本文主要是介绍(四) 序列化器类使用整理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从一、序列化器类中,或 视图集源码 中,
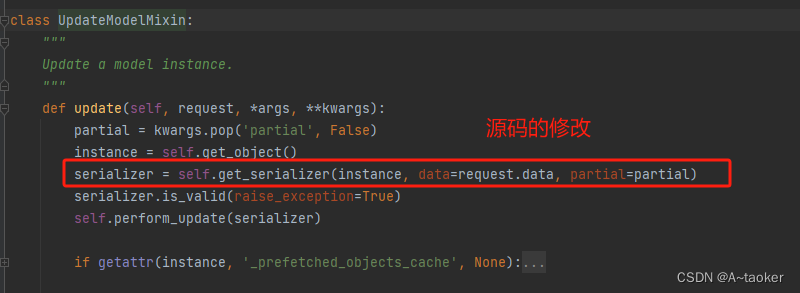
可以得知:
序列化器类可以接收一个instance ,和一个data
serializer_obj =XxxxSerializer(instance,data=request.data)
(更新时,instance相当于原来的值,data是前端传来的新的值)
当data有接收到值时,serializer_obj.is_valid(), 这个方法才可以使用。
调用序列化器
- 正常的写法: serializer_obj = XxxxSerializer(instance,data=request.data)
