本文主要是介绍【电商API数据采集接口接入】如何搭建电商数据指标体系?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01
什么是好的数据指标?

电商商品数据采集API接口接入
01
前言
做数据分析的工作已经将近6年了,形形色色的业务方也合作了不少。大部分业务方都给我一个感觉就是我什么数据指标都要看,越多越多好,即使看了这些指标之后什么事情也干不了。业务方可能心里所想,看越多的数据指标就是越重视数据,越是在做数据驱动增长的事情,我没有功劳也有苦劳。有句话的说的很好,“你不能用战术上的勤奋来掩盖战略上的懒惰”,就非常贴切了描述了这种现象。
在工作两三年之后就一直在思考,业务方该去看什么数据指标,什么样的数据指标能真正指导业务方干活,指导业务朝着正确的方向前进,慢慢的心中有了一些答案。但是一直不能很好的抽象总结出来,一直是一种朦朦胧胧的感觉,自己能明白什么样的指标是好的数据指标,但是不能输出告诉别人该如何去判断数据指标的好与坏。直到有一天看了《精益数据分析》这本书,突然有种醍醐灌顶的感觉,作者阿利斯泰尔·克罗尔很好的抽象总结了他对于数据指标的理解,这不正是我心里那种对数据指标的理解吗,仿佛一下子打开了我的任督二脉。过往工作中的种种对数据指标的种种认知一下子就与其对应起来了,每个问题都是感同身受。内心不禁感慨作者真的太牛逼了,同时内心还多了一些感悟,看书的时机真的很重要,如果在早个一两年看到这本书,可能就当成一本工具书读完就结束了,再过段时间可能就完全不记得里面的内容了。读书,需要与作者共鸣。共鸣的一个前提,也须“感同身受”,也就是真的经历过类似的事情。
下文关于数据指标的阐述都是基于《精益数据分析》这本书中关于数据指标的描述,以及根据工作经历对于书中方法论的个人见解。
02
好的数据指标的衡量准则
好的数据指标是能带来你所期望的变化。
如何理解这句话呢,好的数据指标能指引大家朝着正确方向去迭代,每个部门的都是朝着一个共同的目标协作前行,最终经过不断的优化后,业务就会慢慢变成一开始理想中的你希望它成为的样子。
好的数据指标是比较性的。如果能比较某数据指标在不同的时间段、用户群体、竞争产品之间的表现,你可以更好地洞察产品的实际走向。“本周的用户转化率比上周高”显然比“转化率为2%”更有意义。
好的数据指标是比较性的。
其实真正的意思是需要有一个基准值去对比这个数据指标的数值,要不然单纯的一个昨天的销售额是xxx是没有任何意义的。比如,今日公司的销售额是1000W,假如你是一个刚入职的运营,你看到这个数字的脑海中是没有任何概念的。那如果再告诉你过去30天日均的销售额是800W,那你就会觉得今日的销售额还蛮不错的嘛,较过去有一个比较大的增长。那如果再告诉你今日是双十一开始的第一天,去年的今日的销售额是2000W,那你是不是瞬间觉得今日的销售额1000W并不好,双十一理论上就应该有较大的增长,并且跟去年同期比下降了一半。那如果再告诉你公司对今日销售额的目标是900W,公司今年是大力发展新业务,流量投放和商品产能都优先给新业务,你拿到的资源是比较低的,但是超额完成了目标,那你是不是又觉得今日1000W的销售额非常不错了。这就是告诉我们仅仅告诉我们一个数据指标的绝对值,只能说明当下的一个现行状态,没有一个可与之对比的基准值,是很难成为你判断的依据的,而且很可能被数据指标所蒙蔽。
