本文主要是介绍协程库-协程调度器类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
重要概念
caller线程
"caller线程"是指调用协程调度器的线程。
在多线程编程中,每个线程都可以看作是一个独立的执行流,它可以执行函数、方法或其他任务。当一个线程(caller线程)调用协程调度器来管理和执行一系列协程时,这个线程就被称为caller线程。
caller线程可以加入协程调度工作,意味着调度器可以利用已经存在的线程(即caller线程)来执行协程任务,而不必创建新的线程。这样做的好处是可以减小线程切换的开销,提高调度效率。
例如,在一个程序的主函数(如C/C++中的main函数或Python中的主执行块)中定义并运行协程调度器,那么主函数所在的线程就是一个caller线程。调度器可以直接在这个线程上运行协程,而无需额外创建新的线程。这种方式在某些情况下可能更为高效,尤其是在调度协程数量不是非常多,或者希望减少线程管理复杂性的场景下。
调度协程切换
情况1:使用caller线程,线程数为1,且use_caller为true,对应只使用main函数线程进行协程调度的情况。
情况2:不使用caller线程,线程数为1,且use_caller为false,对应额外创建一个线程进行协程调度、main函数线程不参与调度的情况。
情况一:使用caller线程
没有额外的线程进行协程调度,那只能用main函数所在的线程来进行调度。
以下三类协程:
- main函数对应的主协程
- 调度协程
- 待调度的任务协程
在协程调度的上下文中,任务通常被封装在协程中,并被添加到调度器的任务队列中。调度器负责管理这些任务协程的执行顺序和时机。当调度器决定运行某个任务协程时,它会将执行权切换到该协程,让它执行其包含的操作。任务协程在执行完毕后,执行权会再次切换回调度协程,以便调度器可以继续管理下一个任务的执行。
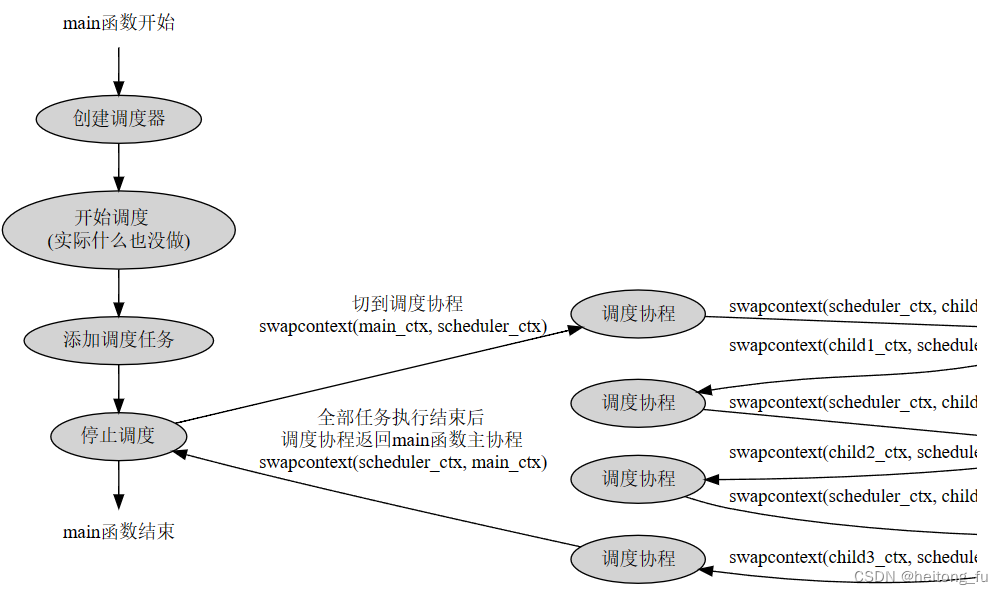
main函数线程任务协程的运行顺序:
1、 main函数主协程运行,创建调度器。
main函数主协程运行,向调度器添加一些调度任务(这些任务就是待调度的任务协程,main函数主协程攒一波任务协程)。
2、开始协程调度,main函数主协程让出执行权,切换到调度协程,调度协程从任务队列里按顺序执行所有的任务协程(任务调度:先来先服务)。
3、每次执行一个任务协程,调度协程都要让出执行权,再切换到该任务协程里去执行,任务执行结束后,还要再切换回调度协程,继续下一个任务的调度。
4、所有任务都执行完后,调度协程还要让出执行权并切换回main函数主协程,以保证程序能顺利结束。
情况二:不使用caller线程
创建额外的线程用于协程调度。
创建新的线程用于协程调度,只需要让新线程的入口函数作为调度协程,再从任务队列里取任务执行,main函数与调度协程完全不相关,main函数只需要向调度器添加任务,然后在适当的时机停止调度器即可。当调度器停止时,main函数要等待调度线程结束后再退出。

思考1:main函数线程主协程会给任务队列添加任务,而负责调度的线程调度协程会从任务队列里取出任务执行,会出现竞态吗,如何解决??
