本文主要是介绍【调度工具】Azkaban用户手册,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
一、概述
1.1 Azkaban 是什么
1.2 Azkaban 特点
1.3 Azkaban 与 Oozie 对比
功能
工作流定义
工作流传参
定时执行
资源管理
工作流执行
工作流管理
1.4 Azkaban 运行模式及架构
Azkaban 三大核心组件
Azkaban有两种部署方式
Azkaban Web Server
Azkaban Executor
Azkaban 元数据库
1.5 版本
1.6测试脚本准备
二、Azkaban任务配置
2.1 单一job任务配置和执行
2.2 多个job依赖任务流配置
2.3 任务调度配置
三、Azkaban历史任务查询
四、Azkaban新增用户
一、概述
1.1 Azkaban 是什么
Azkaban 是由 Linkedin 公司推出的一个批量工作流任务调度器,Azkaban 使用 job 文件建立任务之间的依赖关系,并提供 Web 界面供用户管理和调度工作流
1.2 Azkaban 特点
Azkaban 是由 Linkedin 开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban 定义了一种 KV 文件格式来建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
它有如下功能特点:
- Web 用户界面
- 方便上传工作流
- 方便设置任务之间的关系
- 调度工作流
- 认证/授权(权限的工作)
- 能够杀死并重新启动工作流
- 模块化和可插拔的插件机制
- 项目工作区
- 工作流和任务的日志记录和审计
1.3 Azkaban 与 Oozie 对比
Azkaban 和 Oozie 是市面上最流行的两种调度器。总体来说,Ooize 相比 Azkaban 是一个重量级的任务调度系统,功能全面,但部署和使用也更复杂,比较适合作为大型项目的任务调度系统。而 Azkaban 相对而言,配置和使用更为简单,能够满足常见的任务调度,比较适合作为中小型项目的任务调度系统。
Azkaban 和 Oozie 详情对比如下:
-
功能
两者均可以调度 mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务 -
工作流定义
Azkaban 使用 Properties 文件定义工作流
Oozie 使用 XML 文件定义工作流 -
工作流传参
Azkaban 支持直接传参
Oozie 支持参数和 EL 表达式
-
定时执行
Azkaban 的定时执行任务是基于时间的
Oozie 的定时执行任务基于时间和输入数据 -
资源管理
Azkaban 有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie 暂无严格的权限控制 -
工作流执行
Azkaban 有两种运行模式,分别是单机模式和集群模式
Oozie 作为工作流服务器运行,支持多用户和多工作流 -
工作流管理
Azkaban 支持浏览器以及 ajax 方式操作工作流
Oozie 支持命令行、HTTP REST、Java API、浏览器操作工作流
1.4 Azkaban 运行模式及架构
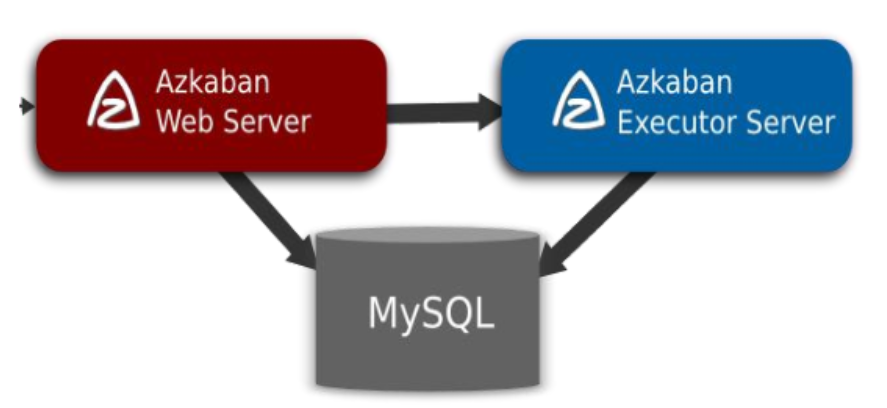
Azkaban 三大核心组件
- 关系型元数据库(MySQL)
- Azkaban Web Server
- Azkaban Executor Server
Azkaban有两种部署方式
-
solo server mode(单机模式)
WebServer 和 ExecutorServer 在同一个进程
-
cluster server mode(集群模式)
WebServe r和 ExecutorServer 运行在不同进程,并用数据库保存定义及状态
- 单个Executor
- 多个Executor
Azkaban Web Server
AzkabanWebServer 是 Azkaban 的主要管理者,负责项目管理、身份验证、调度和监控执行,并且为用户界面
Azkaban Executor
提交和执行工作流,记录工作流日志,和 Azkaban WebServer 可以在同一台服务器,也可部署在独立的机器。把 Executor 单独分开有几个好处:
- 在多 Executor 模式下可以方便扩展
- 工作流在某一个 Executor 挂掉,可以在另一个 Executor 上重试
- 可以滚动升级,从而不影响调度
Azkaban 元数据库
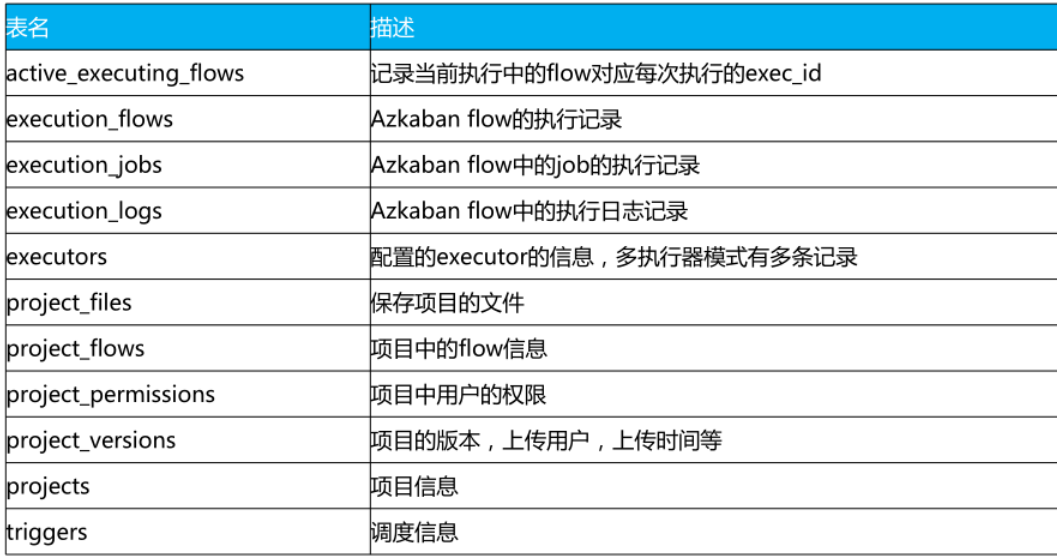
Azkaban 任务调度步骤
- Azkaban 新建项目
- 在 Azkaban Web 界面创建 Project
- 创建 job 文件
- 将文件压缩为 zip 文件
- 上传 zip 文件到 Web 界面
- 执行调度
1.5 版本
| 序号 | 文件及目录 | 版本号 | 描述 |
| 1 | JDK | 1.8.x | Java开发环境 |
| 2 | azkaban.3.30.1 | 3.30.1 | 任务调度工具 |
1.6测试脚本准备
在linux 服务器上准备测试脚本,执行如下命令:
mkdir -p /hadoop/ops/test
cat > /hadoop/ops/test/test_task01.sh << EOFecho "test_task01"
EOFcat > /hadoop/ops/test/test_task02.sh << EOFecho "test_task02"
EOFcat > /hadoop/ops/test/test_task03.sh << EOFecho "test_task03"
EOF
chmod u+x /hadoop/ops/test/test_task01.sh
chmod u+x /hadoop/ops/test/test_task02.sh
chmod u+x /hadoop/ops/test/test_task03.sh
chown -R winner_spark:hdfs /hadoop/ops/test二、Azkaban任务配置

