本文主要是介绍2 Spark机器学习 spark MLlib Statistics统计入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
spark中比较核心的是RDD操作,主要用于对数据的处理、转换。
在机器学习中,数据的处理也非常重要,矩阵、统计什么的都很常见。这一篇看一下Statistics统计相关的操作。
本系列文章是边看书学边写,书是看的黄美灵的spark mllib机器学习。我会抽取比较靠谱的有用的知识写成文章。
MLlib Statistics是基础统计模块,能对RDD数据进行统计,包括汇总统计、相关系数、分层抽样、假设检验、随机数据生成等。
1 列统计
假如我们有个文件,有很多行和列,现在需要对各列做个统计分析,看看每列的最大最小值平均值什么的。
文件内容如下:
12 3 4 5
57 1 5 9
35 6 3 1
31 1 5 6代码如下:
package statisticsimport org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.Statistics
import org.apache.spark.{SparkConf, SparkContext}object ColStats {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("simple").setMaster("local")val sc = new SparkContext(conf)val data_path = "/users/wuwf/spark1"val data = sc.textFile(data_path).map(_.split(" ")).map(f => f.map(f => f.toDouble))//转成RDD[Vector]val data1 = data.map(f => Vectors.dense(f))val stat1 = Statistics.colStats(data1)println(stat1.max)println(stat1.min)//平均值println(stat1.mean)//方差值println(stat1.variance)//L1范数println(stat1.normL1)//L2范数println(stat1.normL2)}}
直接运行后结果如下:
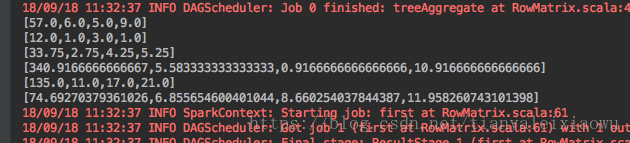
对比注释,可以看看代码的功能。
上面我们将原始RDD转为了RDD[Vector]形式的变量data1,我们对data1进行collect操作,就变成了Array[Vector]的形式。可以来打印看看里面的值:
for(i <- data1.collect()) {println(i)}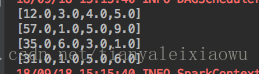
2 相关系数
相关系数表达的是两个数值变量的线性相关性,一般适用于正态分布。取值范围是[-1, 1],取值为0代表不相关,取值为(0,-1]代表负相关,取值为(0,1]代表正相关。
譬如房屋面积很多时候就和房价成正相关的关系。
用来描述相关系数的主要有皮尔森(pearson)相关系数和斯皮尔曼(spearman)相关系数。
拿代码来看一下:
val corr1 = Statistics.corr(data1, "pearson")val corr2 = Statistics.corr(data1, "spearman")println(corr1)println(corr2)val x1 = sc.parallelize(Array(1.0, 2.0, 3.0, 4.0))val y1 = sc.parallelize(Array(5.0, 6.0, 6.0, 6.0))val corr3 = Statistics.corr(x1, y1, "pearson")println(corr3)看结果:
corr1是:

corr2是:

corr3是:
相关系数根据输入类型的不同,输出的结果也产生相应的变化。如果输入的是两个RDD[Double],则输出的是一个double类型的结果;如果输入的是一个RDD[Vector],则对应的输出的是一个相关系数矩阵。
corr3的输出就是一个double型,0.77属于正相关,我们可以比较明显的看到y1的值随着x1的值增大而增大,或持平。我把y1的数据改成5.0, 10.0, 15.0, 20.0时,结果就会变成0.9999.也就是完全正相关了。
再看corr1和corr2,都是矩阵型的,那么里面的相关系数是怎么算的呢,里面的每一项都代表谁跟谁的相关系数?
答案是:相关矩阵第i行第j列的元素是原矩阵第i列和第j列的相关系数。
看起来有点抽象是吗,我们来看看corr1的矩阵,发现矩阵的对角线数据都是一样的,右斜线都是1。这该怎么解释呢?

我们来取第一列和第二列的值,来做一下相关性计算。发现结果是:
可以看到刚好就是结果矩阵里的1行2列和2行一列。再对照上面红字的话就能明白了,-0.28就是第一列和第二列的相关系数,当然了第二列和第一列的相关系数自然相同。而为1的那些数据,自然就是本列和本列的相关系数了。
那么这玩意的作用是什么呢?
在机器学习里,我们经常会有一个label列,譬如房价,又有很多个属性列,譬如面积、位置、装修什么的。那么我们就能通过上面的相关系数,比较直白的看到,都有哪些列与房价的关系成正相关、负相关。
这篇关于2 Spark机器学习 spark MLlib Statistics统计入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








