本文主要是介绍文献研读|AIGC溯源场景及研究进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:本文介绍关于AIGC生成阶段针对不同溯源场景的几篇相关工作。
如下图所示,在AIGC生成阶段,有4种溯源场景:
1)生成模型溯源训练数据
2)微调模型溯源预训练模型
3)AIGC溯源训练数据/训练概念
4)AIGC溯源生成模型
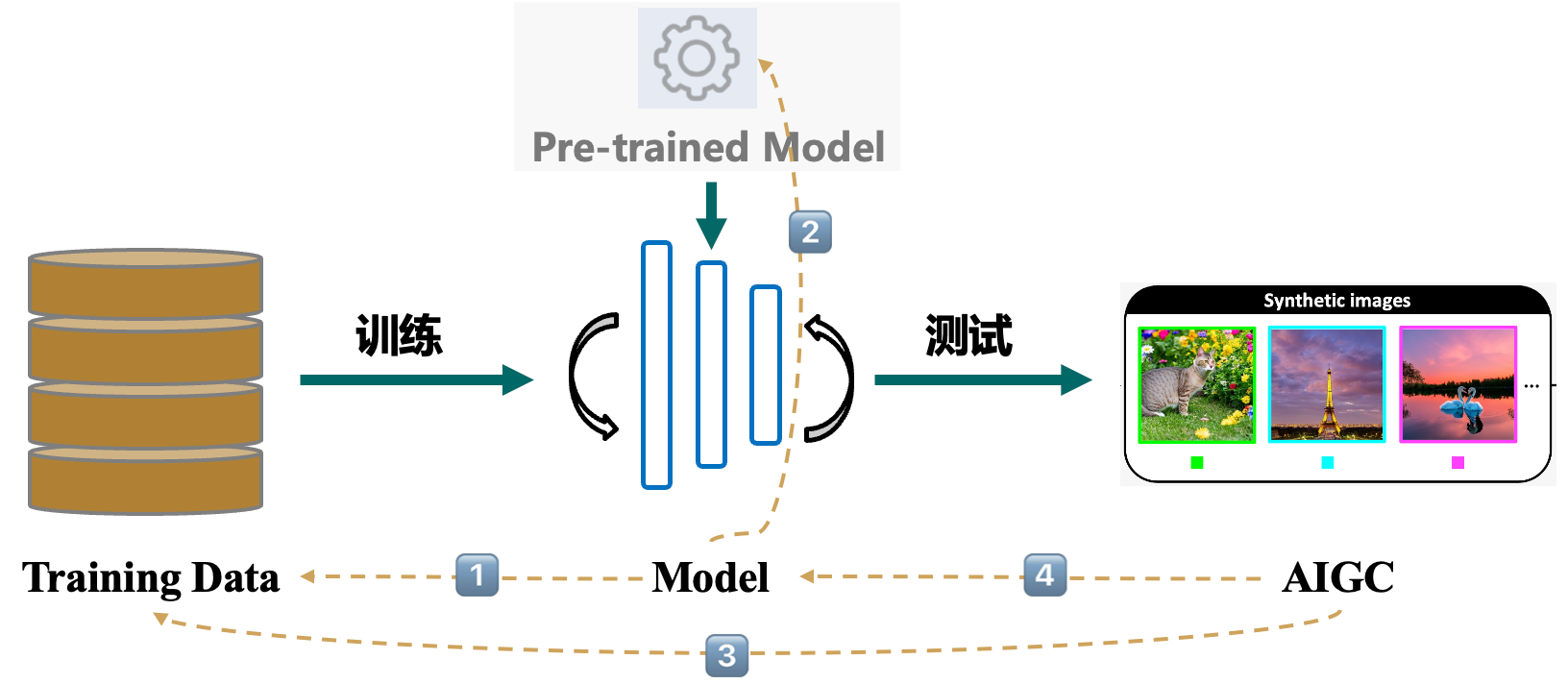
下面分别对不同溯源场景下的相关工作进行介绍。
目录
- Detection and Attribtion of Models Trained on Generated Data. ICASSP, 2024.