好的数据指标是简单易懂的。如果人们不能很容易地记住或讨论某指标,那么通过改变它来改变公司的作为会十分困难。
好的数据指标是简单易懂的。
事物的本质都是简单的,那如果是一个好的数据指标必将是能反映业务的本质,那么它也必定是简单的。并且在公司里越是高层就会越忙碌,会被各种各种的事情所牵绊着,他们来理解你的数据指标的时间就也越少,如果你不能在有限的时间里让对方理解你数据指标的含义,那么他很可能就不愿意再第二次花时间听你讲解,你也就是错过了这次机会,越是高层越是没有耐心,并不是因为他们的脾气很差,而是他们的时间真的很宝贵。或者一个很复杂的数据指标,当下你已经让对方理解了,但是复杂的东西往往容易忘记,那么下次对方也不愿意再去回忆了,人往往都是惰性的,他内心会认为这个东西肯定是不重要的。
好的数据指标是一个比率。会计和金融分析师仅需迅速查看几个比率就能对一个公司的基本状况做出判断。你也需要几个这样的比率来为自己的创业公司打分。
好的数据指标是一个比率。比率之所以是最佳的数据指标,有如下几个原因。
-
比率的可操作性强,是行动的向导。比如以电商业务的销售为例,销售额只是透露出你得当前的收入是多少,并不知道你这些收入是花了多少成本带来的,有可能每收入1块你就要倒贴1毛钱,但是你还不知道这个情况,还是加大促销力度提高销售额以带给你虚假繁荣的满足。那么毛利率就很好的体现出公司创造增值的能力,那你就能轻松的根据这指标去调整你的策略。
2. 比率是天生的比较性指标。如果将日数据与一个月的数据相比较,你会得知该数据当前所经历的是一个短期的突跃,还是一个长期的渐变。再以销售为例,毛利率是一个数据指标,只有将当前的毛利率和过去30天的平均毛利率进行比较,你才能发现的你的增值能力是在提升还是下降
3. 比率还适用于比较各种因素间的相生和相克(正相关和负相关)。就开车而言,单位时间内行驶的里程(车速)/罚单数这个比率显示了二者的关联性。你开得越快,单位时间内行驶的里程就越多,但收到的罚单也越多。这个比率可以帮你决定是否应该超速。
好的数据指标会改变行为。这是最重要的评判标准:随着指标的变化,你是否会采取相应的举措?
好的数据指标会改变行为。
这个是特别重要但是也是最容易被忽视的点。业务方很可能就是我这个数据指标也要看,那个数据指标也要看。虽然我看了之后并不会让我的接下去的运营动作有改变,但是我就是觉得该看。这个是数据分析师在日常工作中最容易的碰到的问题,如果不改变业务方的这个观念,那么你将一直是名取数机器人,永远沉沦在业务方无休止的取数需求中,不能做有意义的业务分析。如果看了一个数据指标,不管他是涨还是跌,你作为一名业务方,你将不会有任何的改变,那么这个数据指标对你是毫无意义的,人的精力是有限的,不能浪费精力在这个无意义的数据指标上。你可以尝试一个月不去看这个数据指标,你就会发现业务没要丝毫的变化,那么你就应该立马放弃这个数据指标。真正去关心哪些稍微风吹草动你就立马就会有与之对应的决策的核心数据指标。
03
五种数据指标的特点
定性指标与定量指标