2.1 单一job任务配置和执行
Windows本地创建test_task01.job文件,文件中的内容如下:
type=command
command=bash /hadoop/ops/test/test_task01.sh创建system.properties
user.to.proxy=winner_spark文件创建完成后,我们压缩文件为zip包

压缩完成后的文件如下图:

登录Azkaban web 创建Porject “test_task01_project”
- Name: test_task01_project
- Description: test_task01_project

创建完成后我们选择 upload 上传test_task01.zip 包
点击“选择文件”

选中 test_task01.zip 包 我们点击打开
选择“Upload”上传
如下图所示 test_task01任务上传成功
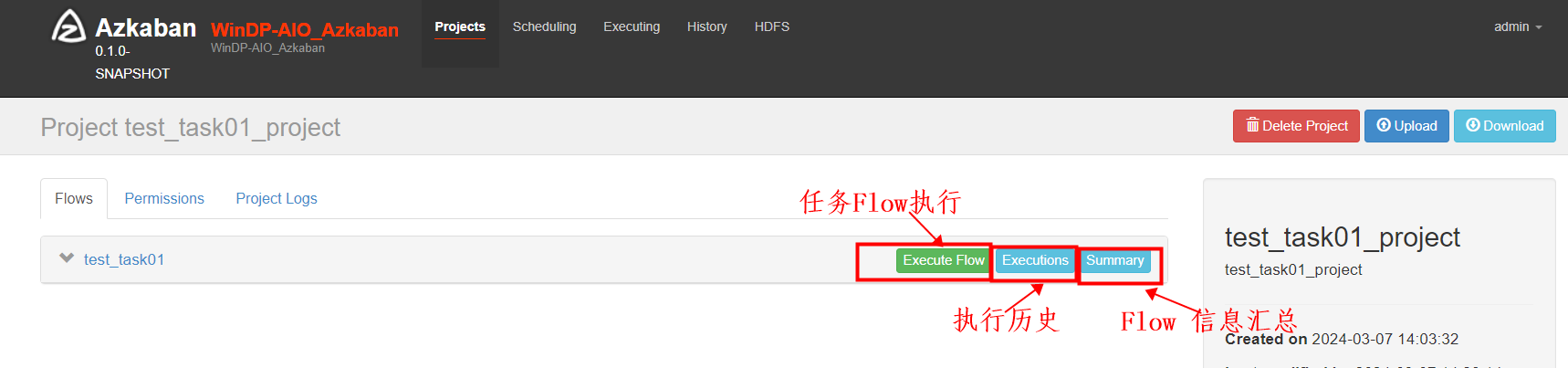
对于Flow任务 test_task01 我们可以选择执行、查看此任务执行历史和查看配置信息。
我们选择执行Flow “Execute Flow”
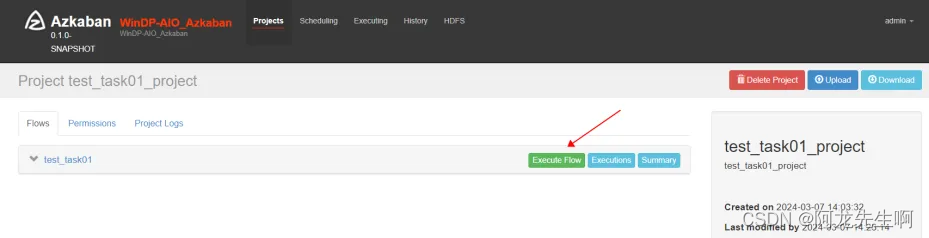
我们选择 “Execute”也就是立即执行一次。