- Matching Pairs: Attributing Fine-Tuned Models to their Pre-Trained Large Language Models. ACL, 2023.
- Evaluating Data Attribution for Text-to-Image Models. ICCV, 2023.
- 数据集构建
- 特征提取器训练
- ProMark: Proactive Diffusion Watermarking for Causal Attribution. CVPR, 2024.
- DE-FAKE: Detection and Attribution of Fake Images Generated by Text-to-Image Generation Models, CCS, 2023.
Detection and Attribtion of Models Trained on Generated Data. ICASSP, 2024.
Scenario: 生成模型溯源训练数据
RQ1:模型的训练数据为 real data / fake data?
RQ2:若模型的训练数据为 fake data,则由哪个 GAN 生成?
目标:判断 target model 的训练数据来源
核心思想:
Real dataset 分成:training data, probing dataset,testing data.
- 首先用 training data 训练 GANs,得到 GAN-generated data;
- 分别用 GAN-generated data 和 real data 训练 surrogate models 和 target models;
- 使用 probing dataset 探测 surrogate model 得到 output,用GAN数据训练的 surrogate model 的输出标签均为0,用真实数据训练的 surrogate model 的输出标签均为1,得到 binary dataset;
- 使用 binary dataset 训练 detector 。
- 使用 testing dataset 探测 target model 得到 output,如果该 target model 基于GAN数据训练,则其 output 送入 detector 的预测标签应该为0,否则应该为1.
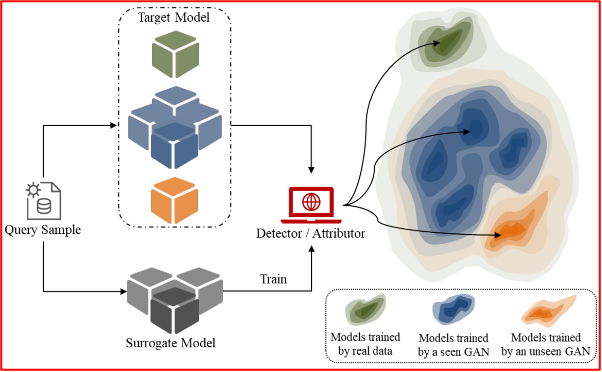
若为溯源问题,则对于步骤3:
- Closed-World Attribution:binary dataset 改成多标签分类问题
- Open-World Attribution:probing set 改为GAN生成数据,若probe image 和 model 训练使用的GAN数据来源一致,则标签为 1。