协程相较于线程,其设计为“协作式”并发,即在任意时刻只有一个协程拥有运行权,其余协程处于暂停状态直到被调度器唤醒并交还控制权。这种机制减少了线程切换的开销,并且理论上避免了竞态条件的发生,因为控制权的转移是在一个协程主动让出之后才进行。总的来说,虽然协程设计上避免了竞态条件的可能性,但在实际应用中,如果有多个线程(即使是一个用于协程调度和一个用于添加任务)同时操作共享资源,仍然需要采取同步措施来防止竞态条件。
使用互斥锁(Mutexes)或锁(Locks):对于共享资源,使用互斥锁来确保在同一时间只有一个协程可以访问该资源。当一个协程试图进入临界区时,如果另一个协程已经锁定了互斥锁,它将被阻塞直到锁被释放。
思考2:main函数为什么要等待调度线程结束后再退出??
1、确保任务完成:main函数负责启动协程调度器并添加任务到任务队列。如果main函数提前退出,而调度线程还在运行,那么已经添加到队列中的任务可能不会被执行,或者正在执行的任务可能会被中断,从而导致程序行为不正确或资源未能正确释放。
2、程序稳定性:等待调度线程结束可以确保所有协程都已经完成执行,这样可以避免程序在仍有协程运行时意外终止,保证程序的稳定性和可靠性。
3、资源清理:协程在执行过程中可能会申请资源,如内存分配、文件打开等。等待调度线程结束可以确保这些资源得到妥善的释放,避免资源泄露。
4、同步机制:在某些情况下,main函数可能需要等待协程执行的结果,或者需要根据协程执行的结果来做进一步的处理。等待调度线程结束可以确保同步机制的正确性。
5、避免僵尸进程:如果在主线程退出后还有子线程在运行,这些子线程将成为孤儿进程,由操作系统接管。这可能会导致不可预测的行为,因此最好的做法是确保所有线程在主线程退出前都已经结束。
协程状态
idle
在计算机编程中,“idle” 通常指的是系统或程序中的空闲状态。
当一个协程调度器没有任务可以调度时,它可能会进入所谓的 "idle"状态。在计算机编程中,尤其是在多任务或多线程环境下,调度器负责决定哪个任务或协程接下来要运行。如果所有任务都处于等待状态或者已经完成,调度器就会处于空闲状态,这时它需要决定如何处理这种无任务可执行的情况。
在一些协程框架中,例如提到的sylar框架,处理空闲状态的一种简单方法是让调度器进入一个循环,不断检查是否有新任务到来。这个循环被称为忙等待(busy waiting),因为它会让CPU不断地执行检查,而不是停下来休息。这就像你不断转动手机,等待新的消息通知一样,虽然这样做很耗电(在计算机中则是耗费CPU资源),但你能确保一旦有消息来,你能立即看到。
当任务队列为空时,调度协程会处于忙等待状态,即不断地检测任务队列(当任务队列为空时,会运行idle协程,idle只是先将自身先加入任务队列,然后让出执行权),以查看是否有新任务到来。这种设计虽然会导致CPU使用率较高,但它确保了系统能够快速响应新任务的到来。
对应到具体代码是:一是Scheduler的tickle函数什么也不做; 二是idle协程在协程调度器未停止的情况下只会yield to hold,而调度协程又会将idle协程重新swapIn,相当于idle啥也不做直接返回。
tickle
tickle一般用于通知调度协程有新任务加入,从而让调度协程从idle状态中退出,开始执行新任务。
但是sylar的tickle什么都没做。
协程调度器类
初始化:
在初始化时,可以指定使用的线程数和一个布尔型的use_caller参数。
如果use_caller为true,则使用caller线程进行调度,并且内部线程数自动减一。
如果是在main函数中创建的调度器且use_caller为true,则会创建一个属于main线程的调度协程。
caller线程是指在多线程或协程调度环境中,发起调用的原始线程。如果一个调度器在main函数中创建,并且设置了使用caller线程(use_caller为true)进行调度,那么main函数所在的线程也可以被用来执行调度任务(在这里就创建了一个属于main线程的调度协程)。
添加调度任务:
通过schedule方法添加调度任务,这些任务会被保存在任务队列中,但不会立即执行。
可以绑定特定线程来执行某个任务,这通过传递一个线程号参数实现。
启动调度:
start方法会创建调度线程池。 调度线程创建后,会立即开始从任务队列中取出并执行任务。
如果线程数为1且use_caller为true,则不需要创建新的线程。
调度协程:
调度协程(run方法)负责从任务队列中取出并执行任务。 如果任务队列为空,调度协程会切换到idle协程,等待新任务到来。
处理caller线程:
在非caller线程中,调度协程是主线程。 在caller线程中,调度协程是caller线程的子协程,这在协程切换时可能会有问题。
停止调度器:
如果use_caller为false,只需等待所有调度线程的协程退出。
