本文主要是介绍贵州省NPP净初级生产力数据/NDVI数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据福利是专门为关注小编博客及公众号的朋友定制的,未关注用户不享受免费共享服务,已经被列入黑名单的用户和单位不享受免费共享服务。参与本号发起的数据众筹,向本号捐赠过硬盘以及多次转发、评论的朋友优先享有免费共享服务。
净初级生产力NPP数据
引言
第一性生产力是绿色植物呼吸后所剩下的单位面积单位时间内所固定的能量或所生产的有机物质,即是总第一性生产量减去植物呼吸作用所剩下的能量或有机物质。多种卫星遥感数据反演净初级生产力(NPP)产品是地理遥感生态网平台推出的生态环境类系列数据产品之一。
正文
数据简介
植物通过光合作用将太阳能固定并转化为植物生物量。单位时间和单位面积上,绿色植物通过光合作用产生的全部有机物同化量,即光合总量,叫总初级生产力(Gross Primary Productivity,GPP);净初级生产力则是由光合作用所产生的有机质总量中扣除自养呼吸后的剩余部分。净初级生产力(net primary productivity,NPP)是生产者能用于生长、发育和繁殖的能量值,也是生态系统中其他生物成员生存和繁衍的物质基础。
贵州,地处中国西南内陆地区腹地。境内地势西高东低,自中部向北、东、南三面倾斜,平均海拔在1100米左右。贵州的气候温暖湿润,属亚热带湿润季风气候。
地理遥感生态网提供的NPP数据基于CASA模型估算,其计算植被NPP的基本思想是利用植被获取太阳辐射, 加上植被自身利用的情况, 从而估算出植被净生长状况。模型中所估算的NPP可以由植被吸收的光合有效辐射(APAR)和实际光能利用率(ε)两个因子来表示, 公式如下:
|
|
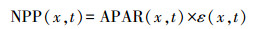
式中, x代表单个像元, t表示月份, APAR(x, t)则表示像元x在t月吸收的光合有效辐射(gC/m2), ε(x, t)表示单个像元x在t月的实际光能利用率(gC/MJ)。

| 数据名称 | 净初级生产力NPP数据 | |
| 数据类型 | 栅格 | |
| 数据格式 | GRID、TIFF | |
| 分辨率/比例尺 | 10m、30m、100m、250m、500m、1km等多种分辨率 | |
| 覆盖范围 | 全境陆地国土 | |
| 坐标系 | 默认投影为Krasovsky_1940_Albers,其他坐标系可进行投影转换 | |
| 时间序列 | 基本时间序列: 1980年-至今;时间尺度逐月逐年 | |
《10米精度NPP净初级生产力数据集》共享方法如下:
(1)人员,限定为关注小编的用户。
(2)各类项目(包括各类科研项目)申请本数据扔享受免费政策,但需向本号捐赠一定数量的硬盘才能获取。
(3)捐赠硬盘可免留言获取数据。
地理遥感生态网上分享了很多地理遥感领域的科学数据(土地利用数据、npp净初级生产力数据数据、NDVI数据、径流量数据、夜间灯光数据、统计年鉴、道路网、POI兴趣点数据、GDP分布、人口密度分布、三级流域矢量边界、地质灾害分布数据、土壤类型、土壤质地、土壤有机质、土壤PH值、土壤质地、土壤侵蚀、植被类型、自然保护区分布、建筑轮廓分布等等地理数据,以及关于gis、遥感从方面的操作教程)。
原文链接:https://bbs.csdn.net/forums/gisrs?spm=1001.2014.3001.6682
这篇关于贵州省NPP净初级生产力数据/NDVI数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







