本文主要是介绍计算机网络:数据链路层 - 点对点协议PPP,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
计算机网络:数据链路层 - 点对点协议PPP
- PPP协议的帧格式
- 透明传输
- 字节填充法
- 零比特填充法
- 差错检测
- 循环冗余校验
对于点对点链路,PPP协议是目前使用最广泛的数据链路层协议。比如说,当用户想要接入互联网,就需要通过因特网服务提供者ISP:

这些 ISP 已经从英特网管理机构申请到了一批 IP 地址,用户计算机只有获取到 ISP 所分配的合法 IP 地址后,才能成为因特网上的主机。而用户计算机与 ISP 之间进行通信时,所使用的数据链路层协议就是 PPP 协议。另外,点对点协议 PPP 也广泛应用于广域网路由器之间的专用线路。
PPP协议的帧格式
PPP协议的帧格式如下:

以上帧格式中,各区域功能如下:
F:出现于整个帧的首尾,都是标志字段,也就是PPP帧的定界符,
帧定界符用于帮助接受方区分一个帧,这个标志字段规定为十六进制的0x7E,在ASCII码表中代表字符'~'。
A:地址字段,没有实际意义
C:控制字段,没有实际意义
在设计PPP协议之初,考虑以后再对这两个字段的值进行其他定义,但至今也没有给出,因此这两个字段并不携带什么信息。其中A被规定为十六进制的0xFF,C被规定为十六进制的0x03。
协议:指明信息部分的类别
上图中,网络层把数据段交给数据链路层封装成帧,而协议这个字段的作用就是用于指明网络层传来的数据的种类。该字段占两个字节,当协议字段为十六进制0x0021,PPP中的信息字段就是IP数据报;当协议字段为十六进制0xC021,PPP中的信息字段就是LCP分组;当协议字段为十六进制0x8021,PPP中的信息字段就是NCP分组。
FCS:用于差错检测
此处使用的时CRC循环冗余校验,这个在博客后文会讲解。
信息部分:即上层传递下来的,被封装成帧的数据
这个信息字段的长度不是固定的,但是如果信息字段太长,就会导致分组的效率变低,因此规定信息字段的长度不超过1500 byte。
数据链路层的三大问题在于:封装成帧,透明传输,差错检测。
现在我们已经了解了PPP协议是如何封装成帧的,接下来我们再来看看PPP协议是如何完成透明传输的。
透明传输
字节填充法
当PPP使用异步传输时,以字节为单位传输数据,采用字节填充法来实现透明传输,字节填充法采用转义字符实现对数据段中的0x7E的转义。
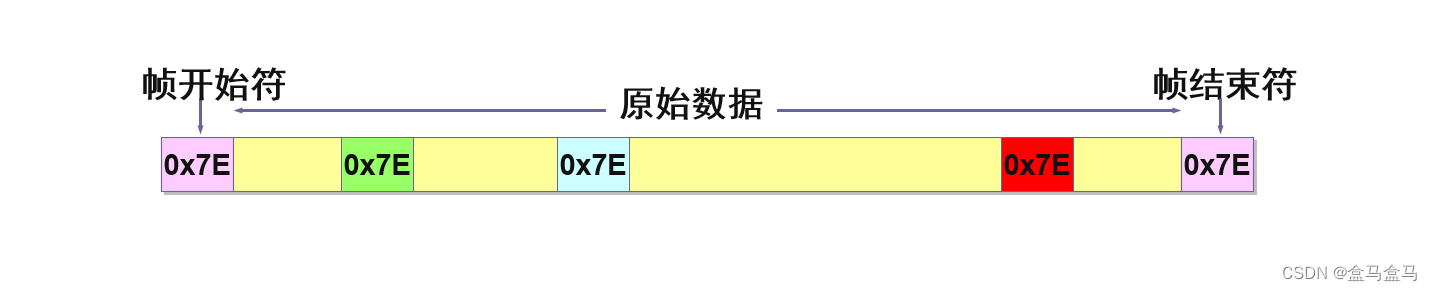
比如上图中,如果我们只考虑两个帧定界符,不考虑地址字段,控制字段和FCS。帧定界符的十六进制为0x7E,但是如果数据段中也出现了0x7E,这该怎么办?
这就会导致一个问题,那就是对帧的拆分错误,比如上图中,第一个粉色的0x7E是帧开始符,最后一个粉色的0x7E是帧结束符。但是数据段中还有三个0x7E,因此接收方就有可能把第一个粉色的符号当作帧的开始,而第二个绿色的符号当作帧的结束。这就会造成错误的帧划分,以及错误的数据接收。因此我们要对数据段中的0x7E数据段进行特殊处理,让接收端可以区别数据段中的0x7E与帧定界符。
处理方式为字节填充,规则如下:
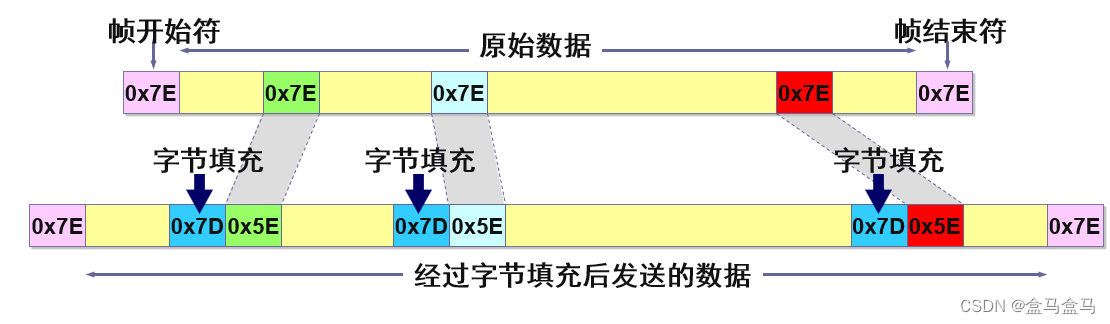
当在数据段中遇到
0x7E,先将0x7E的第五个比特位取反变成0x5E,再在其前面插入0x7D
在数据段中遇到0x7E,就把0x7E第五位取反,为0x5E,然后再在其前面插入一个0x7D。这样只要接收方在读取数据的时候,只要遇到了0x7D这个转义字符,就把这个转义字符丢弃,再将其后一位字节的第五位取反,就得到了原先的数据。
但是我们还有一个问题,如下:

如果原本的数据段中就有转义字符0x7D,那么接收方又要如何识别这是一段数据,而不是一个转义字符呢?
当在数据段中遇到
0x7D,先将0x7D的第五个比特位取反变成0x5E,再在其前面插入0x7D
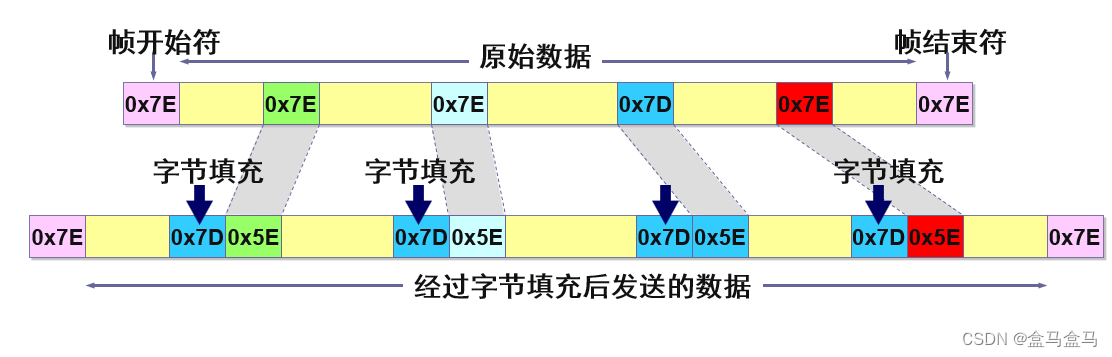
用和之前相同规则,当接收方遇到0x7D,就把0x7D丢弃,然后把后面的0x5E的第五位取反,得到原始数据。
另外的,PPP协议对数据段还有额外的处理,在所有字符中,还有一些控制字符,即ASCII码表中的0 - 32号字符,以及第127号字符。这些字符才数据段中也要处理:
当在数据段中遇到控制字符,将该字符的第五个比特位取反,再在其前面插入
0x7D
和之前一模一样的方法,不再赘述了。
字节填充汇总如下:
一旦遇到
0x7E帧定界符,0x7D转义符,以及控制字符,就将其第五位取反,再在其前面插入一个0x7D转义
接收方受到数据后,只要遇到
0x7D转义符,就把该符号丢弃,然后将其后一个字节的数据,第五位取反
零比特填充法
当PPP使用同步传输时,以比特为单位传输数据,采用零比特填充法来实现透明传输。
零比特填充法规则如下:
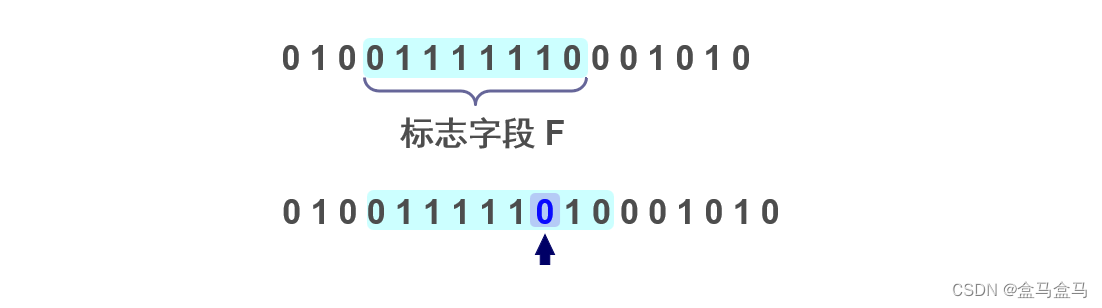
当在数据段中遇到连续的五个
1,就在其后面插入一个0
PPP协议中,帧定界符是0x7E,转为2进制就是01111110,其中出现了连续的六个1。为了保证数据部分中的数据不会被判断为定界符,于是只要数据段中出现连续的五个1就插入一个0,这样就只有帧定界符中会出现连续的六个1。
当接收方接收时,只需要在遇到五个1时,看其后面的一位,如果第六位为1,说明这是帧定界符。如果第六位为0,说明这个0是插入的,把它删除后还原出原始数据。
差错检测
再来看差错检测,发送方将封装好的帧通过物理层发送到传输媒体。帧在传输过程中遭遇干扰后,可能会出现误码,也就是比特 0 可能变成了比特 1,反之亦然。
在一段时间内,传输错误的比特占所传输比特总数的比率,称为误码率。
但是接收方主机如何判断帧在传输过程中是否出现了误码呢?
这可以通过检错码来发现。发送方在发送帧之前基于待发送的数据和检错算法计算出检错码,并将其封装在帧尾。接收方主机收到帧后,通过检错码和检错算法就可以判断出帧在传输过程中是否出现了误码。
循环冗余校验
在PPP协议中,使用了循环冗余校验 CRC 的检错技术。
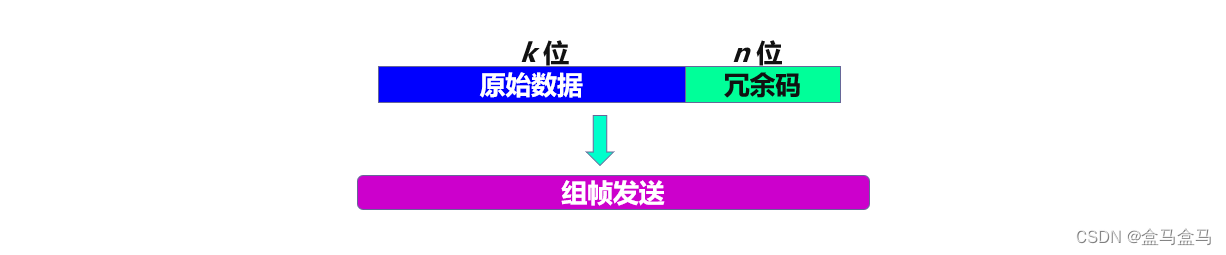
假定发送端发送的原始数据为k个比特,对原始数据进行CRC运算,产生了n位冗余码FCS,把n位冗余码FCS放入帧的末尾一起发送出去。
那么我们现在就来讲解一下这个冗余码FCS是如何计算的:
- 在原始
k位数据后面加n个0- 用指定的
n + 1位除数p,对这个k + n位的数据段做模2除法- 最后得到的
n位除数就是冗余码FCS,用冗余码FCS替换最后的n位0
假设我们现在的原始数据为101001,约定的除数p为1101:

除数p为4位数,那么n就是4 - 1 = 3位,因此在101001后面添上3位0:

现在就可以开始进行模2除法了:
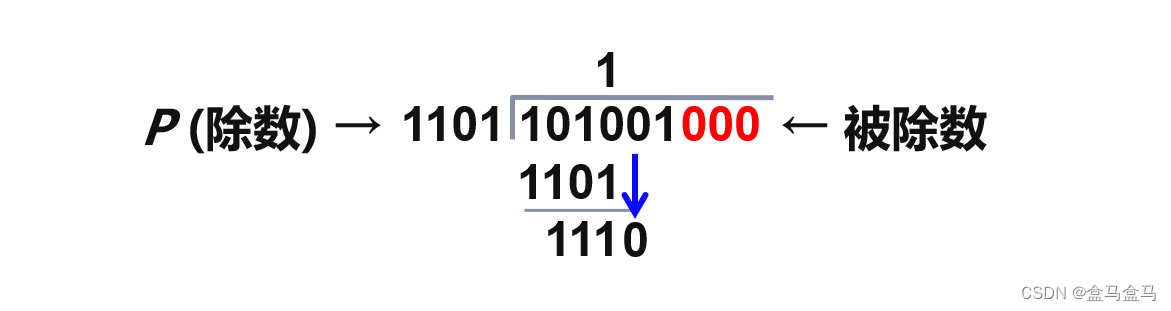
所谓模2除法,就是每次进行相除操作时,上下按位异或,比如以上式子中1010和1101按位异或就是0111,在后面补一位0就是1110。以此类推,一直计算下去:

由于我们的除数p是n + 1位,所以最后的余数一定是小于等于n位的,如果不够n位就在前面补0,补到n位。然后把这n位除数替换掉原数据中的n位0,得到101001 001。
101001 001这一段数据中,101001是原始的数据, 001就是冗余码FCS。
一开始我们拿p除以101001 000,余数为001。我们把001补上去后,数据变成了101001 001,那么p除以101001 001就应该是0。因此如果接收端用p除以k + n位数据等于0,就说明数据没有出问题,是正常的。但是如果结构非0,说明有比特位出现了差错,那么接收端就可以知道传输出问题,进行后续操作了。
要注意的是,这个除数p是一开始双方就约定好的,因此双方都是知道拿p去除以这个数据段。
这篇关于计算机网络:数据链路层 - 点对点协议PPP的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