如果use_caller为true,需要确保caller线程的调度协程也运行一次,完成调度工作后再退出。
在子协程中添加任务:
可以在执行调度任务时通过调度器的GetThis()方法获取当前调度器,然后继续添加新的任务。
调度器的实现
调度器内部维护⼀个任务队列和⼀个调度线程池。开始调度后,线程池从任务队列⾥按顺序取任务执⾏。调度线程
可以包含caller线程。当全部任务都执⾏完了,线程池停⽌调度,等新的任务进来。添加新任务后,通知线程池有
新的任务进来了,线程池重新开始运⾏调度。停⽌调度时,各调度线程退出,调度器停⽌⼯作。
Scheduler类:调度器类,负责管理和调度协程任务。它包含以下成员变量:
m_useCaller:是否使用调用者线程作为调度器。
m_name:调度器的名称。
m_rootFiber:根协程。
m_rootThread:根线程ID。
m_threadCount:线程数量。
m_threads:线程池。
m_threadIds:线程ID列表。
m_tasks:待执行的任务队列。
m_activeThreadCount:活跃线程数。
m_idleThreadCount:空闲线程数。
m_stopping:是否正在停止调度器。
m_mutex:互斥锁。
ScheduleTask:一个结构体,用于存储待调度的任务信息,包括协程和回调函数。
包含以下成员函数:
Scheduler::Scheduler(size_t threads, bool use_caller, const
std::string &name):构造函数,用于创建一个调度器实例。参数包括线程数、是否使用调用者线程以及调度器的名称。
Scheduler *Scheduler::GetThis():获取当前线程的调度器实例。 Fiber
*Scheduler::GetMainFiber():获取调度器的主协程。 void Scheduler::setThis():设置当前线程的调度器实例。
Scheduler::~Scheduler():析构函数,用于销毁调度器实例。 void
Scheduler::start():启动调度器,创建指定数量的工作线程。 void
Scheduler::tickle():通知其他线程进行任务调度。 void Scheduler::idle():空闲任务,让出CPU资源。
bool Scheduler::stopping():判断调度器是否正在停止。 void
Scheduler::stop():停止调度器,等待所有工作线程结束。 void
Scheduler::run():调度器的工作线程运行的入口函数,负责调度任务。
调度任务类SchedulerTask
将 协程或函数 封装为一个调度任务对象
SchedulerTask的结构体,用于表示调度任务。该结构体包含以下成员变量和构造函数:
fiber:一个指向Fiber对象的智能指针,表示协程任务。
cb:一个函数对象,表示普通的回调函数任务。
thread:一个整数,指定在哪个线程上进行调度。
该结构体还提供了以下构造函数:
第一个构造函数接受一个Fiber::ptr类型的参数和一个整数参数,用于初始化fiber和thread成员变量。
第二个构造函数接受一个指向Fiber::ptr的指针和一个整数参数,用于交换传入的Fiber::ptr对象并初始化thread成员变量。
第三个构造函数接受一个std::function<void()>类型的参数和一个整数参数,用于初始化cb和thread成员变量。
第四个构造函数不接受任何参数,将thread成员变量设置为-1,表示不指定执行的线程。
此外,该结构体还提供了一个名为reset的成员函数,用于将调度任务类的变量全部置为无效状态
/*** @description: 调度任务类,协程/函数二选一,可指定在哪个线程调度* @return {*}* @Author: fuzhenkun* @Date: 2024-03-11 19:59:06*/ struct SchedulerTask {Fiber::ptr fiber;std::function<void()> cb;int thread; // 指定在哪个线程调度// 调度任务 协程SchedulerTask(Fiber::ptr f, int thr) {fiber = f;thread = thr;}SchedulerTask(Fiber::ptr *f, int thr) {fiber.swap(*f); //thread = thr;}// 调度任务 函数SchedulerTask(std::function<void()> f, int thr) {cb = f;thread = thr;}SchedulerTask() {thread = -1;}// 调度任务类的变量全部置为无效void reset() {fiber = nullptr;cb = nullptr;thread = -1;}};
