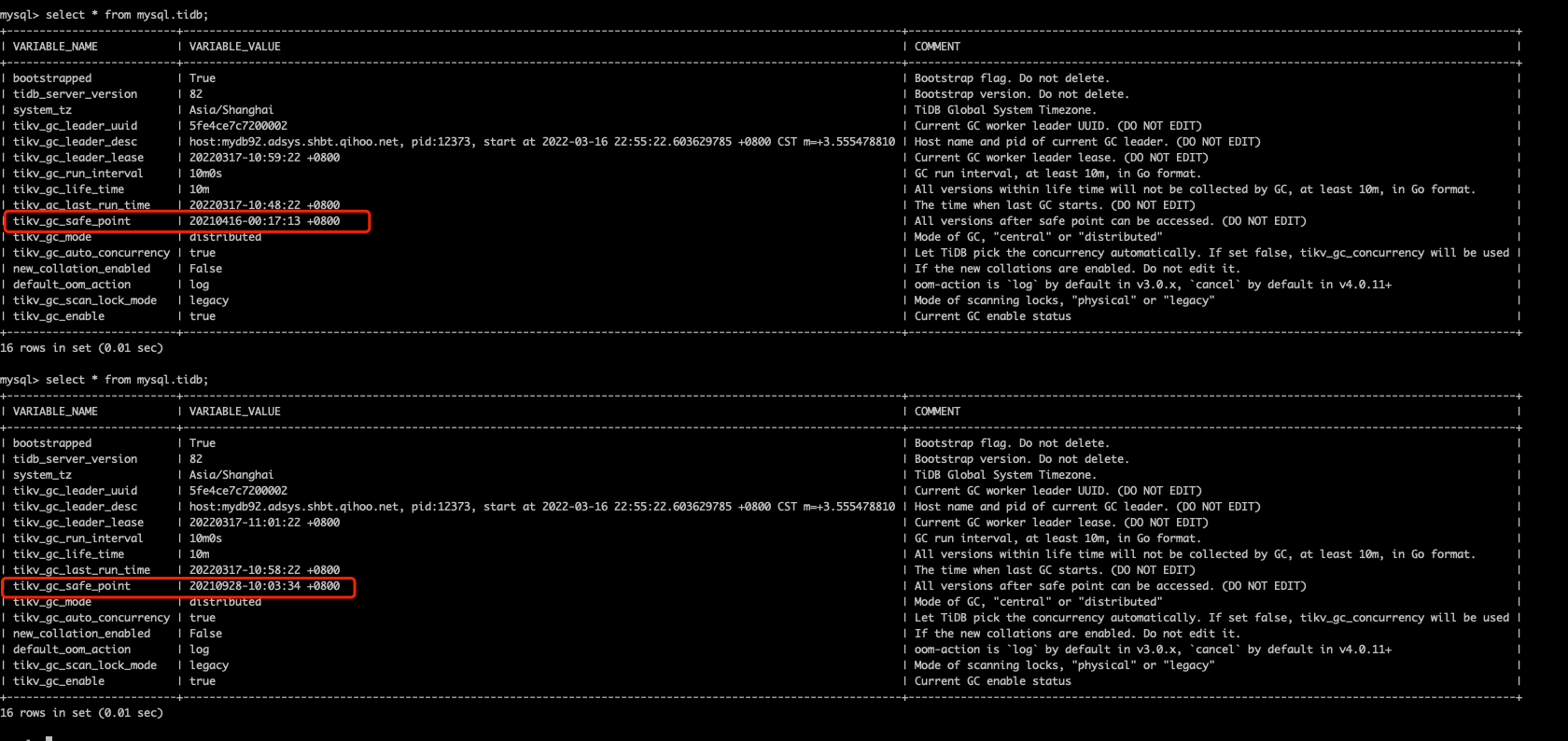
不过又卡在了另一个同步任务(ticdc-demo-xxxx-test-shbt-core)上,继续remove
tiup cdc:v5.4.0 cli changefeed remove --pd='http://10.xxxx.96:2379' --changefeed-id=ticdc-demo-xxxx-test-shbt-core删除后,等待较长时间(几个小时),最终GC safe point恢复正常:
GC回收完毕后单KV存储又之前的800G降低到200G左右,大家也可以从下图中右边的 cf size的监控看出来,write CF从之前的3.2T降低到790G左右,下降的最多,大家知道对于tikv的列簇来说,write cf是存数据的版本信息(MVCC)的,这个的下降也印证了TiCDC导致的MVCC版本过多的问题,现在问题完全解决:

问题虽然解决完毕了,但是Ticdc默认有个24小时的GC hold的时间,超过这个时间,就不会再影响GC,为啥有上面的问题,我也咨询了官方的产研同学:OK,首先定性:”是个BUG“,这个问题在 4.0.13, 5.0.2, 5.1.0 这几个版本中修复了,因为测试集群,版本从3.0一路升级而来,因该是用了老版本踩到了坑,修复 PR见后面的链接: owner: Modified the update strategy of gcSafePoint by asddongmen · Pull Request #1731 · pingcap/tiflow · GitHub
GC原理
虽然讲明白了ticdc->gc->硬盘报警的问题处理,但是我们还需要对GC的原理进行下简单的说明。
TiDB server架构中的GC模块
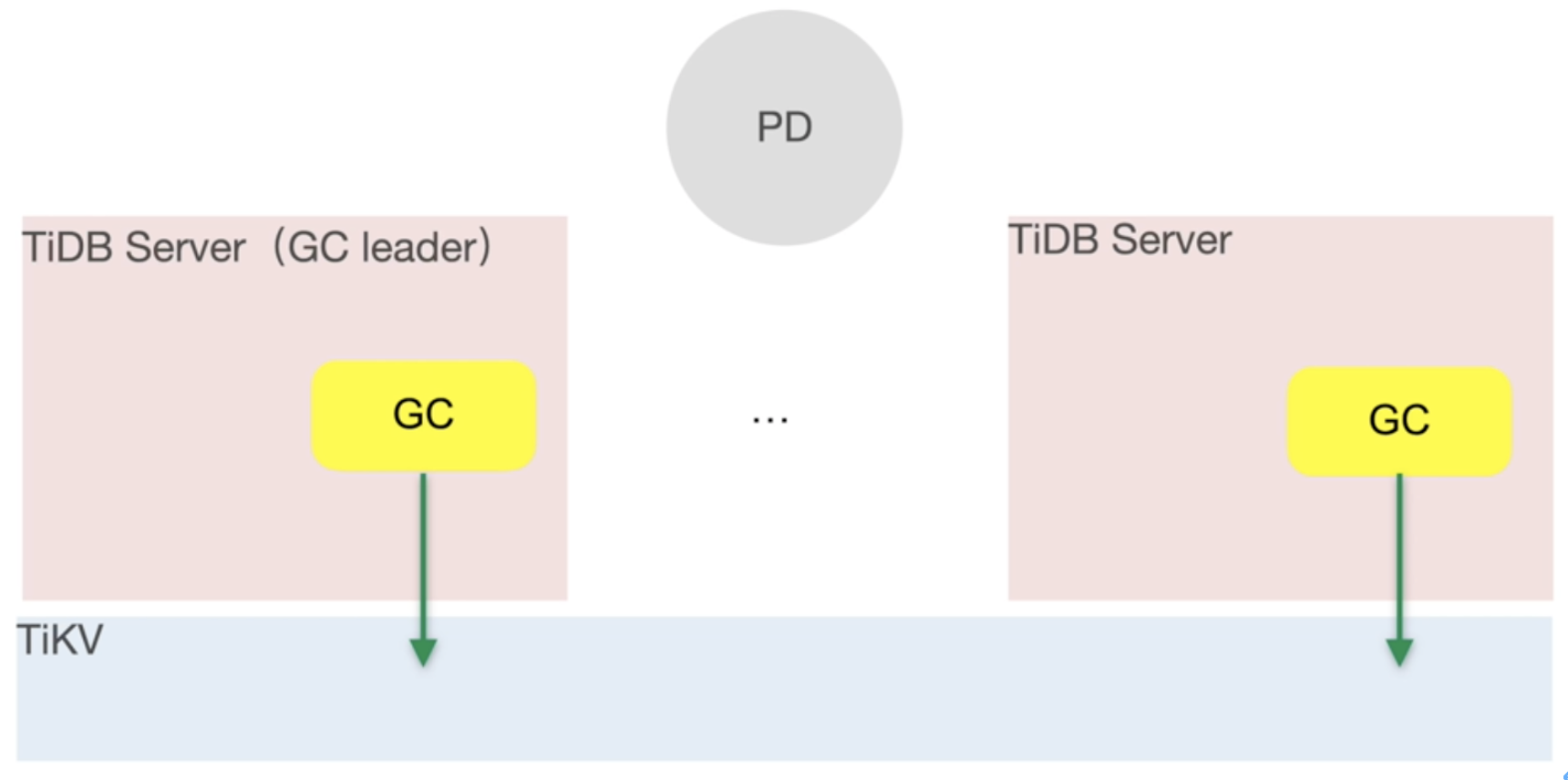
GC作为TiDB Server的模块,主要的作用就是清理不再需要的旧数据。
