本文主要是介绍【进程OI】重定向的本质用户级缓冲区,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 用实验观察重定向的原理
- 实验一:
- 实验二:
- 用户级缓冲区
- 重定向的本质
- dup、dup1、dup2函数
- dup()
- dup2()
用实验观察重定向的原理
实验一:
本节内容需要同学们了解文件描述符的原理,有需要的可以去看我之前写的博客:
详细讲解文件描述符
观察以下代码的输出结果:
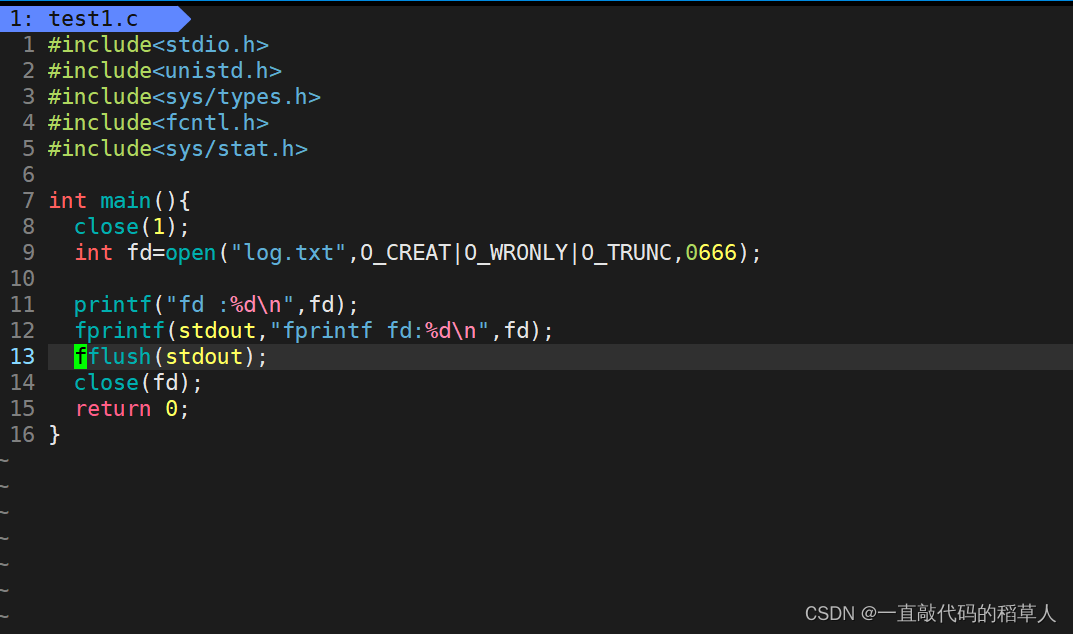

上面代码看起来人畜无害,但是仔细观察我们就会发现几个问题:
1.为什么log.txt文件的文件描述符是1?
这跟文件描述符的分配规则有关。每个进程新打开一个文件,其内核会给返回一个:files_struct数组中,当前没有被使用的最小的一个下标作为文件描述符。每个进程会默认打开三个文件:stdin、stdout、stderr,分别对应的文件描述符为0、1、2.又因为上面代码关闭了1(stdout),在打开新文件log.txt时,内核会根据分配规则,把整数1作为该文件的描述符。
2.为什么向stdout写入的数据会在log.txt中?
我们注意到代码printf()和fprintf()明明是向显示器即stdout文件输入信息,最后却发现写入到log.txt里面去了,这是非常典型的重定向现象。这是为什么呢?
在c语言中,stdout是个FILE*结构体类型,其封装的文件描述符默认为1。printf()和fprintf(stdout)实际上是在向文件描述符为1的文件写入数据.底层的系统调用write只认文件描述符。此时文件描述符为1的文件是log.txt,所以数据会写入到该文件中。
fprintf(stdout,…)等价于write(1,…)
通过实验一我们观察到了非常有趣的重定向现象,即:修改输出(输入)的目标文件!