点击“Continue”继续

如下图显示绿色代表任务执行成功。

选择Job List可以看到Flow 的执行时间、执行状态和查看详细日志选项。

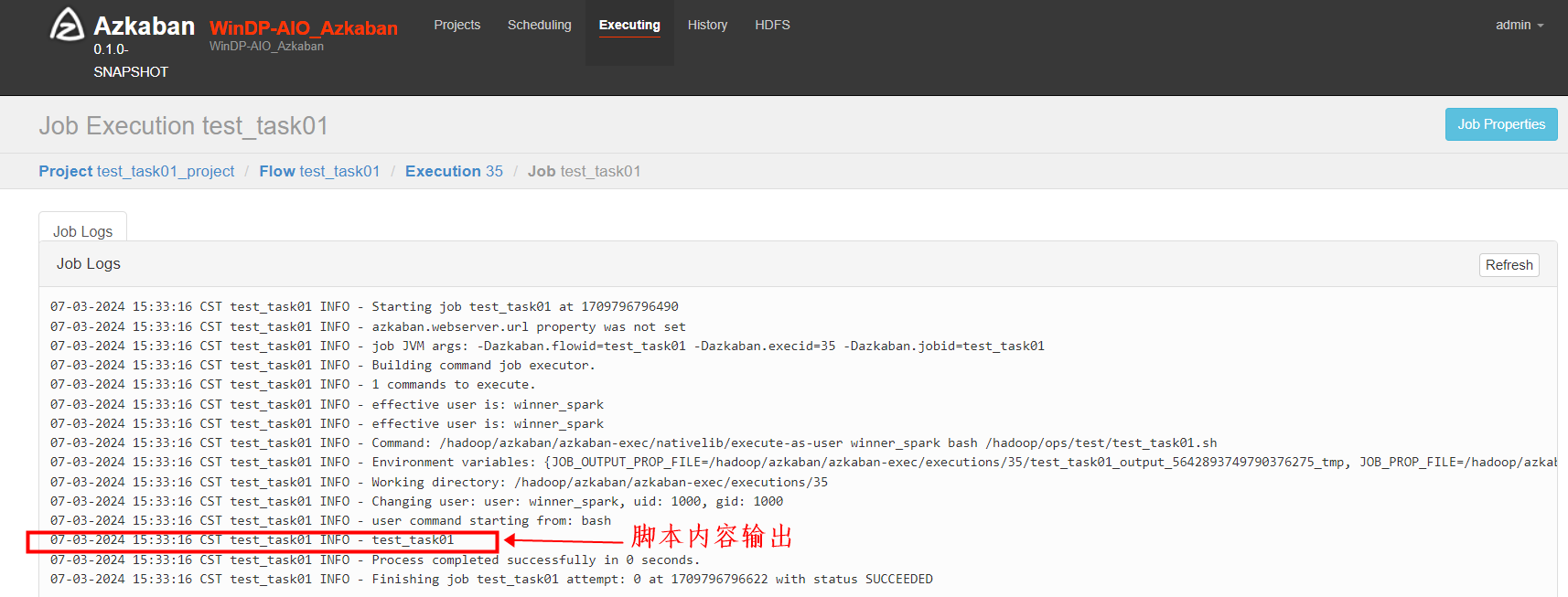
我们可以选择“Details”查看任务运行的详细日志输出。
2.2 多个job依赖任务流配置
Windows本地创建system.properties
user.to.proxy=winner_spark创建test_task01.job文件,文件中的内容如下:
type=command
command=bash /hadoop/ops/test/test_task01.sh创建文件名test_task02.job,依赖test_task01.job,dependencies写第一个job的文件名,如果有多个依赖,需要用逗号隔开。
type=command
dependencies=test_task01
command=bash /hadoop/ops/test/test_task02.sh创建文件名test_task03.job,依赖test_task02.job,dependencies写第二个job的文件名,如果有多个依赖,需要用逗号隔开
type=command
dependencies=test_task02
command=bash /hadoop/ops/test/test_task03.sh文件创建完成后,我们压缩文件为zip包

登录Azkaban web 创建Porject “test_task010203_project”
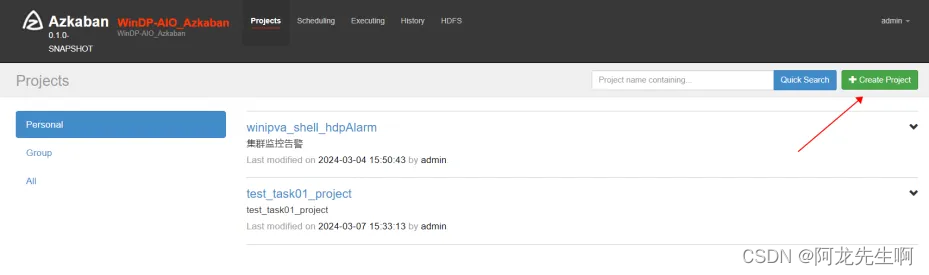
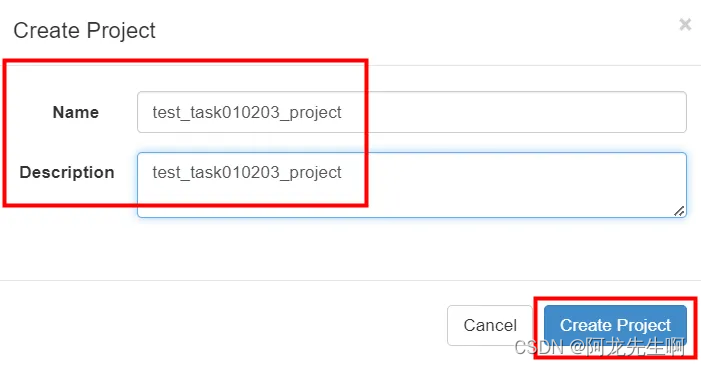
- Name: test_task010203_project
- Description: test_task010203_project
创建完成后我们选择 upload 上传azkban-test.zip 包