Matching Pairs: Attributing Fine-Tuned Models to their Pre-Trained Large Language Models. ACL, 2023.
Scenario: 微调模型溯源预训练模型
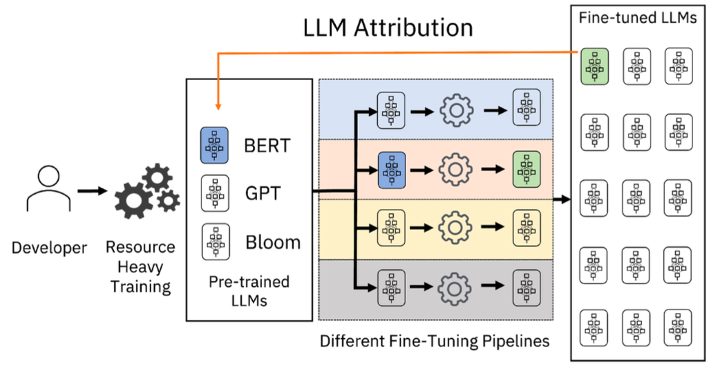
Code: https://github.com/IBM/model-attribution-in-machine-learning
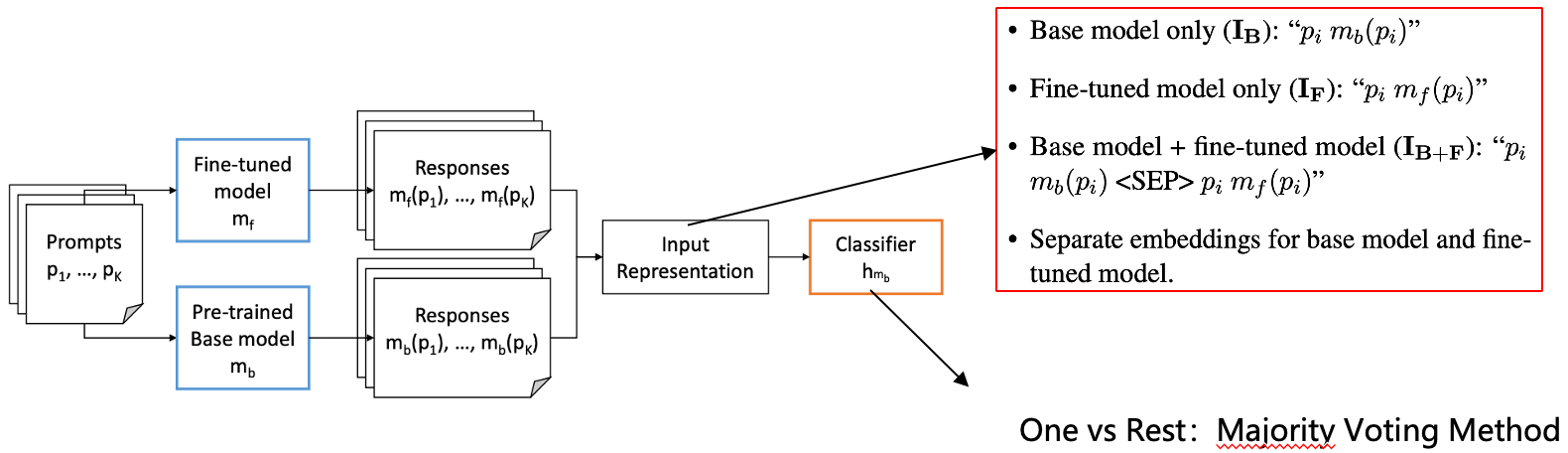
核心思想:通过联合微调模型与预训练模型生成结果与提示词的特征,训练分类器,采用集成学习的方式确定微调模型对应的预训练模型。
Evaluating Data Attribution for Text-to-Image Models. ICCV, 2023.
Page: https://github.com/peterwang512/GenDataAttribution