在实验一代码的基础上,我们改动一点点,会发现非常有趣的现象。
实验二:
观察以下代码的输出结果分别是什么:
代码1:
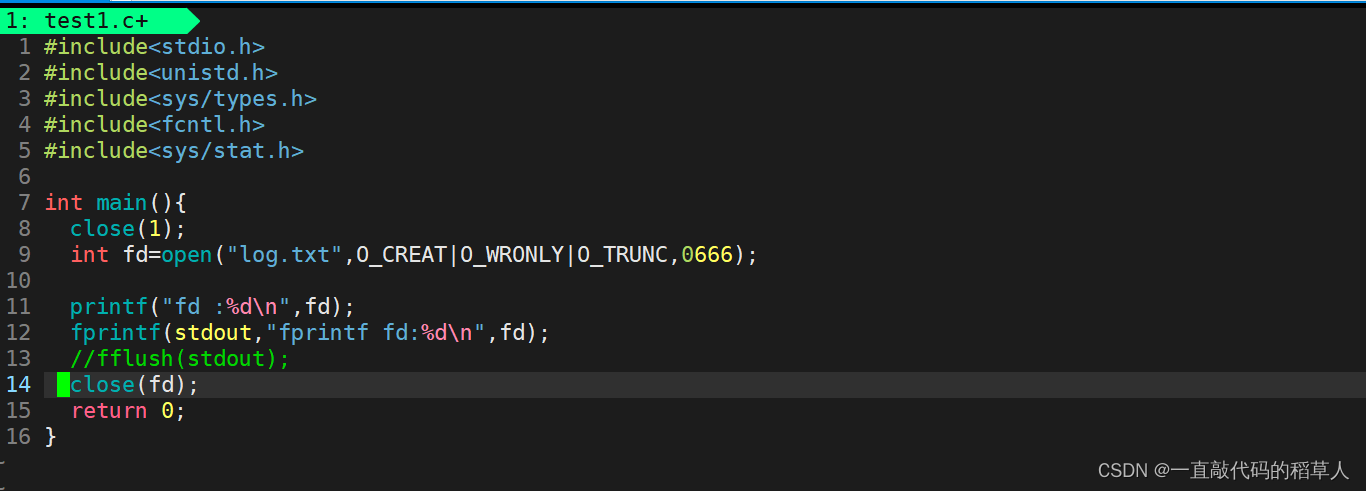

仅仅是注释掉fflush之后,文件log.txt就没有被写入数据了!
我们很容易想到的是,fflush的作用是刷新缓冲区。出现上述代码现象的原因可能是因为数据在close(fd)之前还在缓冲区内。
值得注意的是,fflush的作用是将用户级缓冲区的数据刷新到内核级的缓冲区。
关于内核级的缓冲区在我讲文件描述符的那篇博客里有详细讲解。那么用户级缓冲区的作用是什么?和内核级缓冲区的区别在那里呢?
用户级缓冲区
用户级缓冲区是由应用程序直接管理和控制的内存区域。这些缓冲区位于应用程序的地址空间中,应用程序可以直接访问和操作它们,而无需进行系统调用。
也就是说,我们在语言层面上也有一个自己的缓冲区,我们使用库函数printf()或者fprintf()向文件写入数据时,会先加载到这个用户级缓冲区里面,并不会直接加载到内核级缓冲区中。
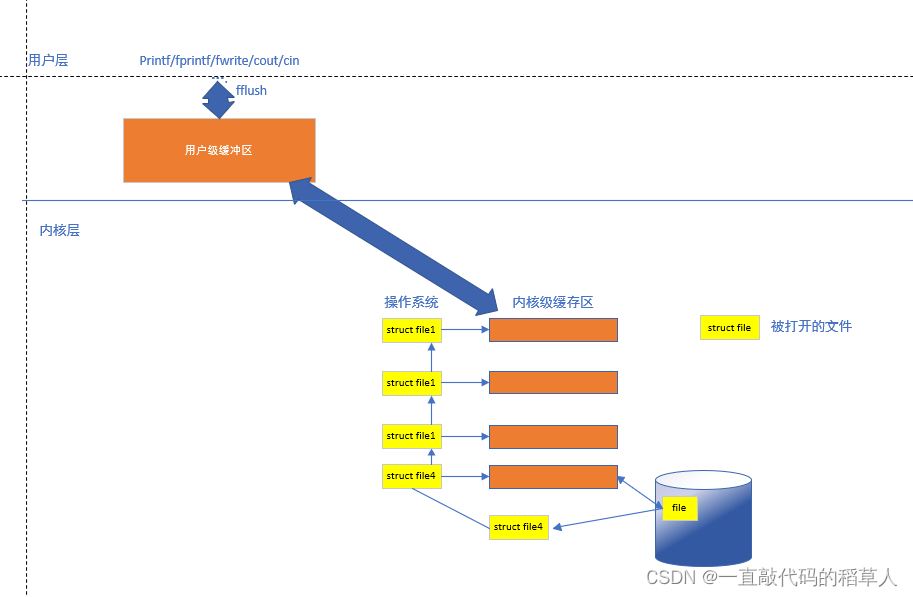
一旦我们用fflush将用户级缓冲区里的数据流刷新到内核级缓冲区之后,剩下的工作就是内核去完成的了,我们也就可以认为该数据流被刷新到磁盘的文件中了。
那么为什么要给程序留一个用户级缓冲区呢?