点击“选择文件”
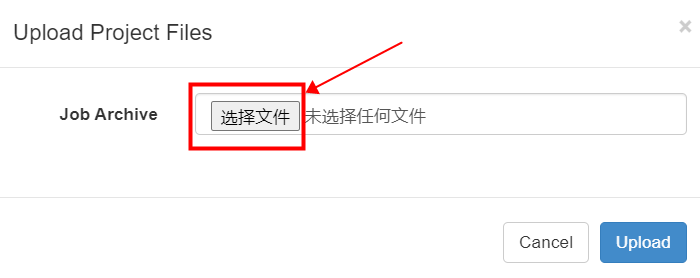
选中“azkban-test.zip ”包,打开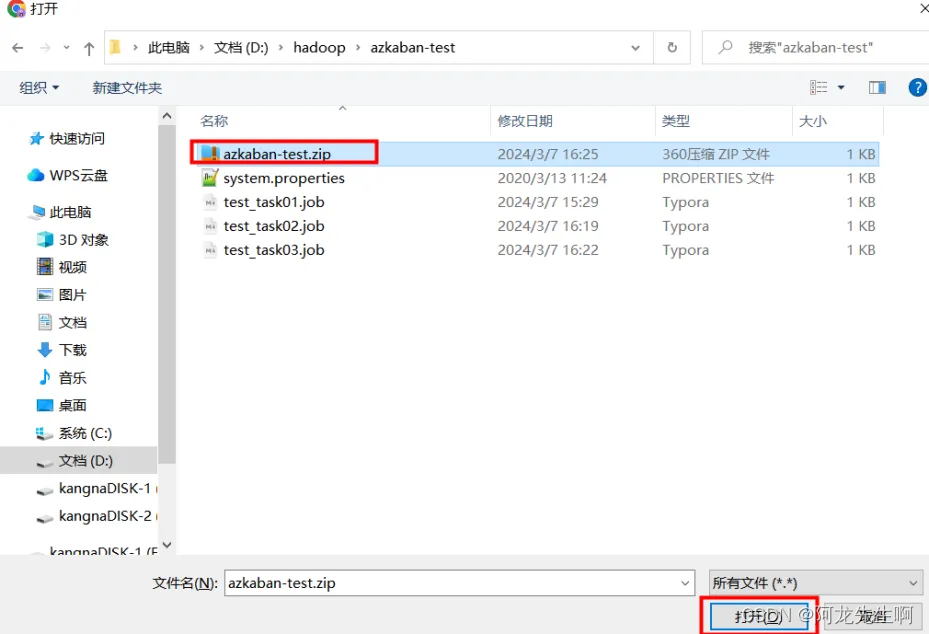
选择“Upload”

如下的Flow 中 我们可以看到任务依赖链的执行顺序。我们选择“Execute Flow”
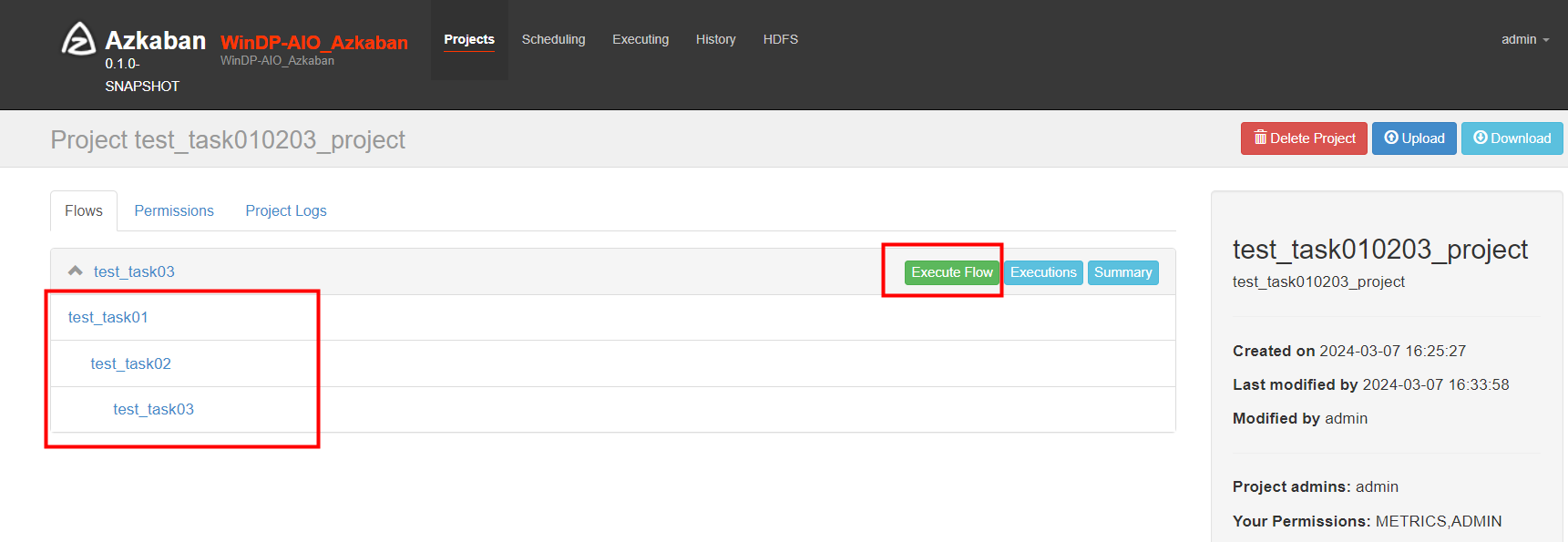
如下图我们可以看到 Flow View ,此处我们选择“Execute”