- 如果data接收了有东西,serializer_obj .data表示:校验通过后的值serializer_obj .validated_data值。 (如果某个字段为write_only=True,serializer_obj .data输出还没有这个地段 )
- 在视图集中:定义action方法时可以这么写: serializer_obj =self.get_serializer(instance, data=request.data)
- 因为视图集中GenericAPIView类提供了get_serializer(参数1,参数2) 的方法
- 视图集中(用的少),action方法中,或者这样写get_serializer_class()(参数1,参数2)
得到一个序列化器对象 serializer_obj后,可以调用serializer_obj.save() 方法,序列化器类会自己判断,
- 如果只传了data,执行save方法时,是模型序列化器类 自带的create
- 如果传了instance 和data,执行save方法,是模型序列化器类自带的的update
- save方法,可以传值,数据也是拼在 validated_data数据 或 覆盖(如果有同样的),校验通过后的数据里面, 举例有一些请求参数需要后端自己生成,比如创建人更新人
模型序列化器类本身
一:模型序列化器类中,自带了create 和update方法
是可以修改的
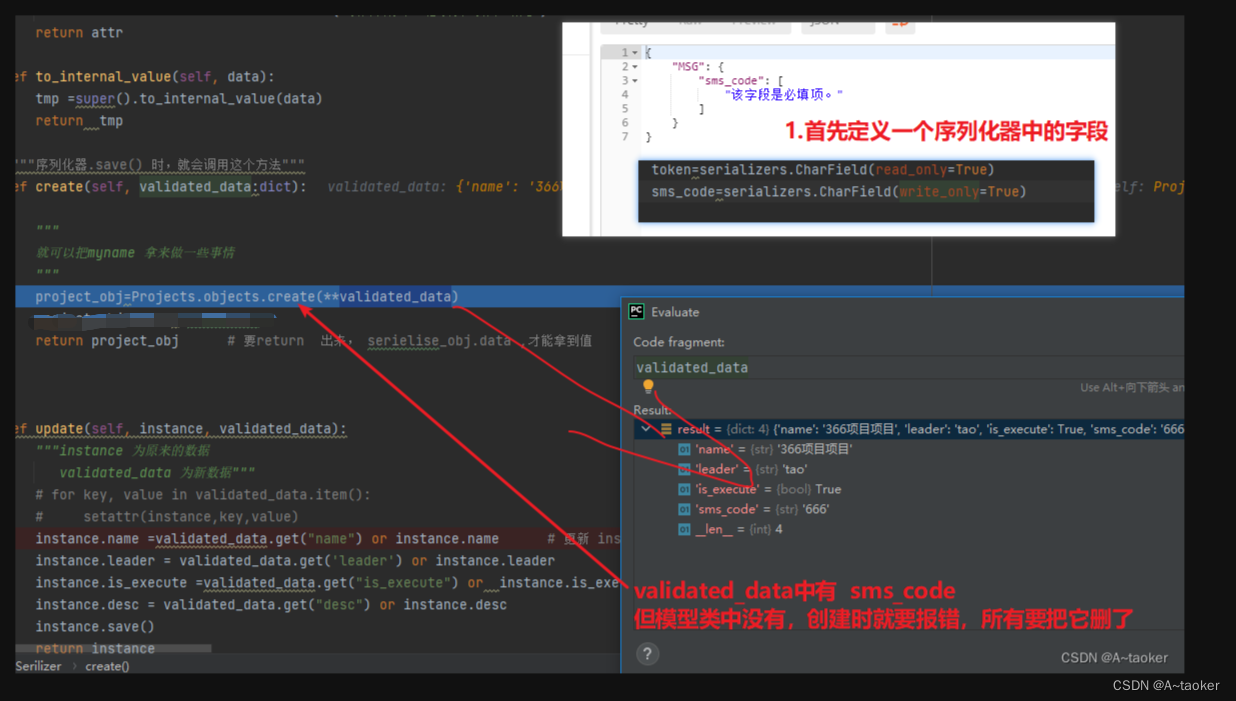
自带的create方法,和update方法,会接收validated_data数据,也就是新增,或者更新校验通过的数据。 