用户级缓冲区通常用于提高数据传输的效率,减少应用程序与操作系统之间的频繁交互。不必要每次数据交互都访问内核缓冲区,而是可以先存在一个区域中,达到一定量了之后再刷新到内核缓冲区。
对于操作系统来说,如果没有用户级缓冲区,我们每次向文件读写数据都要访问内核,间接加剧了内核访问磁盘的次数。对于用户来说,每次读写操作都要等待操作系统响应,这样无疑会降低用户的体验。所以用户级缓冲区可以提高用户的体验,也可以提高数据传输的效率,
两者的区别:
1.作用位置和范围
用户级缓冲区位于进程的地址空间,连接的是用户程序和内核缓冲区。内核级缓冲区位于操作系统内核的地址空间,连接的是操作系统内部和磁盘文件。
2.性能控制
用户级缓冲区的具体实现方式由用户决定,比较灵活,效率也跟具体的实现方式有关。而内核级缓冲区的实现方式受到操作系统设计影响,一般实现方式是固定的,比较稳定可靠。
3.访问权限
用户级缓冲区由进程程序管理和控制,应用程序可以直接访问和操作用户级缓冲区,而无需进行系统调用。内核级缓冲区由操作系统内核管理和控制。只能通过系统调用来访问和操作。
通过上面对用户级缓冲区的学习,我们再来解释实验二的现象:
我们用printf和fpritnf函数向文件写入数据时,这些数据会先进入用户级缓冲区里面。当我们注释掉fflush,实际上就是没有主动的刷新用户级缓冲区里面的数据。紧接着关闭文件,即使程序结束时会自动刷新用户级缓冲区,但由于在此之前已经关闭了文件log.txt,那些数据也就丢失了。
通过上面的两个实验,我们观察到了“不小心”造成的重定向现象,也对用户级缓冲区有了一定的了解。
重定向的本质
回顾实验一我们就能发现,发生重定向似乎与文件描述符所指向内容被修改有关:原本描述符1指向的是标准输出流文件stdout。