选择“Continue”继续执行
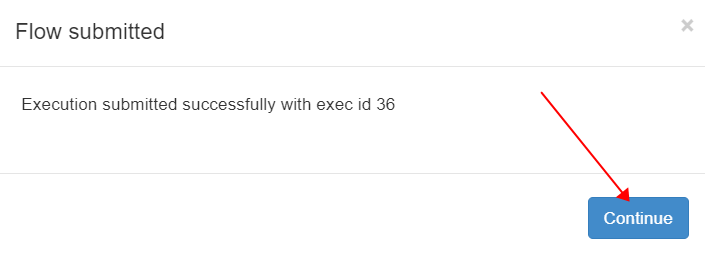
如下图显示 Flow test_task01到test_task03依次执行成功

我们选择Job List 可以看到任务Job执行的时间线、执行时间和任务可查看详细日志。
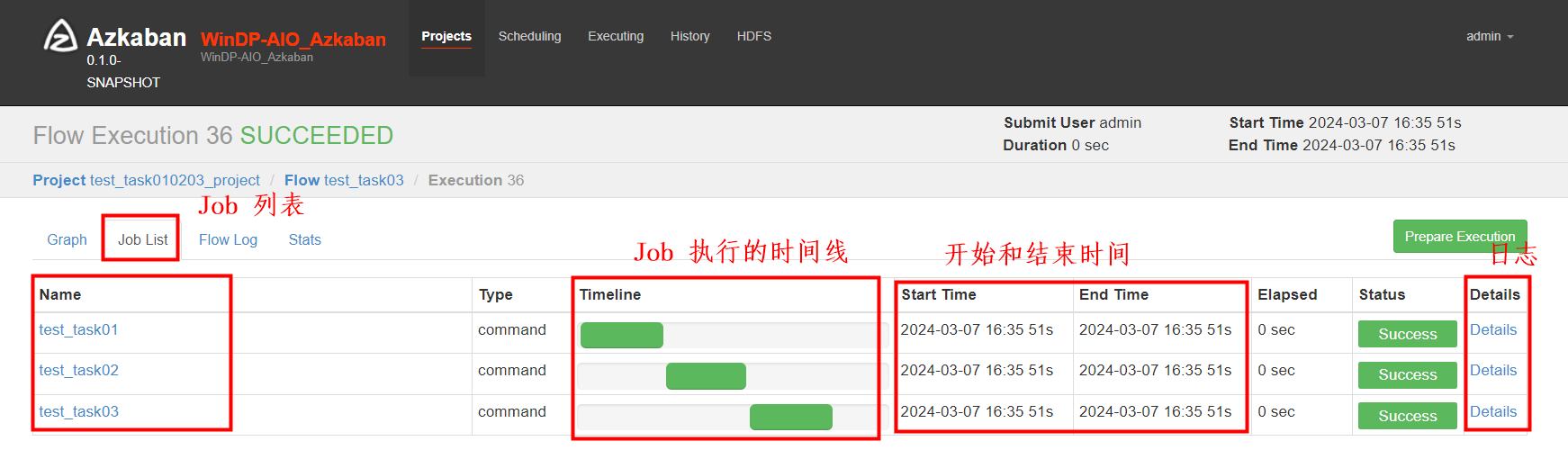
我们进入Flow test_task03 的 “Details”日志中
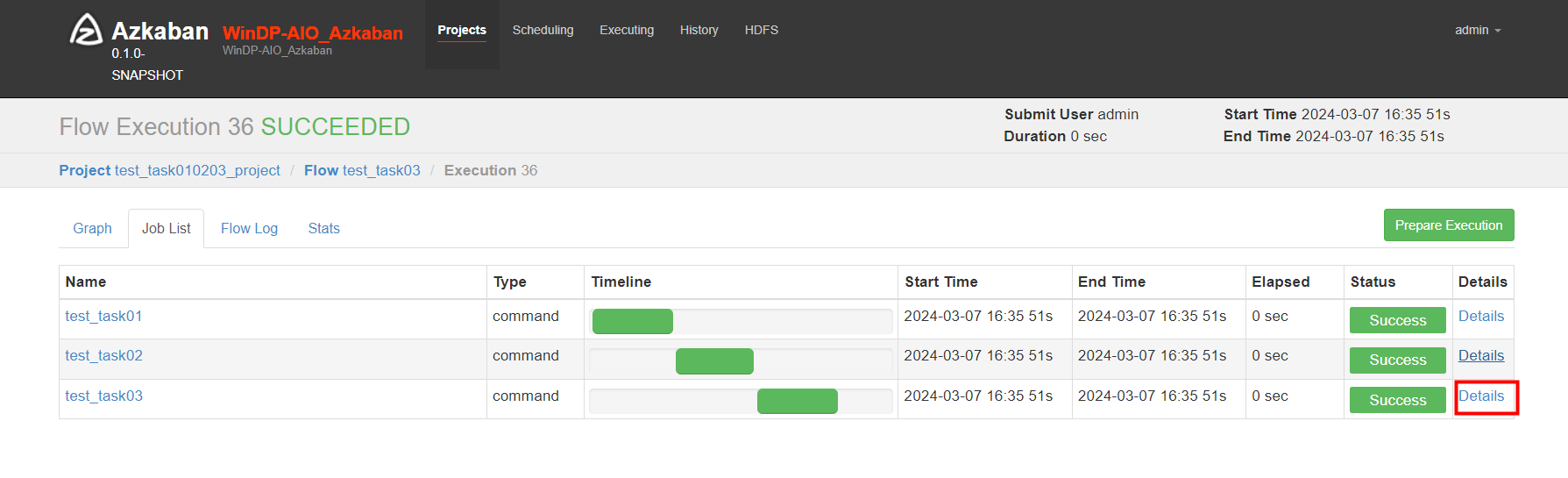
如下可以看到脚本打印输出“test_task03”