大家都知道Tikv底层使用是基于LSM的数据架构,这种数据存储的方式在做数据 update 时,不会更新原来的数据,而是重新写一份新的数据,并且给每份数据都给定一个事务时间戳,这种机制也是我们经常提到的 MVCC(多版本并发控制)机制,为了避免同一条记录的版本过多,TiDB设定了一个 tikv_gc_life_time 来控制版本的保留时间(默认10min),并且每经过 tikv_gc_run_interval 这个时间间隔,就会触发GC的操作,清除历史版本的记录,下面详细聊下GC的流程。
GC的流程
GC都是由GC Leader触发的,一个tidb server的cluster会选举出一个GC leader,具体是哪个节点可以查看mysql.tidb表,gc leader只是一个身份状态,真正run RC的是该Leader节点的gc worker,另外GC的流程其实从文章上面的日志可以看出来。
-
(1)Resolve Locks 阶段
从英文翻译过来很直白:该阶段主要是清理锁,通过GC leader日志可以看出,有 start resolve locks;finish resolve locks的操作,并且都跟着具体的safepoint,其实这个safepoint就是一个时间戳,该阶段会扫描所有的region,只要在这个时间戳之前由2PC产生的锁,该提交的提交,该回滚的回滚。
-
(2)Delete Ranges阶段
该阶段主要处理由drop/truncate等操作产生的大量连续数据的删除。tidb会将要删除的range首先记录到mysql.gc_delete_range,然后拿这些已经记录的range找对应的sst文件,调用RocksDB的UnsafeDestroyRange接口进行物理删除,删除后的range会记录到mysql.gc_delete_range_done表。从日志中也可以看到start delete ranges;finish delete ranges的操作。
-
(3)Do GC阶段