文件描述符指向的内容?其实就是文件数组file_struct* fd_array的内容,文件描述符只是文件数组的某个下标。用更简单的话来说,文件描述符fd所描述的文件就是fd_array[fd]。
如下图:
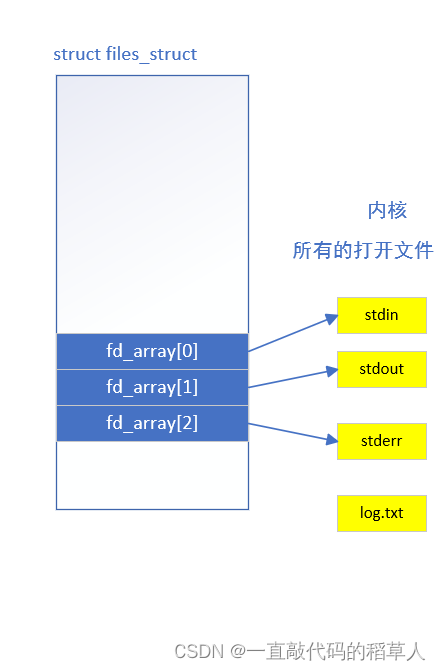
实验一在新建log.txt后文件描述符为1
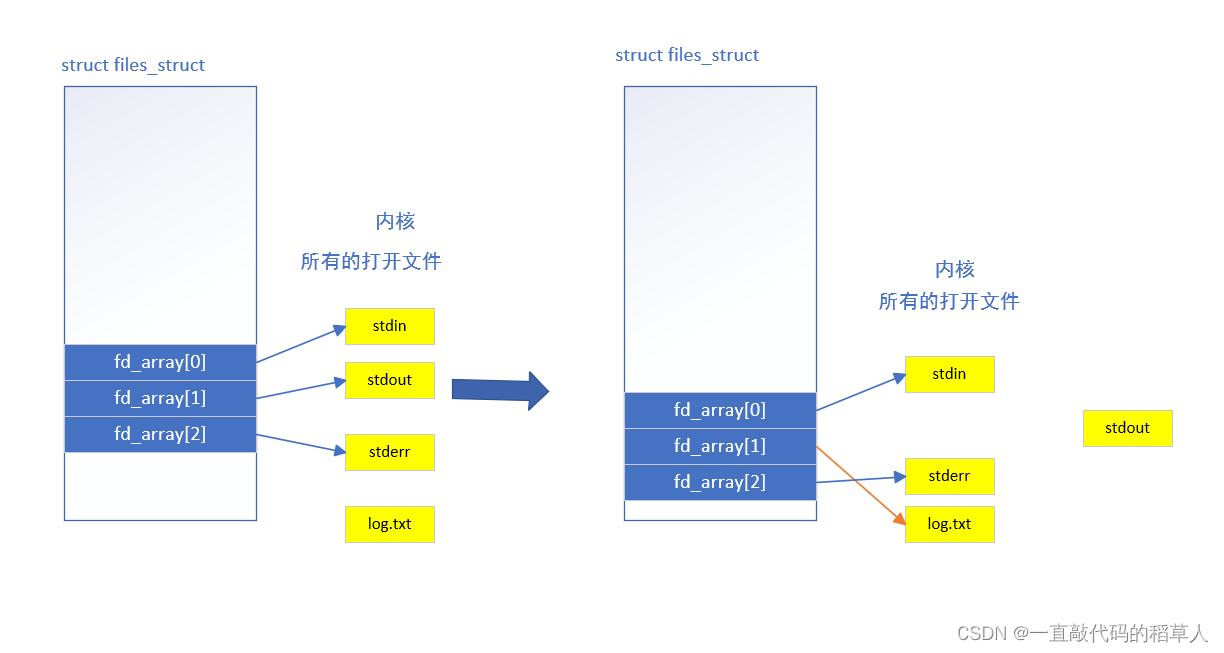
再后来printf和fprintf写入到fd_array[1]中,也就是log.txt里。
重定向的本质就是改变文件数组fd_array[]的内容。
下面介绍几个可以修改文件描述符内容的函数。(文件描述符的内容即对应fd_array的内容)
dup、dup1、dup2函数
dup()
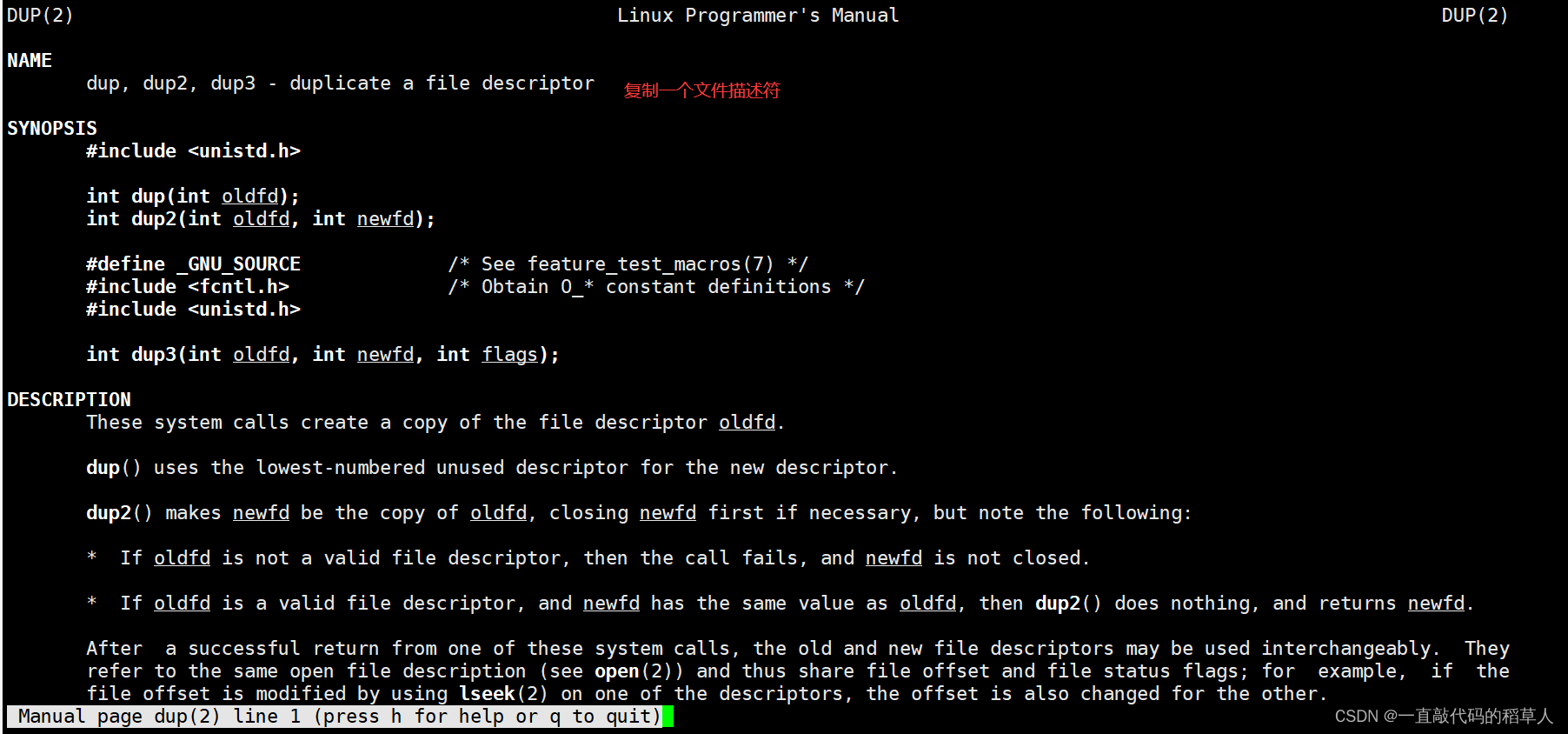