定性指标通常是非结构化的、经验性的、揭示性的、难以归类的;量化指标则涉及很多数值和统计数据,提供可靠的量化结果,但缺乏直观的洞察。在目前互联网高度发展的今天,数据的建议已经越发的完整,所以大部分获取的数据都是定量的数据,并且是在海量用户行为中记录的数据,基本上具备统计学意义。但是在创业初期,数据建设可能比较落后,很多数据需要用户调研、采访结果、周围观察等方式获取,那么这些数据都是很强的主观意愿,你需要识别背后真正的意思,才能得出有意义的定性结论。
虚荣指标与可付诸行动的指标
虚荣指标看上去很美,让你感觉良好,却不能为你的业务带来丝毫改变。相反,可付诸行动的指标可以帮你遴选出一个行动方案,从而指导你的运营动作。
很多公司都声称自己是由数据驱动决策的企业。可惜,它们大多只重视这句口号中的“数据”,却很少有公司真的把注意力集中在“驱动决策”上。如果你有一个数据,却不知如何根据它采取行动,该数据就仅仅是一个虚荣指标。它毫无意义,唯一的作用是让人自我膨胀。你需要利用数据揭示信息,指明方向,帮助你改进商业模式,决策下一步的行动。
比如“总注册用户数”(或“总用户数”)其实就是一个虚荣指标,这个数字只会随着时间增长(经典的“单调递增函数”)。它并不能传达关于用户行为的信息:他们在做什么?是否对你有价值?他们中的很多人可能只是注册了一下,就再没有使用过。再比如“商品曝光次数”也是一个虚荣指标,在一个feed流里一个屏幕可能就展示了10个商品,就算曝光了10次,再划上划下几次就翻了好几倍。所以这个指标根本无法体现你的流量的真实繁荣度。
那如果你关注“每日新增注册用户数”这个指标,那就是能直接指导你干活的指标,如果每日新增数量下降了,那你可能就需要加大投放的力度了,并且可以测试不同投放渠道的效果,选择ROI最高的那个渠道进行投放。再比如你关注的“每日活跃用户数”即DAU,这个代表的当下有多少用户还是体验的产品,这个是一个动态平衡的效果,每天有很多人成为新的用户,每天也有很多人成为流失用户,如果每天新增大于流失,那么你的产品的是一个仍然有竞争力的产品,业务在继续向上发展,健康迭代。那如果是流失用户数大于新增用户数,那么说你的产品不在吸引用户,需要尽快找到问题,迭代产品,重新走上正轨。
探索性指标与报告性指标
探索性指标是推测性的,提供原本不为所知的洞见,帮助你在商业竞争中取得先手优势。报告性指标则让你时刻对公司的日常运营、管理性活动保持信息通畅、步调一致。
美国前国防部长唐纳德·拉姆斯菲尔德说:世界上的事物可以分为这样几类:我们知道我们知道的,我们知道我们不知道的;此外,还有我们不知道我们知道的,以及我们不知道我们不知道的。
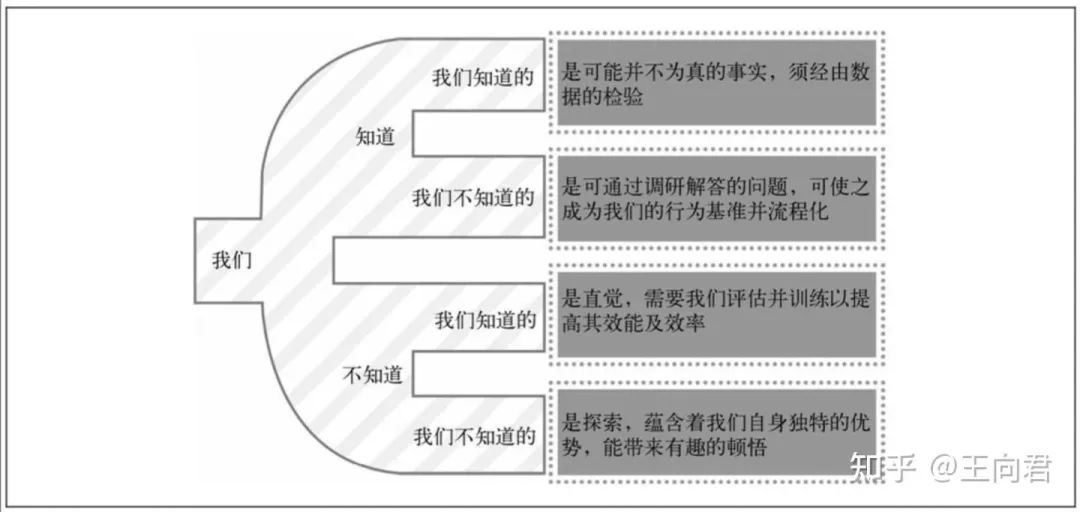
唐纳德·拉姆斯菲尔德的见解
探索性指标可以理解为不是日常观察的,是需要我们去做深度分析发现业务中蕴含着我们目前所不知道的内容,这些是不发现不会“死”,但是一旦发现就会给业务带来增量的东西。那报告性指标就是我么每日或者每周或者每月都需要去看注意的指标,他反映的业务宏观上的表现,比如对于电商业务来说,销售额、购买人数、毛利额等这些每日都观察是的指标,他能体现出你当前业务的健康情况,是否有在增长,有点类似财务性指标,你说这个指标不重要吗,不!其实他很重要,但是它不能直接指导你干活。但是如果你一段时间内业务运营不好,就会在这些指标上体现出来。因此报告性指标就是日常监控的宏观性指标,不直接指导你干活,探索性指标就是分析报告的产物,能让你发现一些新的增长点或者发现一个当前业务中存在的问题。
