本文主要是介绍突破数据障碍—如何使用IP代理服务获取量子科学研究领域最新数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

写在前面
在这个数字化的时代,人们越来越关注隐私保护和网络访问自由。我最近也深入研究了一下IP代理服务,在规避地理限制、绕过封锁以及保护个人隐私方面,它确实发挥了关键作用。
一、基础介绍
起因是有个项目需要对量子领域进行深入的研究之后开展。另外,量子科学正处于飞速发展的阶段,我希望了解该领域的最新进展。
因此,为了更全面地掌握相关知识,需要收集大量包含“quantum”(量子)关键词的学术论文。
然而,手动搜索和整理这些论文将耗费大量时间和精力,这不是我想要的方式。所以,我决定利用爬虫技术来自动化这一繁琐的过程,以便更高效地获取所需信息。
首先。需要先来了解一下IP代理的基本知识:
1.1 是什么?
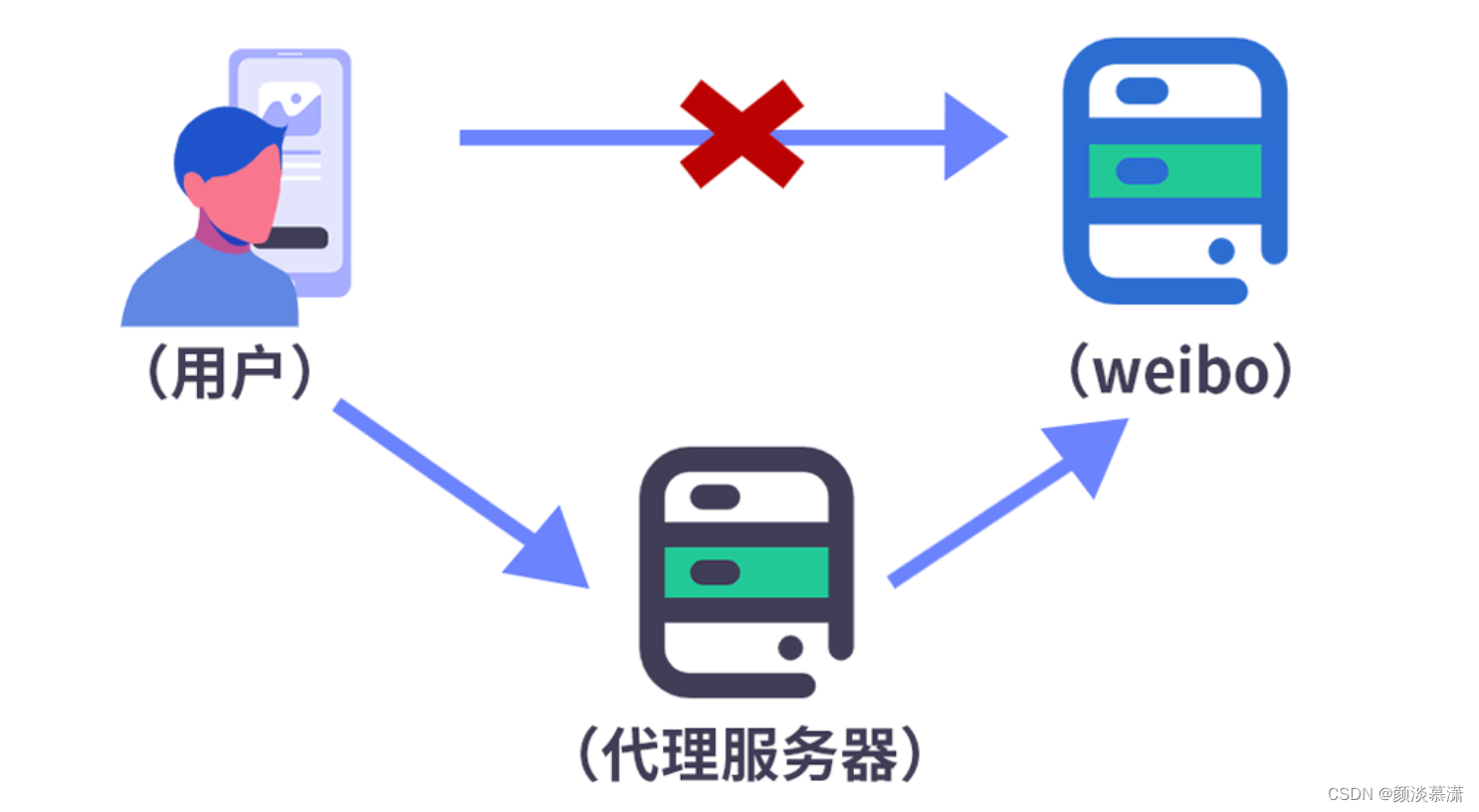
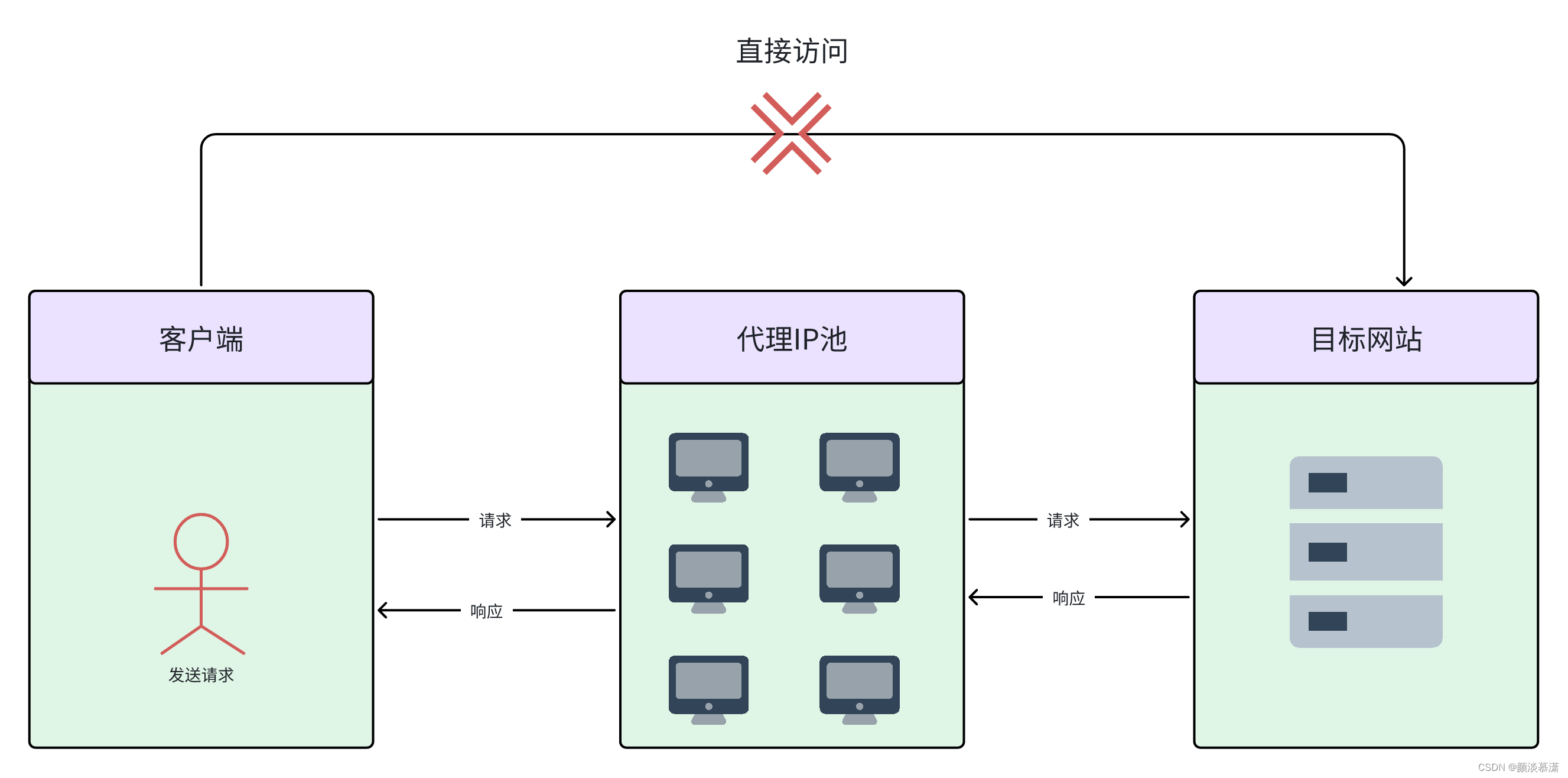
IP代理(Internet Protocol Proxy)是一种通过代理服务器转发网络请求和响应的技术。代理服务器充当客户端和目标服务器之间的中间人,代替客户端发送请求,并将收到的响应转发给客户端。
嗯,我们来简单了解一下它是怎么实现的吧。
- 首先,当你在浏览器里输入网址或者请求访问某个资源时,比如一个网页或者文件,这个请求会被发送到一个代理服务器上。
- 然后,代理服务器会帮你把这个请求转发给目标服务器,但是代理服务器用的是自己的IP地址,所以目标服务器只会知道这个请求是从代理服务器发来的,而不会知道是你的电脑或手机发来的。
- 接着,目标服务器会响应这个请求,把你想要的数据发送给代理服务器。
- 最后,代理服务器再把这个数据传送回给你的电脑或手机。整个过程中,你看到的数据好像是直接从目标服务器发送过来的,但其实是经过代理服务器转发的。就是这么简单!
1.2 项目实现方案
为了实现项目的目标,需要设计一个爬虫来自动化收集包含“quantum”关键词的学术论文。以下是详细的步骤和所需的字段:
1 论文数据库:
首先,我需要选择一个包含大量量子领域学术论文的数据库,如arXiv、ScienceDirect等。
2 确定搜索关键词:
我将使用“quantum”作为关键词进行搜索。
3 设计爬虫:
根据所选数据库的API或网页结构,设计一个爬虫来抓取包含关键词的论文信息。可能需要的字段包括:
- 论文标题
- 作者