dup 用于复制文件描述符,它会复制当前文件描述符的内容,返回一个新的文件描述符(当前可用的最小的描述符)。由于新旧文件描述符共享同一文件表项,所以文件锁、操作模式、文件偏移量等也是共享的。
dup(fd),实际上就是复制在文件数组中下标为fd的内容到文件数组中的另一个地址空间中。新旧描述符指向的文件是同一个。
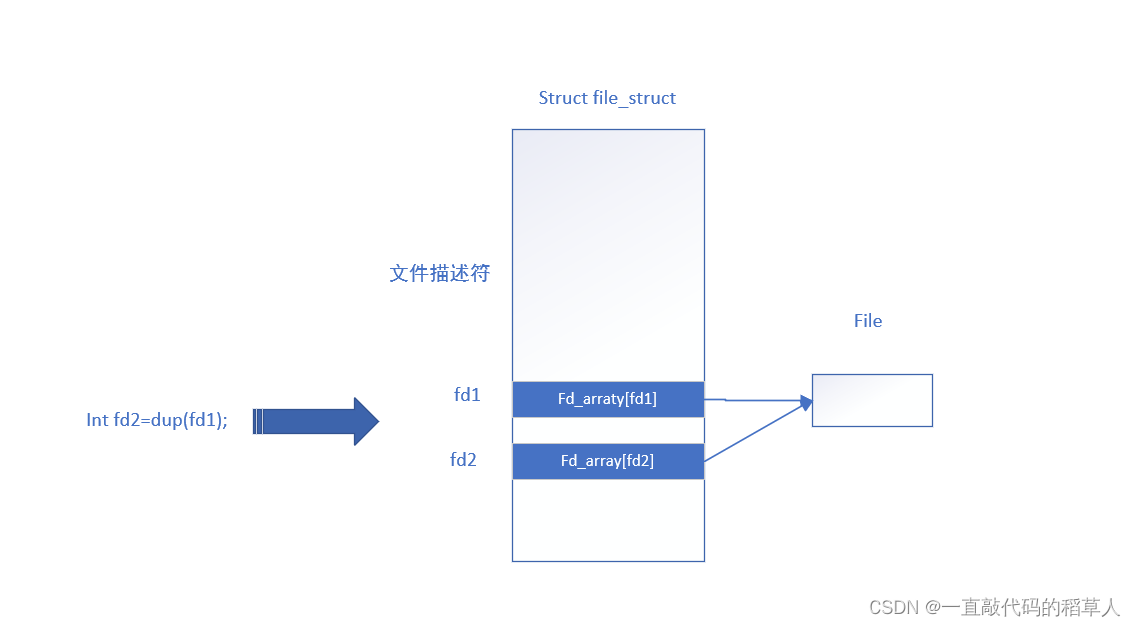
观察以下代码:
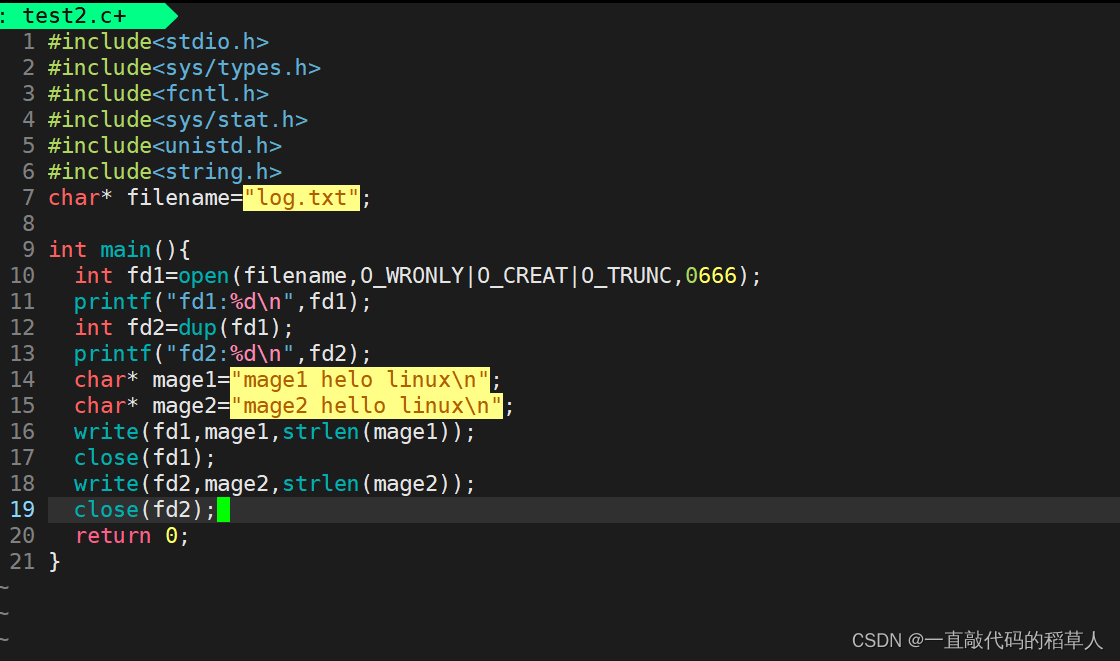

以上代码的大致执行过程:
打开文件
log.txt,得到描述符fd1
拷贝一份fd1文件表项内容,得到fd2,此时fd1和fd2描述同一个的文件
向fd1写入数据mage1之后关闭fd1
向fd2写入数据mage2之后关闭fd2
解释以下疑问:
1.为什么fd1和fd2指向的文件都是log.txt?