先见性数据指标与后见性数据指标
先见性指标用于预言未来;后见性指标则用于解释过去。相比之下,我们更喜欢先见性指标,因为你在得知数据后尚有时间去应对——未雨绸缪,有备无患。
先见性指标(或称先见性指示剂)可用于预测未来。比如这个月新增注册用户数为30W,那么你接下去的这段时间能转化为购买用户数封顶也就是只有30W。再比如电商购买漏斗分析,曝光商品的用户有10W,那么你能让用户去点击的人数最多也就10W,再能转化为购买的用户又是比点击用户还要少。先见性指标可以帮你预见这个事情的天花板是多少,可以判断这个事情的价值大致有多大。
后见性指标能提示问题的存在,比如用户流失(即某一时间段内离开某产品或服务的客户量);不过等到收集相关数据,找出问题,往往为时已晚,已流失的用户不会再回头。但是用户流失之前总有些征兆,比如这段时间的客户投诉率有所提升,商品的退货退款的比例也激增,这时候肯定存在某些问题,导致用户体检变差了,你需要去找到这些问题并且改善他。那这2个指标就可以做流失用户的先见性指标去持续观察,并且持续优化以降低这些负面的指标,这样就可以提前预防用户流失,从而低价了流失用户数这个指标,也不必到用户真的流失了才开始挽回。
相关性指标与因果性指标
如果两个指标总是一同变化,则说明它们是相关的;如果其中一个指标可以导致另一个指标的变化,则它们之间具有因果关系。如果你发现你能控制的事(比如播放什么样的广告)和你希望发生的事(比如营收)之间存在因果关系,那么恭喜你,你已拥有了改变业务发展状况的能力。
相关性和因果性是在日常业务当中最容易搞错的2种指标。再议电商业务为例,我们发现愿意评价的人复购的比例更高,那我们可以认为是用户评价导致的用户复购吗。其实并不是,愿意评价的只是一个帮我们从一群购买用户中找到质量更高、更加信任我们电商平台的用户,往往愿意复购的用户是高质量的用户,一般更加愿意来评价我们的商品,所以他们并不是因果关系而是相关关系。再比如,冰激凌的消费量和意外溺亡人数具有相关性,难道这意味着我们应该禁止销售冰激凌来避免意外溺亡吗?或者以冰激凌销售量预测殡仪馆的股价走势?当然不是:冰激凌消费和意外溺死率的升高都是因为夏天来了。
在两个数据指标之间发现相关性不是一件坏事,发现相关性可以帮助你预测未来,而发现因果关系意味着你可以改变未来。通常,因果关系并不是简单的一对一关系,很多事情都是多因素共同作用的结果。
很多时候业务十分复杂,当然去探寻业务的因果关系很重要价值也很高,但是往往寻找因果关系需要有极高的成本,对应的ROI很可能比较低。这时候你找到一些相关性指标,并且持续优化他们,最终你希望的业务结果也确实变好了,虽然你可能都不知道为什么这样能使得业务变好。但是没关系,对于实际业务来说,不管是黑猫还是白猫,只要是能抓老鼠的就是好猫。在无法找到或者找到因果关系的指标成本极高的情况下,勇敢大胆的去使用相关关系的数据指标吧,它也能帮助你提高你所期望的业务效果。
这篇关于【电商API数据采集接口接入】如何搭建电商数据指标体系?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