- 发表日期
- 摘要
- 关键词
- 论文链接
- …………
这是写的一个示例代码,可以看下,自己手写的话,有点繁琐。我写了一版之后,就决定用其他方式去实现了。
import requests
from bs4 import BeautifulSoup
import csv# 定义搜索关键词
keyword = "quantum"# 定义要爬取的网站列表
websites = ["https://arxiv.org/search/?query=", "https://www.sciencedirect.com/search?qs="]# 定义存储论文信息的CSV文件
csv_file = "papers.csv"# 创建CSV文件并写入表头
with open(csv_file, "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["Title", "Authors", "Publication Date", "Abstract", "Keywords", "Link"])# 遍历网站列表,爬取论文信息
for website in websites:url = website + keywordresponse = requests.get(url)soup = BeautifulSoup(response.text, "html.parser")# 根据网站的HTML结构提取论文信息if "arxiv" in website:papers = soup.find_all("div", class_="arxiv-result")for paper in papers:title = paper.find("p", class_="title is-5 mathjax").text.strip()authors = paper.find("p", class_="authors").text.strip()publication_date = paper.find("p", class_="is-size-7").text.strip()abstract = paper.find("span", class_="abstract-full has-text-grey-dark mathjax").text.strip()keywords = paper.find("p", class_="tags is-size-7").text.strip()link = paper.find("a", title="Abstract")["href"]writer.writerow([title, authors, publication_date, abstract, keywords, link])elif "sciencedirect" in website:papers = soup.find_all("li", class_="ResultItem col-xs-24")for paper in papers:title = paper.find("a", class_="title").text.strip()authors = paper.find("p", class_="Authors").text.strip()publication_date = paper.find("span", class_="publicationDate").text.strip()abstract = paper.find("div", class_="abstract").text.strip()keywords = paper.find("p", class_="Keyword").text.strip()link = paper.find("a", class_="ref nowrap")["href"]writer.writerow([title, authors, publication_date, abstract, keywords, link])4 存储数据:
将爬取到的论文信息存储在一个结构化的数据表中,如CSV文件或数据库。
5 分析数据:
对于收集到的数据,需要好好研究一番量子领域的最新动态和大家关注的热门方向。具体来说:
每年关于量子的文章有多少篇被发表出来,这样就能大概看出这个领域是不是越来越火,发展速度如何。
然后,再看看这些文章里,哪些词儿出现得特别频繁,这些多半就是当前最热门、最多人研究的主题或者方法了。
最后,还得看看哪些论文被引用的次数特别多,这通常意味着这些成果挺有料的,对学术界影响大。
通过这样的分析,就能对量子领域的现状和未来走向有个比较清晰的认识。
6 得出结论:
通过对收集到的数据进行分析,可以得出关于量子领域最新进展和研究趋势的结论。这为项目的研究和发展提供有价值的信息。
以上是整体思路,接下来就去做了
二、实现步骤
在进行技术选型后,我最终决定采用BrightData的IP代理服务。
2.1 为什么选择亮数据
先介绍一下BrightData是什么吧。