2.3 任务调度配置
我们以2.2步骤多个job任务流为例配置调度任务。
我们选择“Execute Flow”

我们选择“Schedule”
下图中是任务调度时间配置页面,配置的cron格式如下:
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * 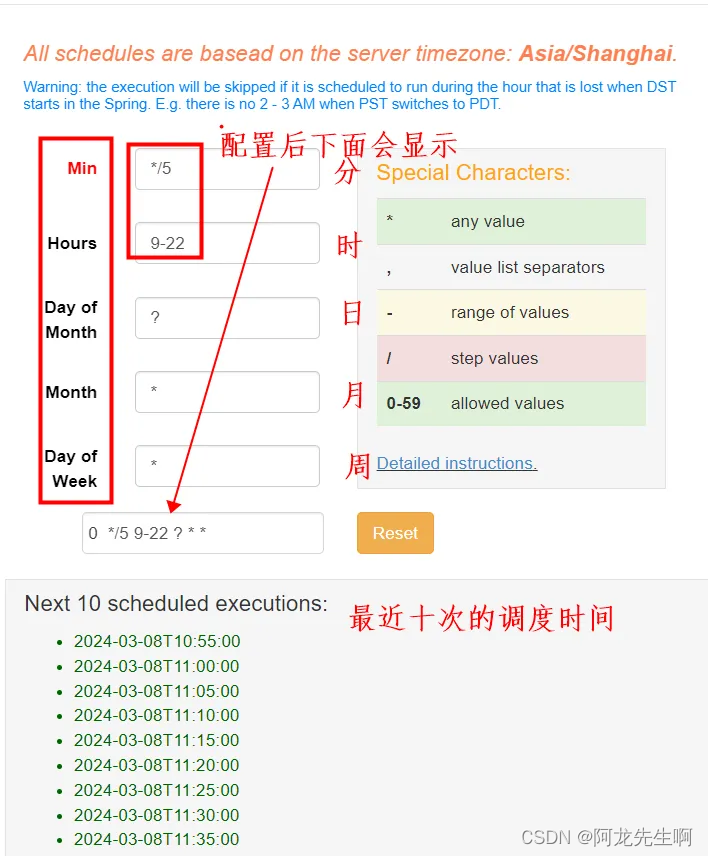
下图中配置的任务调度时间是每天的9-22之间每5分钟执行一次。配置好调度时间后我们选择“Schedule”

选择“Continue”

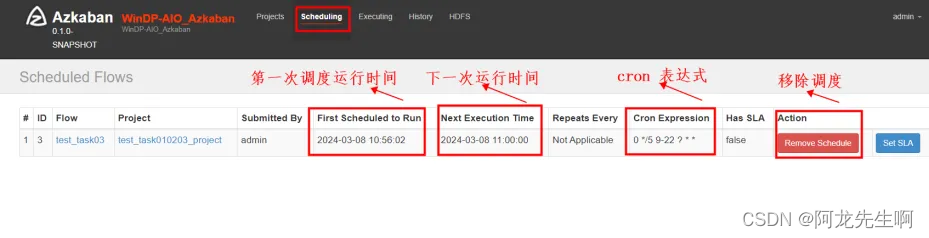
如下图中我们可以在“Scheduling”菜单中看到任务第一次调度时间、下一次运行时间、cron调度时间表达式、移除调度。
三、Azkaban历史任务查询
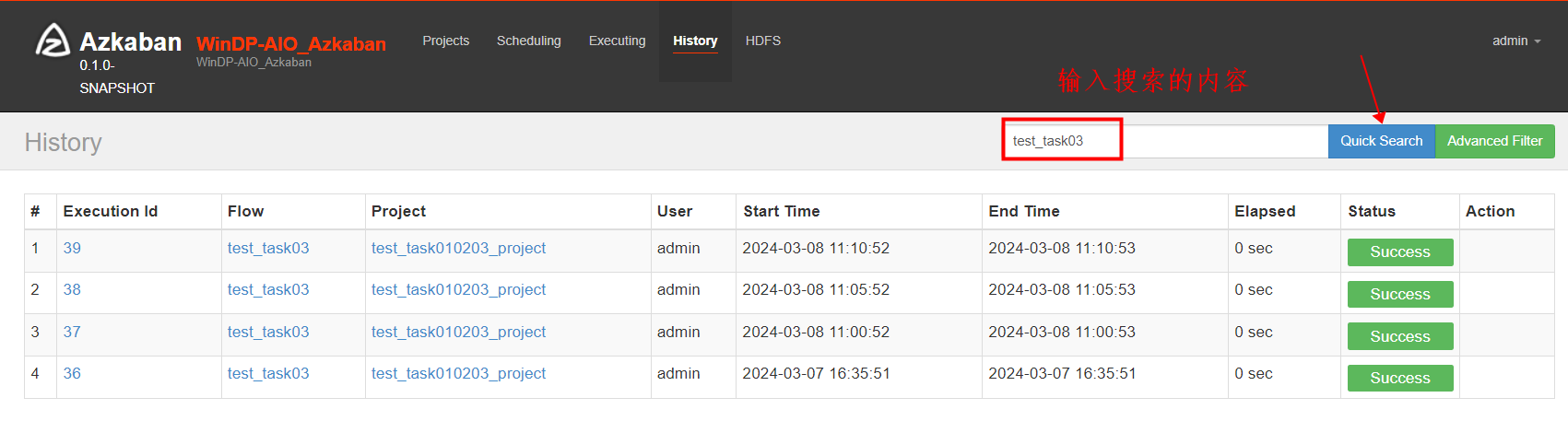
如下图为菜单History 提供的历史任务搜索功能,包括:快速搜索和高级过滤。