协程模块的改造
协程模块的改造,增加m_runInScheduler成员,表示当前协程是否参与调度器调度,在协程的resume和yield时,根据协程的运行环境确定是和线程主协程进行交换还是和调度协程进行交换:
非对称协程模型跑⻜的原因:
⼦协程和⼦协程切换导致线程主协程跑⻜是因为每个线程只有两个线程局部变量⽤于保存当前的协程上下⽂信息。也就是说线程任何时候都最多只能知道两个协程的上下⽂,其中⼀个是当前正在运⾏协程的上下⽂,另⼀个是线程主协程的上下⽂,如果⼦协程和⼦协程切换,那这两个上下⽂都会变成⼦协程的上下⽂,线程主协程的上下⽂丢失了。
只需要给每个线程增加⼀个线程局部变量⽤于保存调度协程的上下⽂就可以了,这样,每个线程可以同时保存三个协程的上下⽂,⼀个是当前正在执⾏的协程上下⽂,另⼀个是线程主协程的上下⽂,最后⼀个是调度协程的上下⽂。有了这三个上下⽂,协程就可以根据⾃⼰的身份来选择和每次和哪个协程进⾏交换
具体操作如下:
- 给协程类增加⼀个bool类型的成员m_runInScheduler,⽤于记录该协程是否通过调度器来运⾏。
- 创建协程时,根据协程的身份指定对应的协程类型,具体来说,只有想让调度器调度的协程的m_runInScheduler值为true,线程主协程和线程调度协程的m_runInScheduler都为false。
- resume⼀个协程时,如果如果这个协程的m_runInScheduler值为true,表示这个协程参与调度器调度,那它应该和三个线程局部变量中的调度协程上下⽂进⾏切换,同理,在协程yield时,也应该恢复调度协程的上下⽂,表示从⼦协程切换回调度协程;
- 如果协程的m_runInScheduler值为false,表示这个协程不参与调度器调度,那么在resume协程时,直接和线程主协程切换就可以了,yield也⼀样,应该恢复线程主协程的上下⽂。m_runInScheduler值为false的协程上下⽂切换完全和调度协程⽆关,可以脱离调度器使⽤。
线程局部变量
协程调度模块的全局变量和线程局部变量,只有以下两个线程局部变量:
/// 当前线程的调度器,同一个调度器下的所有线程指同同一个调度器实例
static thread_local Scheduler *t_scheduler = nullptr;
/// 当前线程的调度协程,每个线程都独有一份,包括caller线程
static thread_local Fiber *t_scheduler_fiber = nullptr;
t_scheduler_fiber保存当前线程的调度协程,加上Fiber模块的t_fiber和t_thread_fiber,每个线程总共可以记录三个协程的上下文信息。
调度器(Scheduler):调度器负责管理线程或任务的执行顺序和时机。用于决定哪个线程或任务应该获得CPU时间,以及何时获得。调度器通常基于优先级、时间片轮转或其他算法来决定资源的分配。
调度协程(Scheduled Coroutine):调度协程来执行调度器安排的协程,即调度协程让出执行权,并切换到调度器决定要执行的协程任务。
调度器(Scheduler)
/*** @brief 创建调度器* @param[in] threads 线程数* @param[in] use_caller 是否将当前线程也作为调度线程* @param[in] name 名称*/
Scheduler::Scheduler(size_t threads, bool use_caller, const std::string &name) {Fzk_ASSERT(threads > 0);m_useCaller = use_caller;m_name = name;if (use_caller) {--threads;sylar::Fiber::GetThis();Fzk_ASSERT(GetThis() == nullptr);t_scheduler = this;/*** 在user_caller为true的情况下,初始化caller线程的调度协程* caller线程的调度协程不会被调度器调度,而且,caller线程的调度协程停止时,应该返回caller线程的主协程*/m_rootFiber.reset(new Fiber(std::bind(&Scheduler::run, this), 0, false));sylar::Thread::SetName(m_name);t_scheduler_fiber = m_rootFiber.get();m_rootThread = sylar::GetThreadId();m_threadIds.push_back(m_rootThread);} else {m_rootThread = -1;}m_threadCount = threads;
