本文主要是介绍深度学习方法;乳腺癌分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
乳腺癌的类型很多,但大多数常见的是浸润性导管癌、导管原位癌和浸润性小叶癌。浸润性导管癌(IDC)是最常见的乳腺癌类型。这些都是恶性肿瘤的亚型。大约80%的乳腺癌是浸润性导管癌(IDC),它起源于乳腺的乳管。
浸润性是指癌症已经“侵袭”或扩散到周围的乳房组织,而导管是指从乳管开始的癌症,乳管是将乳汁从产奶小叶输送到乳房乳头的“管道”。癌症是指任何始于覆盖组织或内脏皮肤的癌症,如乳房组织。
计算机辅助的检测系统由预处理单元、特征提取、特征选择、分割和分类组成。每个阶段的输出作为后续步骤的输入。
肿瘤的形状是决定肿瘤性质的重要特征;因此,边缘分割是肿瘤分类的重要方法之一。边缘分割技术是基于纹理和基于区域的特征,即低层特征。
为了针对特定任务训练模型,我们需要大量的标记数据。有时,如此大量的训练数据会导致数据与模型的过度拟合。处理过拟合问题的解决方案是使用深度自动编码器的无监督学习,该深度自动编码器微调到特定的分类问题。
基于CNN的分类器
逻辑回归
它通常用于估计属于特定类别的对象的概率 。如果一个类别的概率大于50%,则该对象属于该类别,否则在二进制类别分类的情况下它属于负类别。
输入特征的加权和,并且添加偏置项。但是并没有像线性回归一样直接输出
随机森林
决策树分类器是一种简单、快速且基于规则的分类器,广泛用于分类。白盒机器学习方法,揭示了内部决策逻辑。它使用IF-THEN规则进行决策。
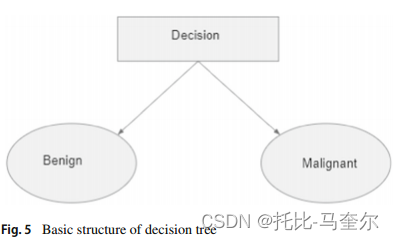
一旦构建了决策树,就可以使用它来对新数据进行分类和测试。它是整体模型中的基本单位。随机森林分类器是一种包含多个决策树分类器进行分类的集成分类技术。
随机选择多个决策树分类器,并根据大多数分类器来确定目标结果。
支持向量机
通过使用具有大量边距的超平面来分隔数据点。它可以通过核技巧处理输入空间中的非线性。它找出了对数据点进行分类的最优超平面。超平面是(n-1)维的。

与Logistic分类器不同,支持向量机分类器速度很快,因为它不计算每一类的概率。
AdaBoost分类器(自适应Boost)
Boost是一种集成方法,将几个弱学习者结合在一起,形成一个强学习者。这些弱学习者被称为预测器,预测器的数量是用户定义的,可能会根据问题的不同而变化。增强算法的主要思想是按顺序训练预测器。前一个预测器的输出充当当前预测器的输入。

为了训练AdaBoost分类器,我们考虑具有m个对象的训练集,每个对象被称为示例,并且N表示取决于问题的性质和用户定义的预测器的数量,每个时刻的权重初始设置为
。通过减小误差来获得第一个预测器的最优权重。第 j 个预测器的误差计算公式为:
预测器的第 j 个权重为:,
指的是学习率
实例 i ()的权重
为
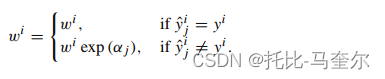
设样本x的第 j 个预测器的预测类为k,即
Bagging 分类器
一种集成分类器,由用户决定的许多预测值组成。这些预测器使用相同的训练算法,但在训练数据集的不同随机子集上。选择训练数据集的不同随机子集的过程称为采样,以两种方式执行,有替换和无替换。未更换的采样称为粘贴,有更换的采样称为装袋。
对于相同的预测器,需要对训练实例进行多次采样,当所有Bagging预测器在训练数据集上训练时,通过简单地聚集所有预测器的预测来对测试数据进行预测。由于袋装分类器并行训练所有预测器,因此它比AdaBoost分类器花费的时间更少。

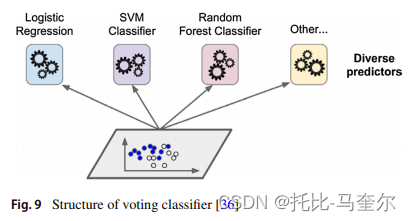
投票分类器
投票分类器也是集成分类器,其有两种类型:硬投票分类器;软投票分类器
在硬投票分类器中,考虑每个类别的大多数选票。而在软投票分类器中,将预测类别的大多数作为概率作为最终输出。
当投票分类器的所有分类器都是独立的时候,由于每个分类器使用不同的训练方法,因此可以得到更好的结果。
这篇关于深度学习方法;乳腺癌分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