举例: 注册时需要传短信验证码code,但又不需要入库,传了code会报错,就可以再create方法里把code删了(备注见下图,可以知create和update的执行是在校验之后进行的)下面有举例

二:序列化器类中,还有多字段校验方法,def validate(),校验入口方法,单字段校验方法def validate_name():
顺序为:

validate方法,会接收一个对象。即前端传来的东西,在这里可以进行多字段校验
它的返回,就返回 接收的参数

举例
1. 使用seve()方法传值【视图集中】
在视图集中,调用save方法的地方,传递了值
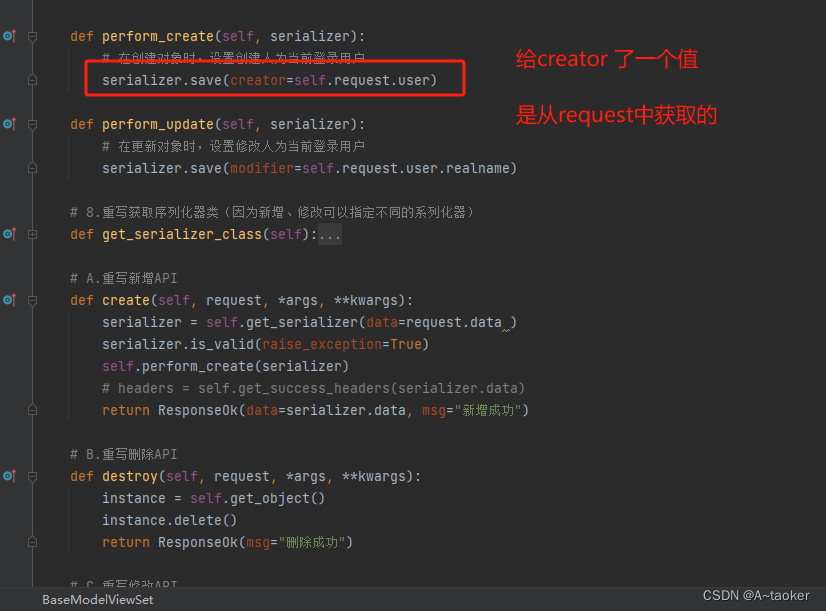
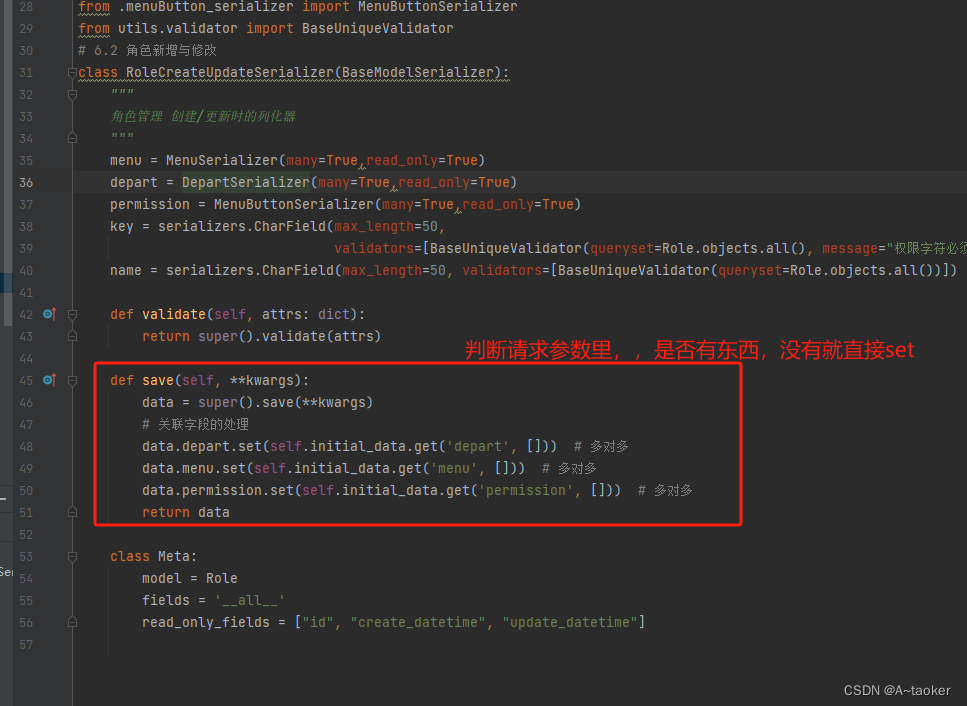
2. 重写save() ,即同时重写了create和update【序列化器中】
3. 重写序列化器类中的create方法案例【序列化器类中】