}Scheduler *Scheduler::GetThis() {return t_scheduler;
}
bind
使用std::bind将成员函数与对象实例进行绑定,可以按照以下步骤进行操作:
包含头文件 。
创建一个可调用对象,使用std::bind函数将成员函数与对象实例进行绑定。
调用可调用对象以执行绑定的成员函数。
#include <iostream>
#include <functional>
class MyClass {
public:void myFunction() {std::cout << "Hello, World!" << std::endl;}
};
int main() {MyClass obj;// 使用std::bind将成员函数与对象实例进行绑定auto boundFunction = std::bind(&MyClass::myFunction, &obj);// 调用绑定的成员函数boundFunction();return 0;
}
协程调度器的start方法实现
主要初始化调度线程池,如果只使用caller线程进行调度,则m_threadCount-1 = 0,所以实际不做
void Scheduler::start() {Fzk_LOG_DEBUG(g_logger) << "start";MutexType::Lock lock(m_mutex);if (m_stopping) {Fzk_LOG_ERROR(g_logger) << "Scheduler is stopped";return;}Fzk_ASSERT(m_threads.empty());m_threads.resize(m_threadCount);for (size_t i = 0; i < m_threadCount; i++) {m_threads[i].reset(new Thread(std::bind(&Scheduler::run, this),m_name + "_" + std::to_string(i)));m_threadIds.push_back(m_threads[i]->getId());}
}
协程调度器的stopping方法实现
判断调度器是否已经停止的方法,只有当所有的任务都被执行完了,调度器才可以停止:
bool Scheduler::stopping() {MutexType::Lock lock(m_mutex);return m_stopping && m_tasks.empty() && m_activeThreadCount == 0;
}
调度器的tickle和idle(空闲协程)实现
可以看到这两个方法并没有实际作用:
//通知调度协程有新任务加入,从而让调度协程从idle状态中退出,开始执行新任务。
//但这里实际啥的没做
void Scheduler::tickle() {SYLAR_LOG_DEBUG(g_logger) << "ticlke";
}
//调度器处于空闲状态,即**不断地检测任务队列**(当任务队列为空时,会运行idle协程,idle只是先将自身先加入任务队列,然后让出执行权),以查看是否有新任务到来。
void Scheduler::idle() {SYLAR_LOG_DEBUG(g_logger) << "idle";while (!stopping()) {sylar::Fiber::GetThis()->yield();}
}
调度协程的实现即run方法
调度协程的实现,内部有一个while(true)循环,不停地从任务队列取任务并执行,由于Fiber类改造过,每个被调度器执行的协程在结束时都会回到调度协程,当任务队列为空时,代码会进idle协程,但idle协程啥也不做直接就yield了,状态还是READY状态,所以这里其实就是个忙等待,CPU占用率爆炸,只有当调度器检测到停止标志时(本来应该是通过tickle通知调度协程有新任务加入,但这里tickle实际啥也没做),idle协程才会真正结束,调度协程也会检测到idle协程状态为TERM,并且随之退出整个调度协程。
