本文主要是介绍爬虫 新闻网站 以湖南法治报为例(含详细注释) V1.0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标网站:湖南法治报
爬取目的:为了获取某一地区更全面的在湖南法治报已发布的宣传新闻稿,同时也让自己的工作更便捷
环境:Pycharm2021,Python3.10,
安装的包:requests,csv,bs4
v1.0 版本特点:获取指定页数的新闻数据,筛选出含有想要查找的的关键词的新闻内容,并存储起来。
1 首先分析网页
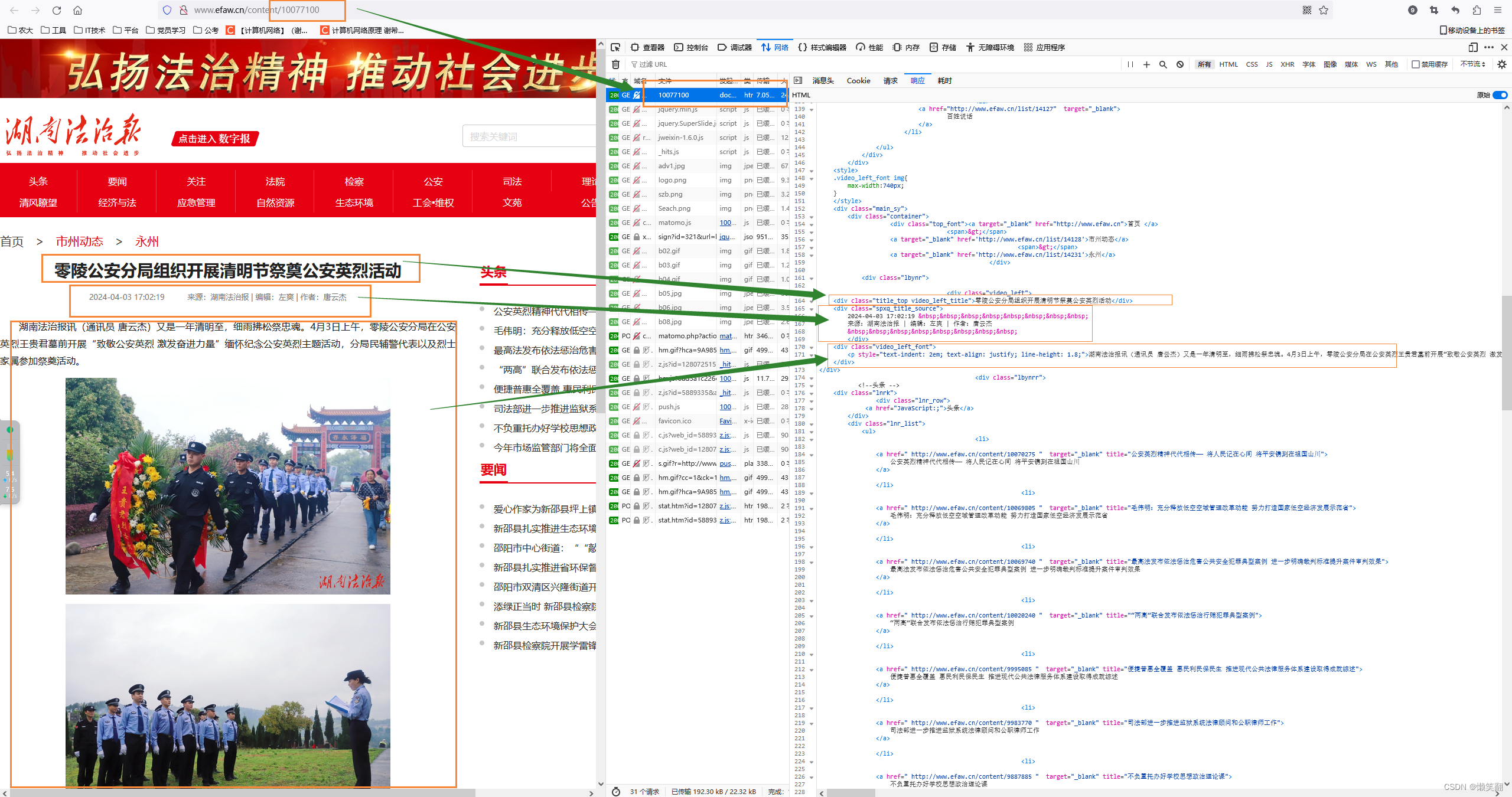
(查看数据返回方式,发现网站不用像红网那样设置各种headers了,可以直接爬)
发现在这个页面只有文章标题和发布时间,以及文章链接的信息(当然文章有图片的就还有图片信息)


2 再看文章内容页面
(像我就只要文字部分就行了,不需要图片)
3 运行结果:
爬虫 新闻网站 以湖南法治报为例 V1.0
4 具体分析和实现请看代码(含详细注释):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/4/4 21:36
# @Author : LanXiaoFang
# @Site :
# @File : efaw.py
# @Software: PyCharm
import csv
import requests
from bs4 import BeautifulSoup# 由于发现湖南法治报没有设置反爬机制,因为我们不用反反爬了,可以直接爬数据了
# 市州动态 下的对应市州的编号
szId = {"长沙": "14129", "株洲": "14130", "湘潭": "14223", "衡阳": "14224", "邵阳": "14225", "岳阳": "14226", "常德": "14227","张家界": "14228", "益阳": "14229", "郴州": "14230", "永州": "14231", "怀化": "14232", "娄底": "14233", "湘西": "14234"}# 输入你想要获取的湖南省下的哪一市州的新闻 比如 湖南省下的永州市,直接输入 永州 即可
sz = "永州"
# 根据输入的湖南省下的市州 得到对应的市州编号 再拼接入链接
url = "http://www.efaw.cn/list/" + szId[sz]
# 输入你想要的关键词 比如 双牌、蓝山、宁远、新田、零陵
search_keyword = '双牌'
# 标题就含有关键词的计数器
title_Yes_Num = 0
# 标题不含有关键词但是内容含有关键词的计数器
title_No_Num = 0
# 新闻来源级别
level = "省级"
"""
爬虫思路:
首先最开始是打开要爬取的网站,然后分析怎样获取需要的数据最完整和便捷
一开始看到搜索其实是想直接搜关键词获取新闻的,但是发现通过搜索框获得到新闻数据不如市州动态下的全面,所以还是打算一条一条新闻比对是否符合自定义关键词
1 首先进入市州动态获取到某市州动态下的所有新闻数据
2 根据具体新闻链接进入新闻页面,获取到新闻信息
"""# # 创建CSV文件并写入头部信息
with open(search_keyword + '湖南法治报_标题含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源']) # 根据实际情况定义列名
with open(search_keyword + '湖南法治报_标题不含内容含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源']) # 根据实际情况定义列名# http://www.efaw.cn/list/14231?page=1
page = 1
while page <= 20: # 从这里修改数字以控制要多少页的新闻内容,,page<=20page从1开始一直到20# 拼接出每一页的urlurl_page = url + "?page=" + str(page)html_all = requests.get(url_page)html_all.encoding = 'utf-8'print(page, '页', url_page)if html_all.status_code == 200:soups = BeautifulSoup(html_all.text, 'html.parser')article_info = soups.find_all('ul', class_='list_content')for i in article_info:result_info = i.find_all('div')for art in result_info:article_href = art.a.get('href') # 文章链接print(article_href)article_title = art.a.get('title') # 文章标题article_time = art.i.text # 文章发布时间 显示为:发布时间:2024-04-02 10:08:03# 因为只要年月日部分的时间,因此把一些不需要的字符去掉article_time = article_time[2+article_time.index('间:'):]article_time = article_time[:article_time.index(':')-2]# 从文章内容中获取到来源html_article_info_sk = requests.get(article_href)html_article_info_sk.encoding = 'utf-8'if html_article_info_sk.status_code == 200:soups_sk = BeautifulSoup(html_article_info_sk.text, 'html.parser')article_info_sk = soups_sk.find_all('div', class_='video_left')# 其实在这里我想获取到具体的来源,这一段因为在新闻详情页面,如果 来源 为 双牌县优化办 ,那么这条新闻就是优化办推过去的spxq_title_source = soups_sk.find('div', class_='spxq_title_source').text# 文章信息来源 显示为: 来源:湖南法治报atricle_source = spxq_title_source[spxq_title_source.index('来源:')+3:spxq_title_source.index('|')]# 在这里可以从标题判断是否含有搜索的关键词search_keyword,如果有则可以直接存储这条新闻信息,如果没有则继续查看新闻内容,看是否含有关键词信息if search_keyword in article_title: # 标题判断含有搜索的关键词search_keywordtitle_Yes_Num += 1with open(search_keyword + '湖南法治报_标题含关键词.csv', 'a', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_Yes_Num, article_title, "湖南法治报", level, article_time, article_href, atricle_source])print("Yes Tile have SK !!!!!", title_Yes_Num)print(title_Yes_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href, 'source:', atricle_source)else: # 标题判断不含搜索的关键词search_keywordif search_keyword in article_info_sk:title_No_Num += 1with open(search_keyword + '湖南法治报_标题不含内容含关键词.csv', 'a', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_No_Num, article_title, "湖南法治报", level, article_time, article_href, atricle_source])print("Yes Content have SK !!!!!", article_info_sk)print(title_No_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href, 'source:', atricle_source)page += 1
这篇关于爬虫 新闻网站 以湖南法治报为例(含详细注释) V1.0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