这是因为dup函数的原理,上面已经讲过。
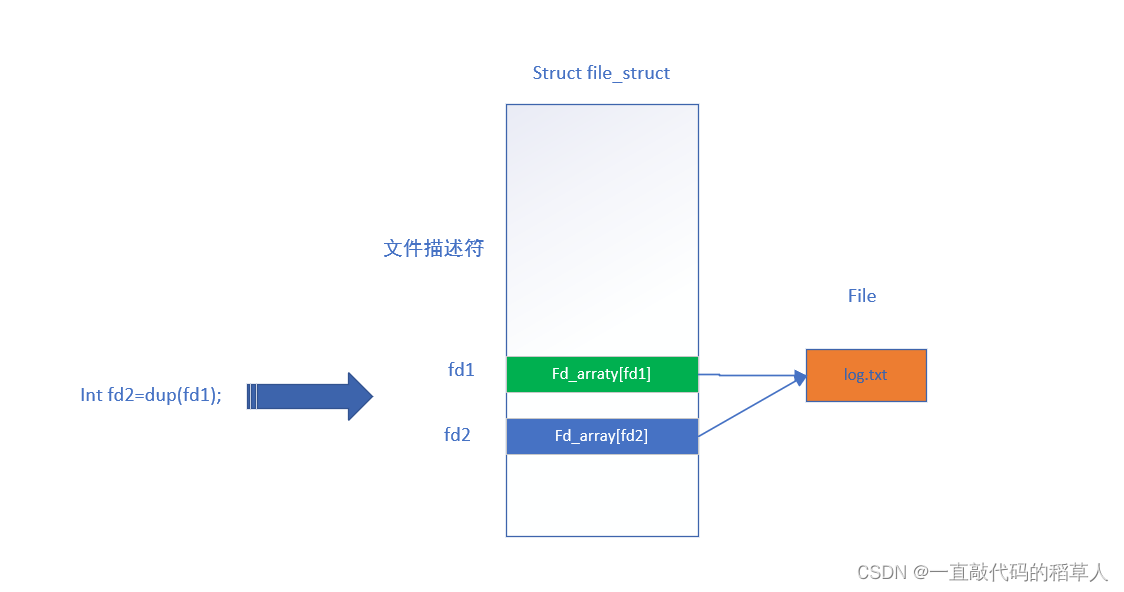
dup拷贝了一份fd_array[fd1]给了fd_array[fd2],所以向fd2写入的数据,也会到log.txt中。
2.为什么close(fd1)之后还能向log.txt写入数据?
既然fd1和fd2指向的文件是同一个,关闭close(fd1)不就等于关闭了文件log.txt吗?
先给出结论: close会不会直接关闭文件,取决于是否还有其它文件描述符指向该文件 。 这里采用了引用计数的原理。每个被打开的文件都会有一个计数器记录该文件被引用的次数。每多一个描述符指向该文件,该文件的引用计数器就会加一。反之,就会减一。一旦引用计数器为0,表示没有可用的描述符指向该文件,该文件也就才能真正地关闭。
所以close(fd)的本质,是清空fd再使文件fd的引用计数器减一。

虽然dup可以复制文件描述符,但是得到的新的描述符是不可控制的。比如不能拷贝一个文件描述符到另一个已存在的文件描述符(dup函数得到的描述符是新的)。这使得dup不够灵活。dup2就可以解决这个问题。下面介绍dup2。
dup2()
#include<unistd.h>
int dup2(int oldfd,int newfd);
dup2函数是Unix/Linux系统中常用的系统调用函数,跟dup类似,用于复制文件描述符,并将其指定为新的文件描述符。但不同的是,dup2函数可以将一个已存在的文件描述符复制到另一个文件描述符上,并允许自定义新文件描述符的编号。这在需要重定向文件描述符或管理多个文件描述符的场景中非常有用。
观察以下代码:

以上代码的大致执行过程:
1.打开文件log.txt并获得其描述符fd
2.关闭stdout文件流,并复制fd到1中。此时fd和1都是指向log.txt。现在就完成了输出重定向,接下来原本向屏幕文件(stdout)输出的变成了向log.txt文件输出。
3.在循环里面用一个字符数组读取键盘数据(stdin,即文件描述符0)。以换行键为一次读取结束,并用printf输出到文件描述符为1指向的文件中,即log.txt。
至此,我们算是已经知道什么叫重定向了,也知道了重定向的本质就是修改文件数组下标指向的内容,即文件描述符指向的内容。
此外,我们也终于理解了什么叫用户级缓冲区及其作用。是不是收获满满呢!
这篇关于【进程OI】重定向的本质用户级缓冲区的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