如下使用快速搜索在搜索栏中输入“test_task03”,点击“Quick Search”完成搜索。
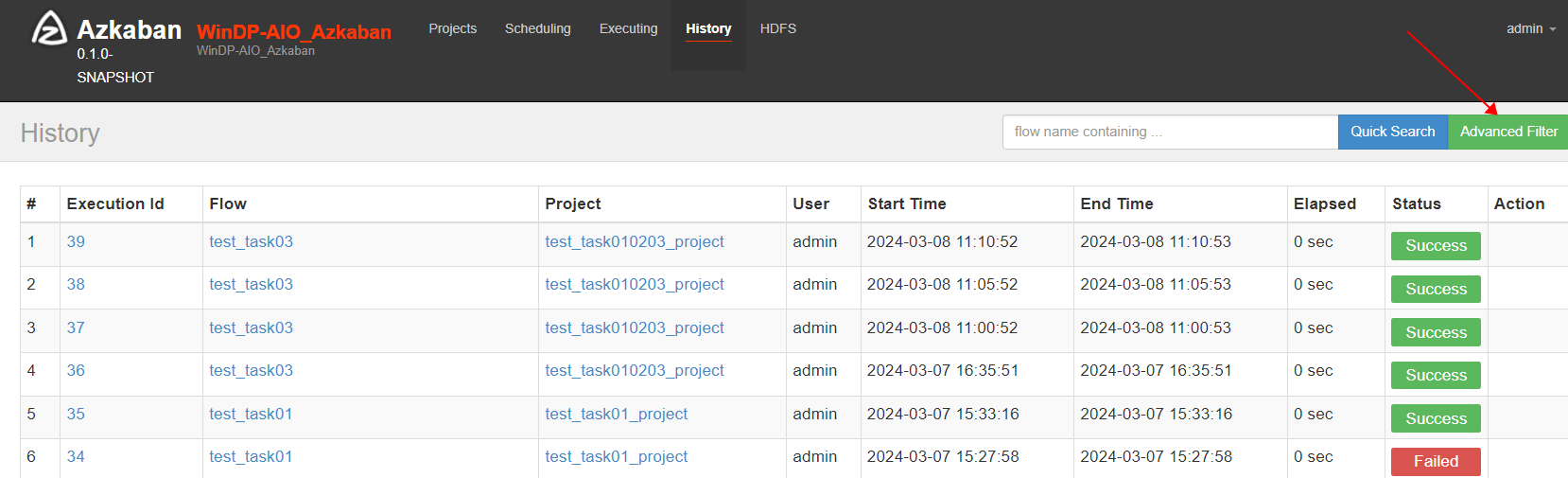
选择“Advanced Filter”
任务状态选择搜索“Failed”的所有历史任务
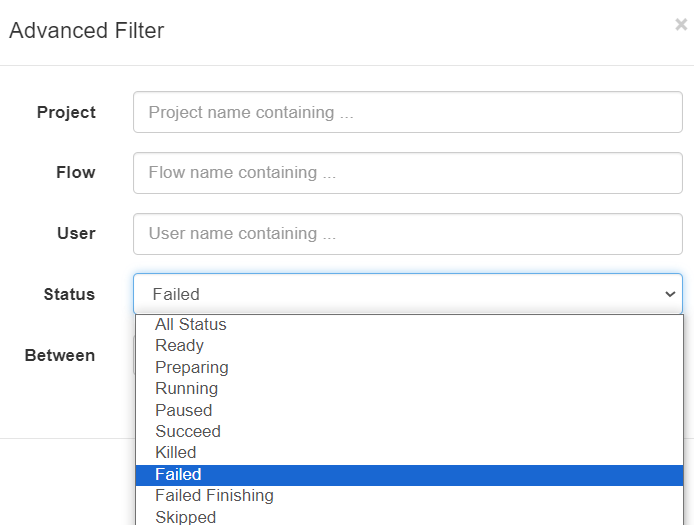
选择“Filter”