void Scheduler::run() {Fzk_LOG_DEBUG(g_logger) << "run";setThis();if (Fzk::GetThreadId() != m_rootThread) {t_scheduler_fiber = Fzk::Fiber::GetThis().get();}Fiber::ptr idle_fiber(new Fiber(std::bind(&Scheduler::idle, this)));Fiber::ptr cb_fiber;ScheduleTask task;while (true) {task.reset();bool tickle_me = false; // 是否tickle其他线程进行任务调度 但实际该调度器为实现tickle方法用来通知其他线程来进行任务调度{MutexType::Lock lock(m_mutex);auto it = m_tasks.begin();// 遍历所有调度任务while (it != m_tasks.end()) {if (it->thread != -1 && it->thread != Fzk::GetThreadId()) {// 指定了调度线程,但不是在当前线程上调度,标记一下需要通知其他线程进行调度,然后跳过这个任务,继续下一个++it;tickle_me = true;continue;}// 找到一个未指定线程,或是指定了当前线程的任务Fzk_ASSERT(it->fiber || it->cb);if (it->fiber) {// 任务队列时的协程一定是READY状态,谁会把RUNNING或TERM状态的协程加入调度呢?Fzk_ASSERT(it->fiber->getState() == Fiber::READY);}// 当前调度线程找到一个任务,准备开始调度,将其从任务队列中剔除,活动线程数加1task = *it;m_tasks.erase(it++);++m_activeThreadCount;break;}// 当前线程拿完一个任务后,发现任务队列还有剩余,那么tickle一下其他线程tickle_me |= (it != m_tasks.end());}if (tickle_me) {tickle();}if (task.fiber) {// resume协程,resume返回时,协程要么执行完了,要么半路yield了,总之这个任务就算完成了,活跃线程数减一task.fiber->resume();--m_activeThreadCount;task.reset();} else if (task.cb) {if (cb_fiber) {cb_fiber->reset(task.cb);} else {cb_fiber.reset(new Fiber(task.cb));}task.reset();cb_fiber->resume();--m_activeThreadCount;cb_fiber.reset();} else {// 进到这个分支情况一定是任务队列空了,调度idle协程即可if (idle_fiber->getState() == Fiber::TERM) {// 如果调度器没有调度任务,那么idle协程会不停地resume/yield,不会结束,如果idle协程结束了,那一定是调度器停止了Fzk_LOG_DEBUG(g_logger) << "idle fiber term";break;}++m_idleThreadCount;idle_fiber->resume();--m_idleThreadCount;}}Fzk_LOG_DEBUG(g_logger) << "Scheduler::run() exit";
}
调度器的stop方法实现
调度器的stop方法,在使用了caller线程的情况下,调度器依赖stop方法来执行caller线程的调度协程,如果调度器只使用了caller线程来调度,那调度器真正开始执行调度的位置就是这个stop方法。
void Scheduler::stop() {Fzk_LOG_DEBUG(g_logger) << "stop";if (stopping()) {return;}m_stopping = true;/// 如果use caller,那只能由caller线程发起stopif (m_useCaller) {Fzk_ASSERT(GetThis() == this);} else {Fzk_ASSERT(GetThis() != this);}for (size_t i = 0; i < m_threadCount; i++) {tickle();}if (m_rootFiber) {tickle();}/// 在use caller情况下,调度器协程结束时,应该返回caller协程if (m_rootFiber) {m_rootFiber->resume();Fzk_LOG_DEBUG(g_logger) << "m_rootFiber end";}std::vector<Thread::ptr> thrs;{MutexType::Lock lock(m_mutex);thrs.swap(m_threads);}for (auto &i : thrs) {i->join();}
}
这篇关于协程库-协程调度器类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