a. 不入库的多余请求参数处理
注册用户时,需要传短信验证码,但是短信验证码又不需要入库
b. 新增之后,想把一些东西返回出来
如:注册接口,想实现注册就登录的效果,需要在注册接口响应中,返回token,就可以再create中去增加这个值, 它是再执行了create方法之后加的,就不影响入库
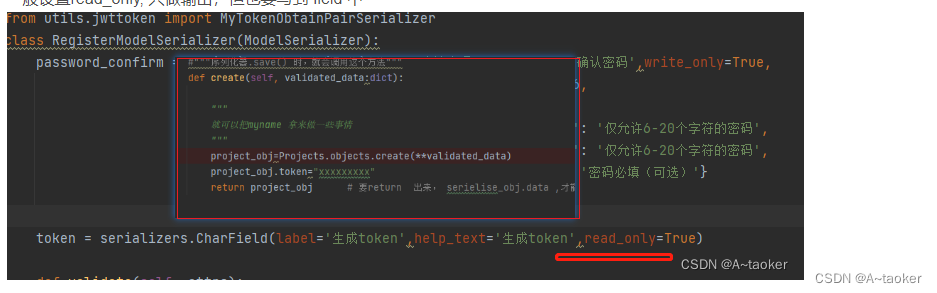
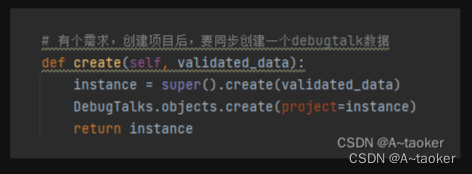
b. 创建一个模型对象时,同时创建另一个模型对象
柠檬班的项目:修改了项目序列化器的新增 create方法,让它可以项目的同时,可以新增一个debugtalk
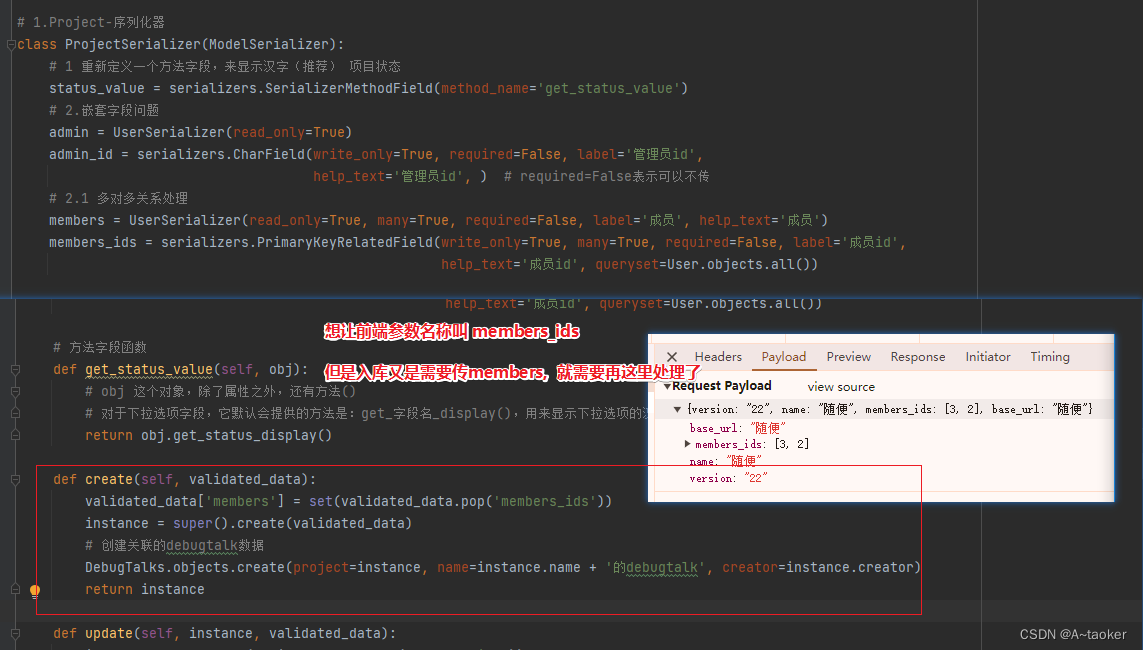
c. 自定义请求参数名称