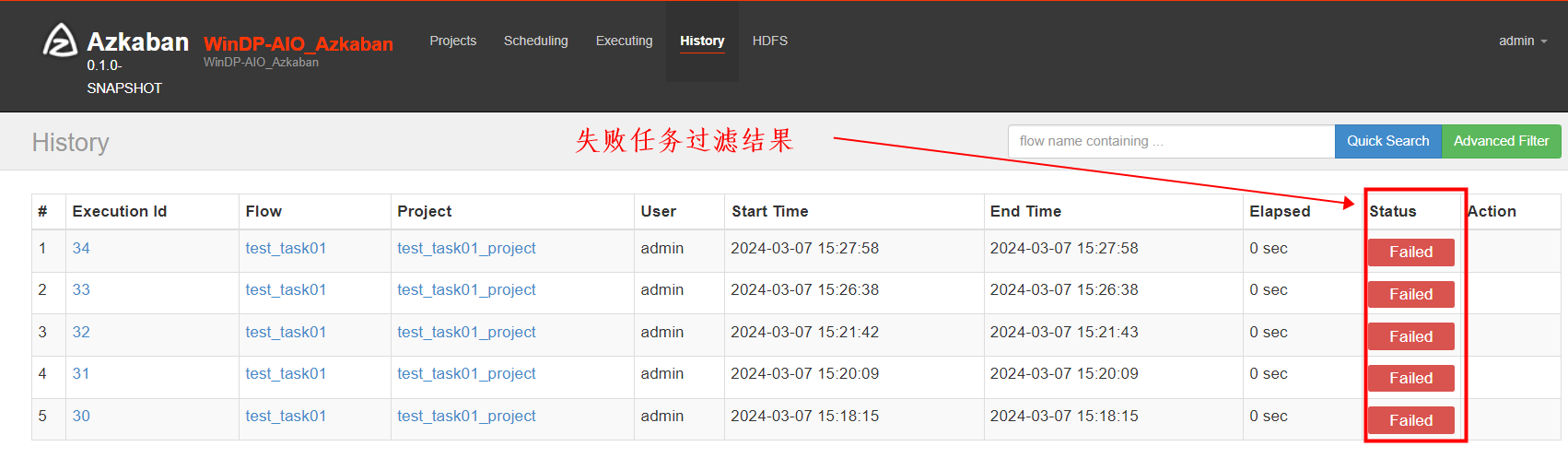
如下图会显示所有失败任务:
四、Azkaban新增用户
编辑文件/hadoop/azkaban/azkaban-web/conf/azkaban-users.xml
vim /hadoop/azkaban/azkaban-web/conf/azkaban-users.xml
<user username="winner_spark" password="winner@001" groups="group_inspector" menus="history,hdfs"/><group name="group_inspector" roles="inspector" /><role name="inspector" permissions="READ"/>
menus="history,hdfs" 表示配置限制只读用户winner_spark拥有history,hdfs两个菜单的查看权限。
添加完成后,“wq”保存退出。执行如下命令重启Azkaban:
cd /opt/azkaban-deploy
sh startAzkaban.sh restart重启完成

登录Azkaban Web页面,登录地址 https://xxxxx:8444/, 使用账号密码: winner_spark/winner@001
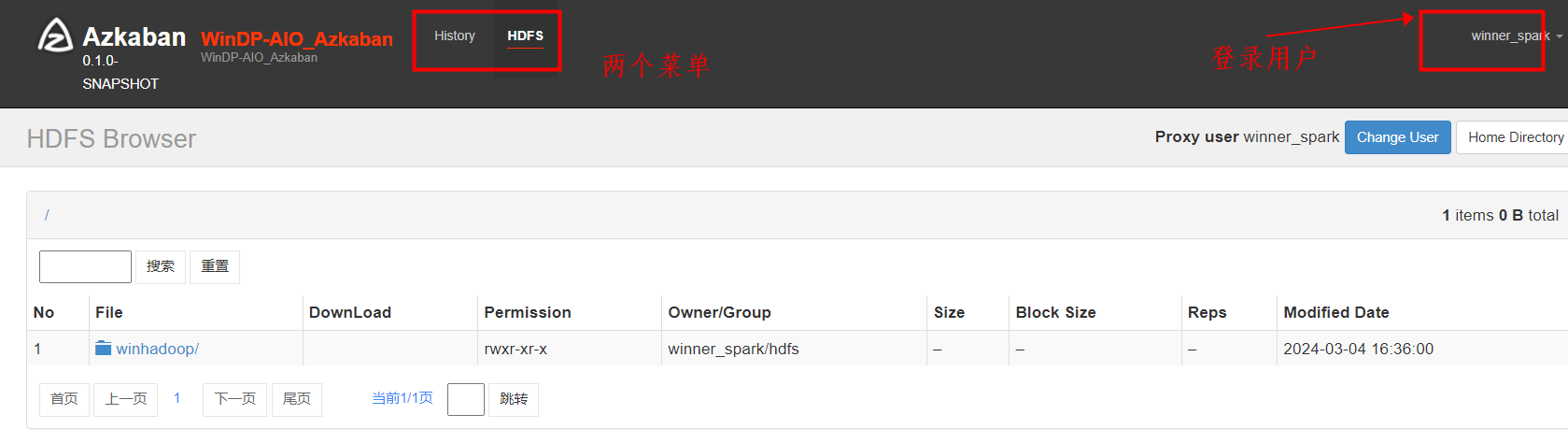
从上图中可以看到只读用户winner_spark拥有history,hdfs两个菜单的查看权限。默认不配置拥有全部菜单的操作权限。
这篇关于【调度工具】Azkaban用户手册的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