Scenario: AIGC 溯源训练数据
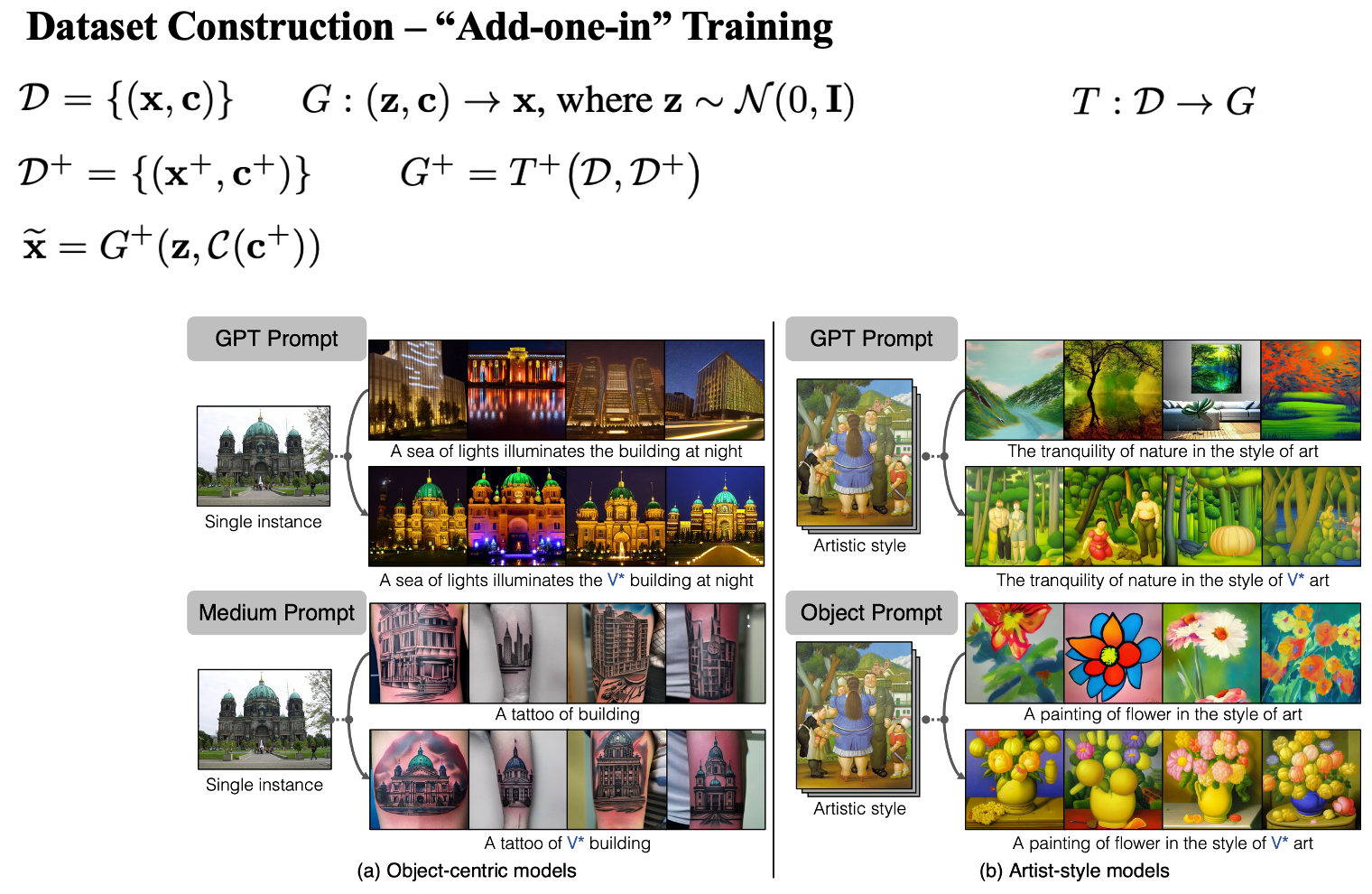
核心思想:首先构建具有对应关系的溯源数据集,然后使用对比学习的方式,优化特征提取器。
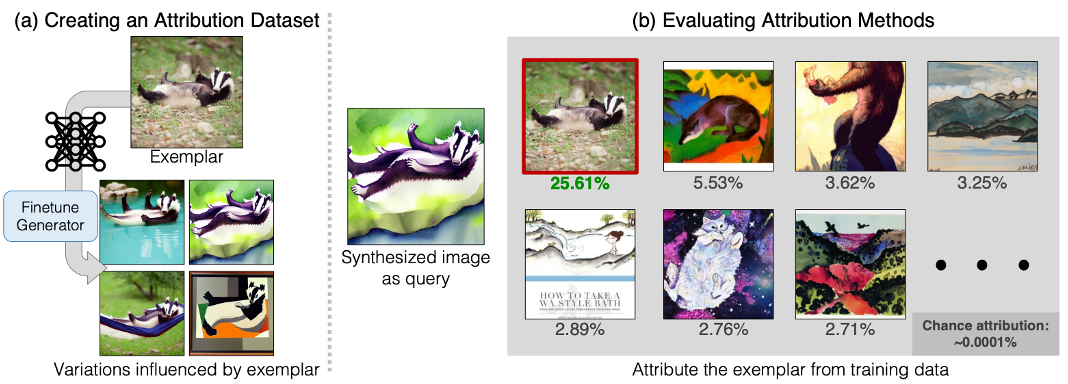
数据集构建
特征提取器训练
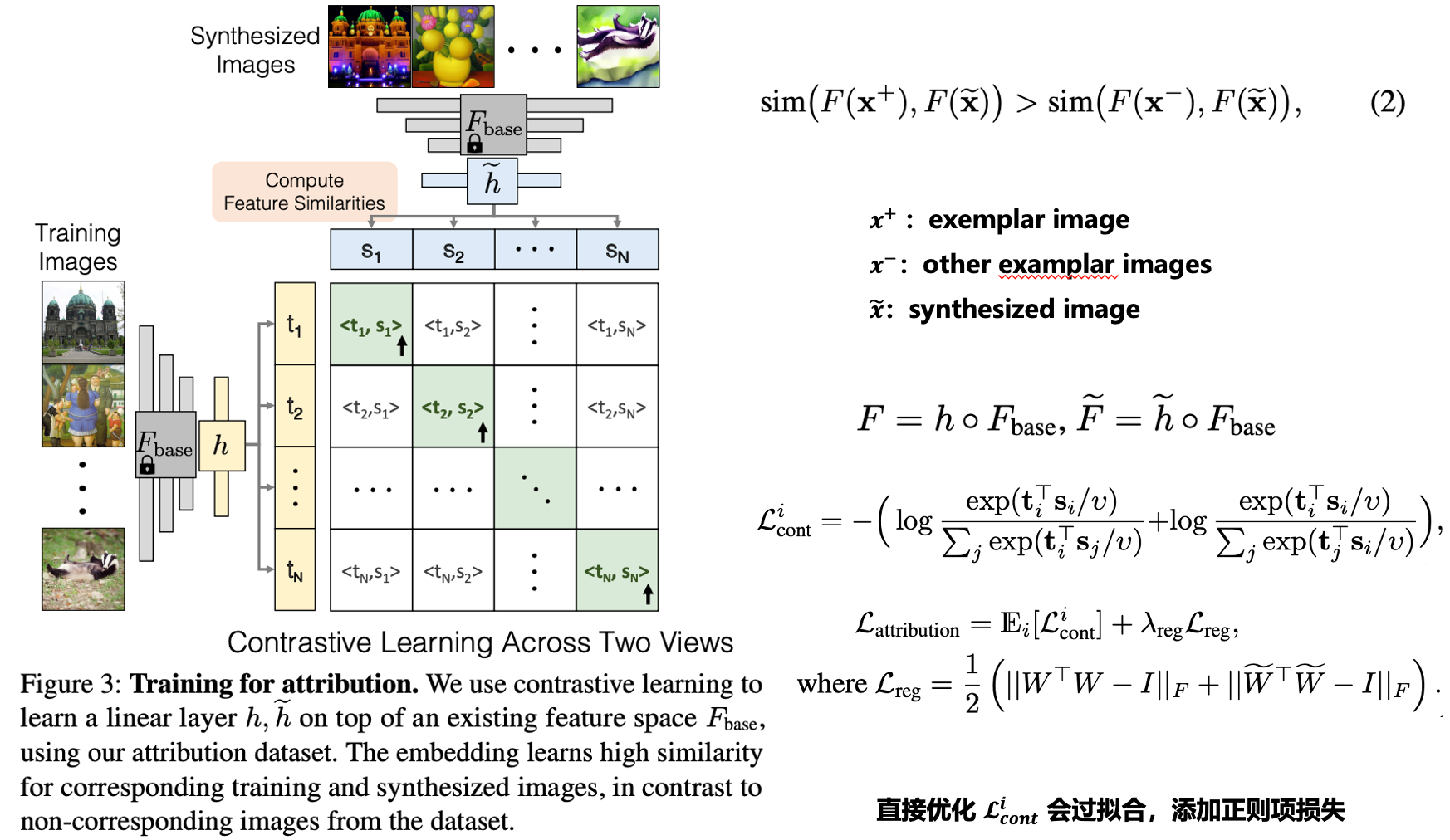
特征提取器训练的目标是:使得具有对应关系的合成图像+范本图像距离更近,而无对应关系的合成图像+范本图像距离更远。具体使用对比学习损失来进行训练。
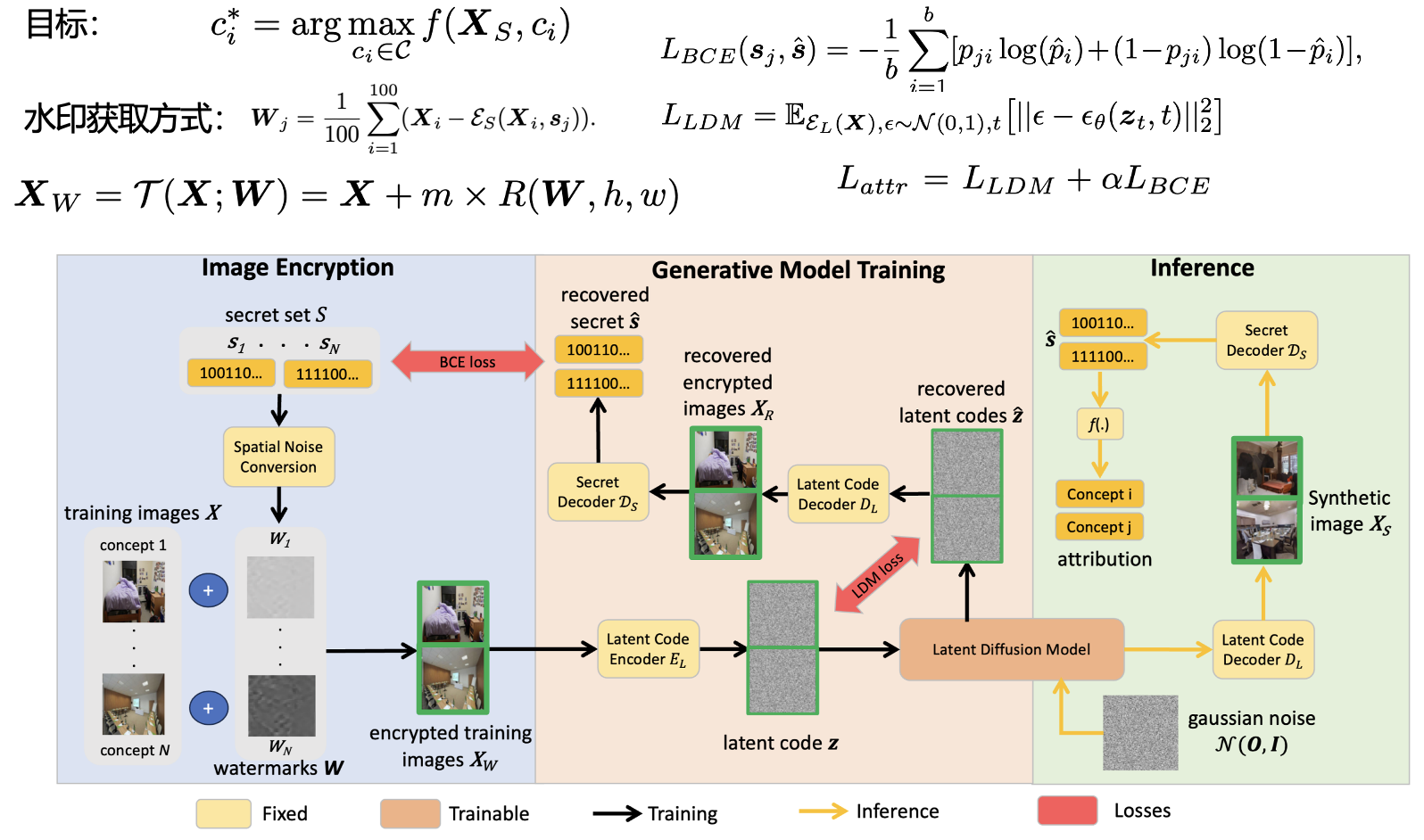
ProMark: Proactive Diffusion Watermarking for Causal Attribution. CVPR, 2024.