首先:想让前端传 这个名称 members_ids,但是又不符合入库的名字,就要处理
对前端传递的字段做处理,修改成入库需要的字段数据
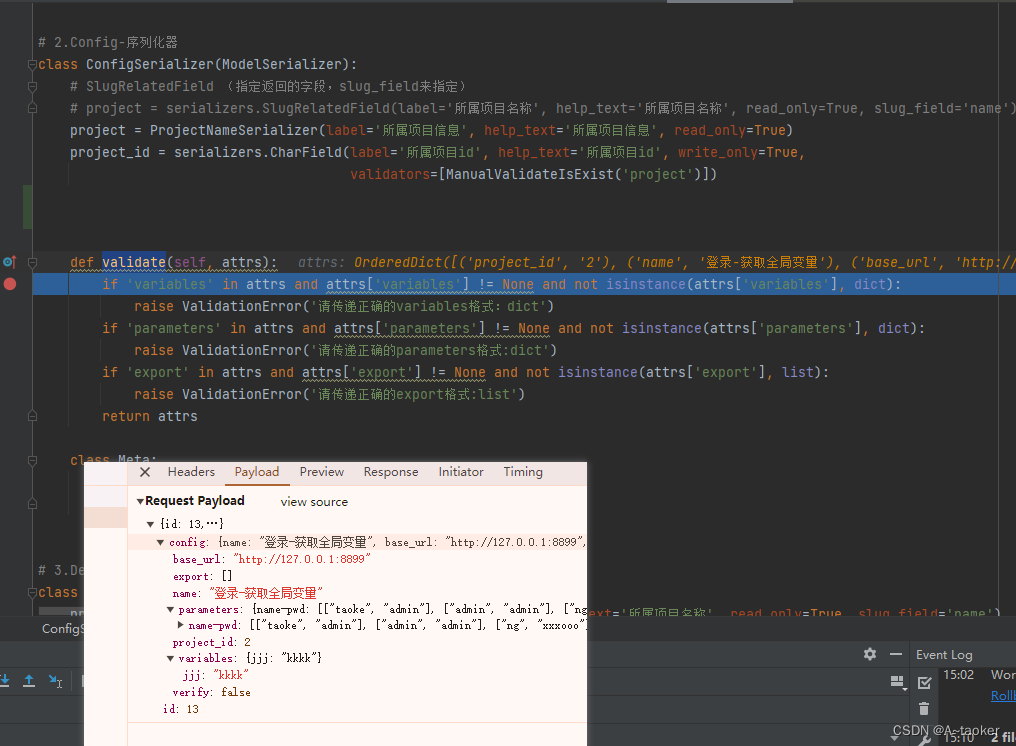
4 . 写多字段校验方法validate()
1. 保存config时,校验了每个参数了的格式是否为符合要求的格式, 因为它接收一个字典,就随便写了一个叫attrs的参数名称
返回也是返回的 接受的内容
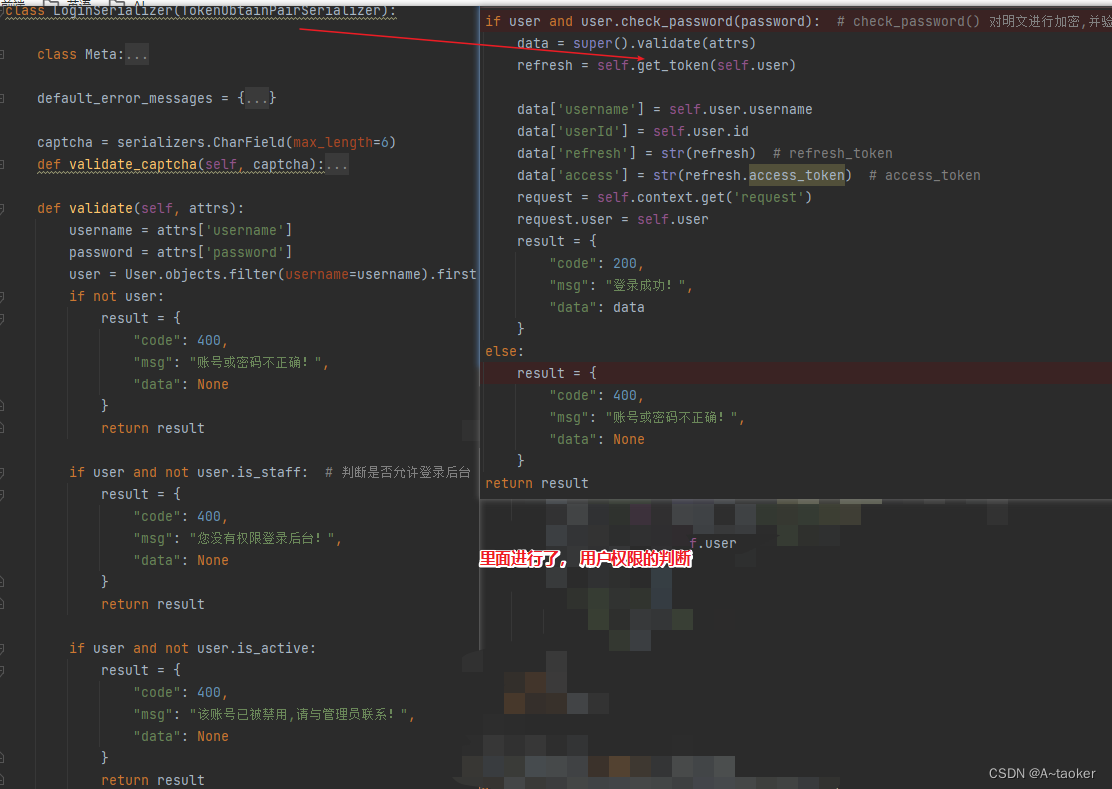
2 .登录序列化器中(这里面的validate相当于是重写TokenObtainPairSerializer序列化器类的validate,返回的即是响应
 5. 常见字段处理的情况
5. 常见字段处理的情况
1. 想要响应中是值而不仅仅是code
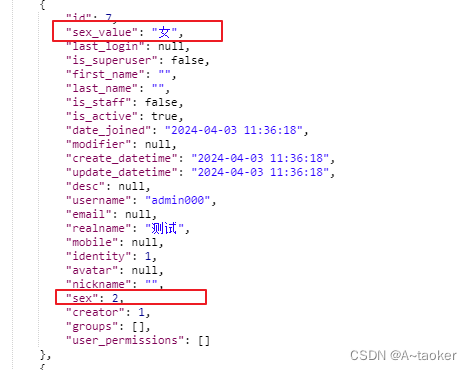