这个阶段主要是清理由DML操作产生的大量历史数据版本,因为默认的保留时间为10min,那么我一张元数据表一年都没有更新过,难道也会被清理?不要紧张,GC会对每个key都保留safe point 前的最后一次写入时的数据(也就是说,就算表数据不变化,GC也不会“误清理”数据的)。另外这部分由DML产生的GC,不会马上释放空间,需要RocksDB的compaction来真正的回收空间,对了还可能涉及“大量空region的merge”(如何回收空region的解决方案)。这个阶段的日志有:start redo-delete ranges;finish delete ranges
-
(4)发送safe point给PD,结束本轮的GC。日志为:sent safe point to PD
GC的监控查看
涉及到GC的主要看下面的几个监控即可:
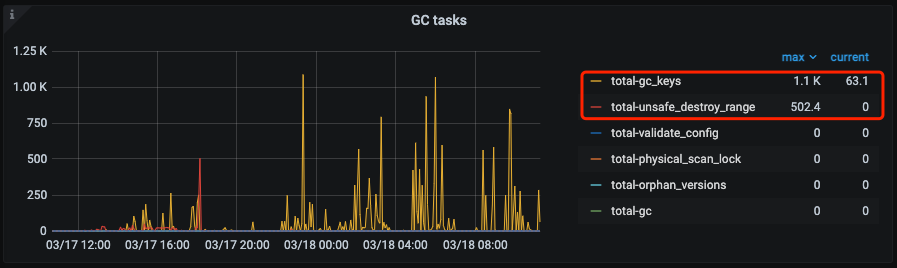
tikv-detail中的GC模块->GC task:跟上文所描述,如果执行了drop/truncate操作就看看下面监控中total-unafe-destroy-range的metric是否有值,另外日常的DML的GC,可以看看total-gc-keys的task情况。
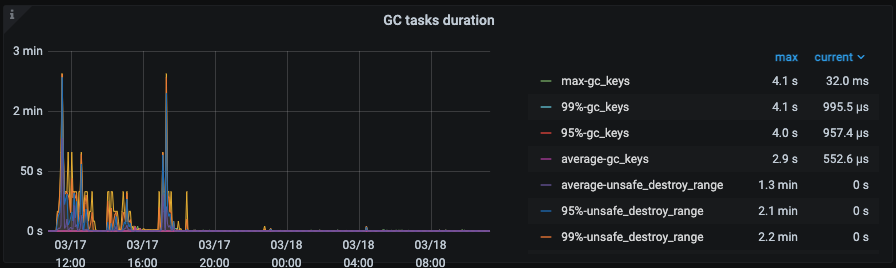
tikv-detail中的GC模块->GC task duration:
不同gc task的删除耗时。
tikv-detail中的GC模块->GC speed:
按照keys/s的旧MVCC版本的删除速度。
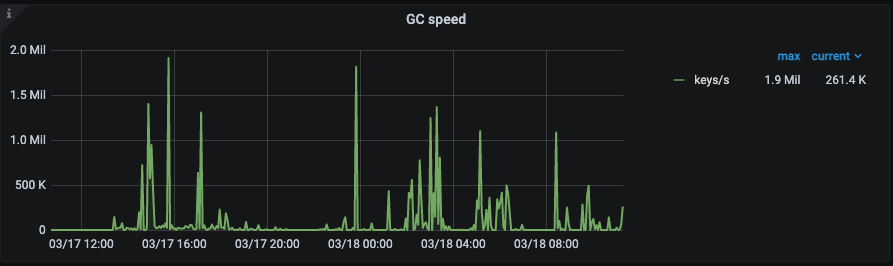
PS:想了解更多的GC内容可以查看官方文档或者详细阅读asktug中坤爷和娇姐写的GC三部曲:第一篇为 『GC 原理浅析』,第二篇为『GC 监控及日志解读』 ,而最后一篇则为『GC 处理案例 & FAQ』。
原文作者:@代晓磊_360 发表于: 2022-03-28
原文链接:https://tidb.io/blog/36c58d32
这篇关于【一场由TiCDC异常引发的GC不干活导致的Tikv硬盘使用问题】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