Scenario: AIGC 溯源训练概念(概念水印)
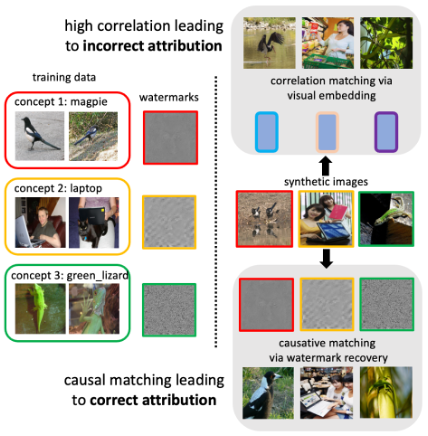
核心思想:使用水印嵌入的方式,实现概念水印的嵌入和提取。
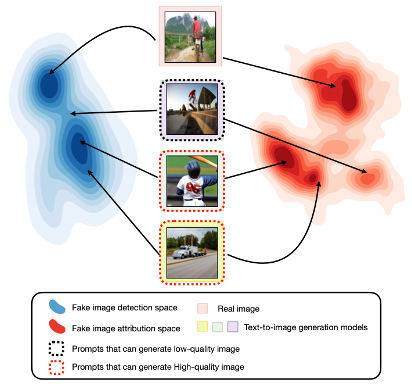
DE-FAKE: Detection and Attribution of Fake Images Generated by Text-to-Image Generation Models, CCS, 2023.
Scenario: AIGC 溯源生成模型
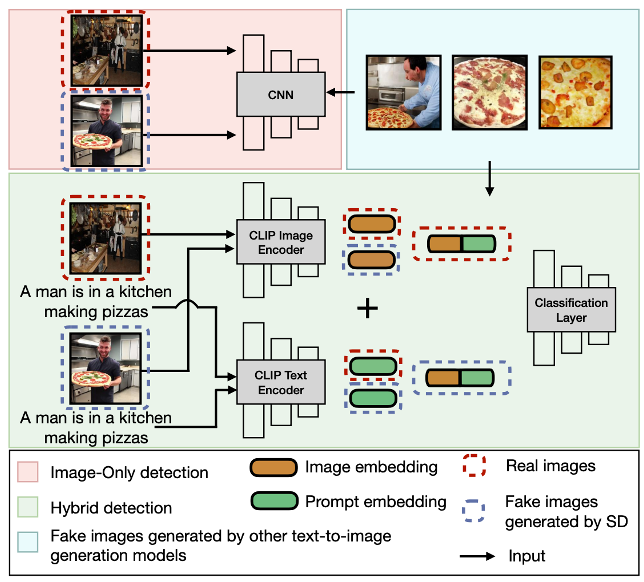
核心思想:训练二/多分类器,溯源生成模型。
(1)Image-Only: image 特征提取,后训练(ResNet-18)
(2)Hybrid: image 和 prompt 的特征联合提取拼接,后训练(CLIP+MLP)
参考文献
- Han G, Salem A, Li Z, et al. Detection and Attribution of Models Trained on Generated Data. ICASSP, 2024.
- Foley M, Rawat A, Lee T, et al. Matching Pairs: Attributing Fine-Tuned Models to their Pre-Trained Large Language Models. ACL, 2023.
- Wang S Y, Efros A A, Zhu J Y, et al. Evaluating data attribution for text-to-image models. ICCV, 2023.
- Asnani V, Collomosse J, Bui T, et al. ProMark: Proactive Diffusion Watermarking for Causal Attribution. CVPR, 2024.
- Sha Z, Li Z, Yu N, et al. De-fake: Detection and attribution of fake images generated by text-to-image generation models. CCS, 2023.
这篇关于文献研读|AIGC溯源场景及研究进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