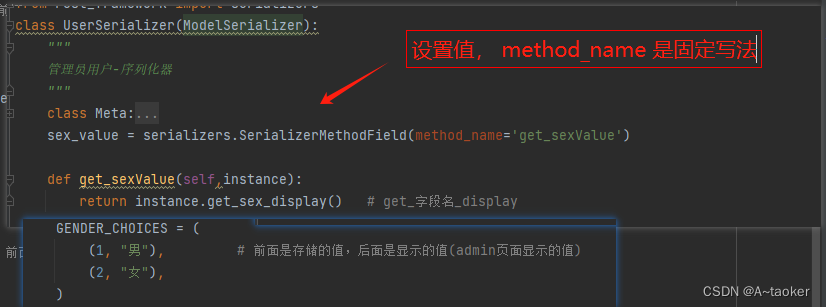
2. 对于外键字段处理
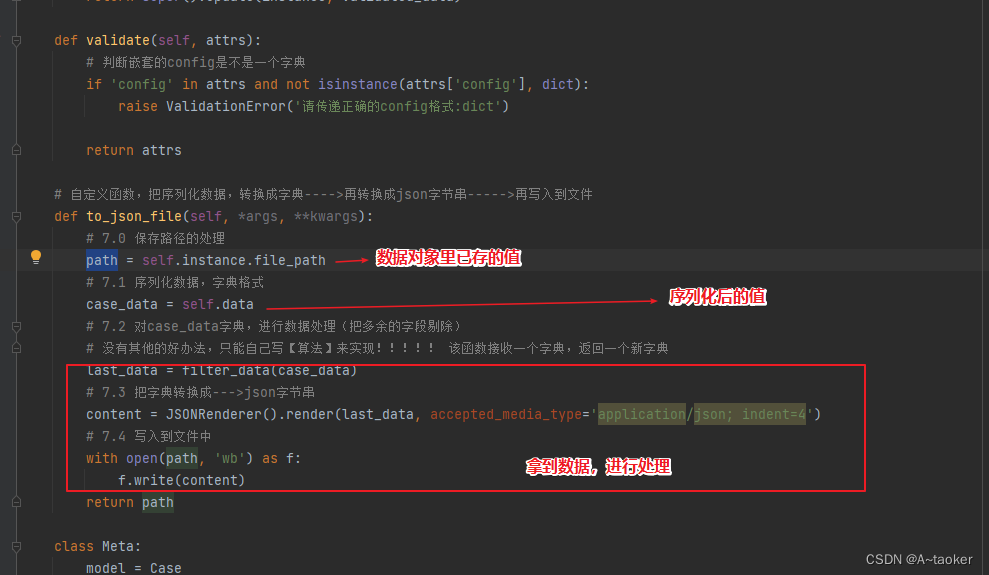
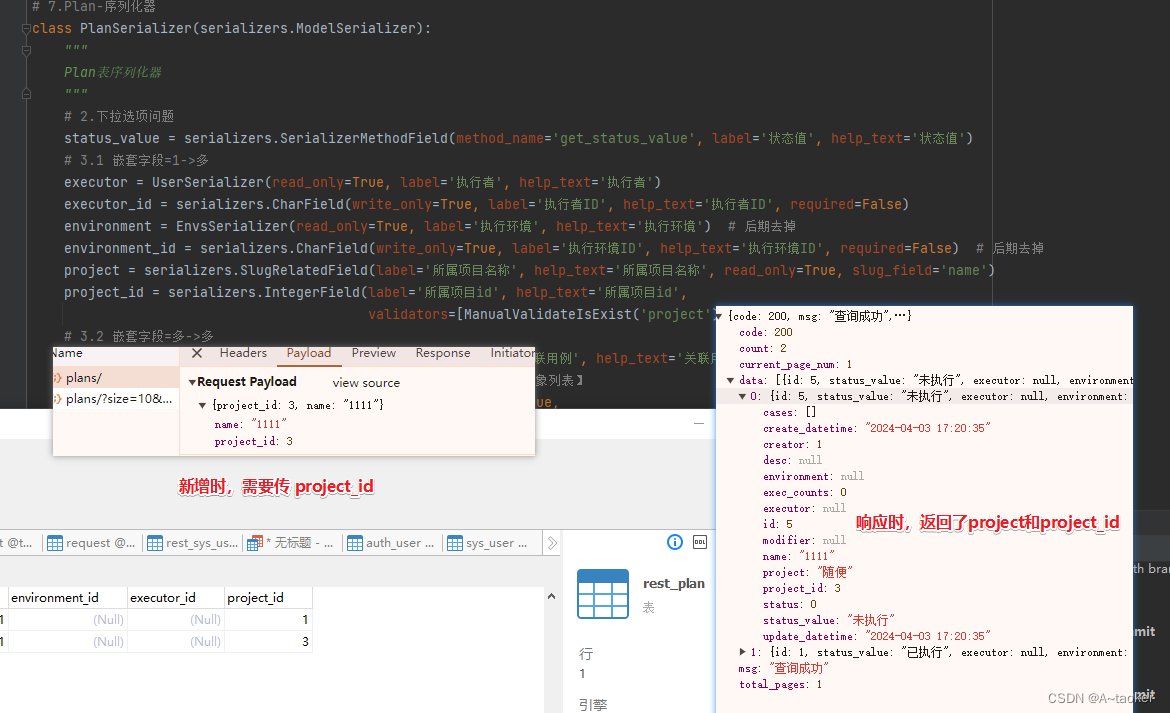 6. 序列化器类中,自定义方法
6. 序列化器类中,自定义方法
在定义时,可以很方便的拿到数据对象的某个值,以及序列化后的值,就可以拿到数据进行处理
可以使用:self.instance 和 self.data, 进行拿值
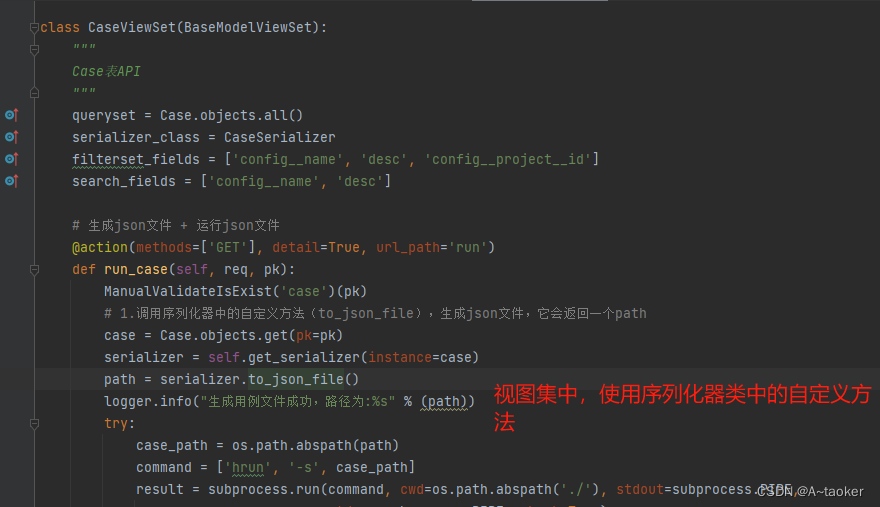
序列化器类中的方法,又很方便被视图集使用
这篇关于(四) 序列化器类使用整理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