BrightData是一家提供全球最大的商业代理网络的公司,其IP代理服务可以帮助企业获取互联网上的数据、保护网络安全以及进行广告验证等多种应用。

它的IP代理服务有很多使用场景,这也是我选择它的原因。
选择 BrightData IP代理服务的原因有几个很重要的点:
首先它是全球IP覆盖。BrightData拥有全球最大的商业代理网络,覆盖了超过 200 个国家和地区,拥有数百万个真实IP地址,为客户提供了广泛的IP选择。
其次是稳定的连接和高速传输。BrightData的代理网络采用专有的智能路由和负载均衡技术,确保用户可以获得稳定可靠的连接,并实现高速数据传输。
还有多种代理协议支持。BrightData支持多种代理协议,包括HTTP、HTTPS、SOCKS5等,满足不同客户的需求,同时还提供了多种连接方式和API接口,方便客户集成和使用。
此外,它还有丰富的数据采集功能。BrightData的代理服务可以帮助客户进行大规模数据采集和挖掘,从而获取互联网上的各种数据,支持市场研究、竞争情报、广告验证等多种应用。
它的网络安全保护也是很值得信赖的。BrightData的代理网络具有强大的安全性和隐私保护功能,可以帮助客户保护网络安全,防范网络攻击和欺诈行为。
最后,个性化定制服务也是它的一大特点。BrightData提供个性化定制的服务,根据客户的需求和业务场景,提供定制化的解决方案,包括定制化的代理节点、数据采集方案和网络安全策略等。
下面这部分主要讲解一下我选择的服务以及具体怎么做的。
2.2 注册&登录
进入官网首页,进行登录注册:亮数据
注册时需要填写的信息如下:姓名、邮箱、手机号即可注册完成

登录成功会进入后台的首页
首页有两个模块,是代理爬虫基础设施和web数据集
可以看待代理和爬虫的基础设施有很多类型。
2.3 IP代理服务
它的IP代理服务类型有很多,来简单了解一下:
- 首先是动态住宅代理,这种代理是从互联网服务提供商获取的住宅IP,用于商业目的。它具有高度匿名性和真实性,适合需要隐私和安全性的场景。
- 其次是静态住宅代理,这种代理是从ISP购买或租赁的住宅IP,它是固定不变的,适合长期使用。它相对经济实惠,但可能容易被某些网站识别和屏蔽。
- 接下来是机房代理,这种代理是将大量IP分配到一台服务器,通过该服务器路由流量。它具有快速稳定、无限带宽等优点,适合需要长期固定IP地址的用户。
- 最后是移动代理,这种代理通过连接到4G蜂窝网络的真实移动设备传输流量,使用真实设备的移动IP。它难以被发现,适合需要高度隐秘性的应用场景。
登录之后,在后台页面可以根据不同的需求选择对应的代理服务。
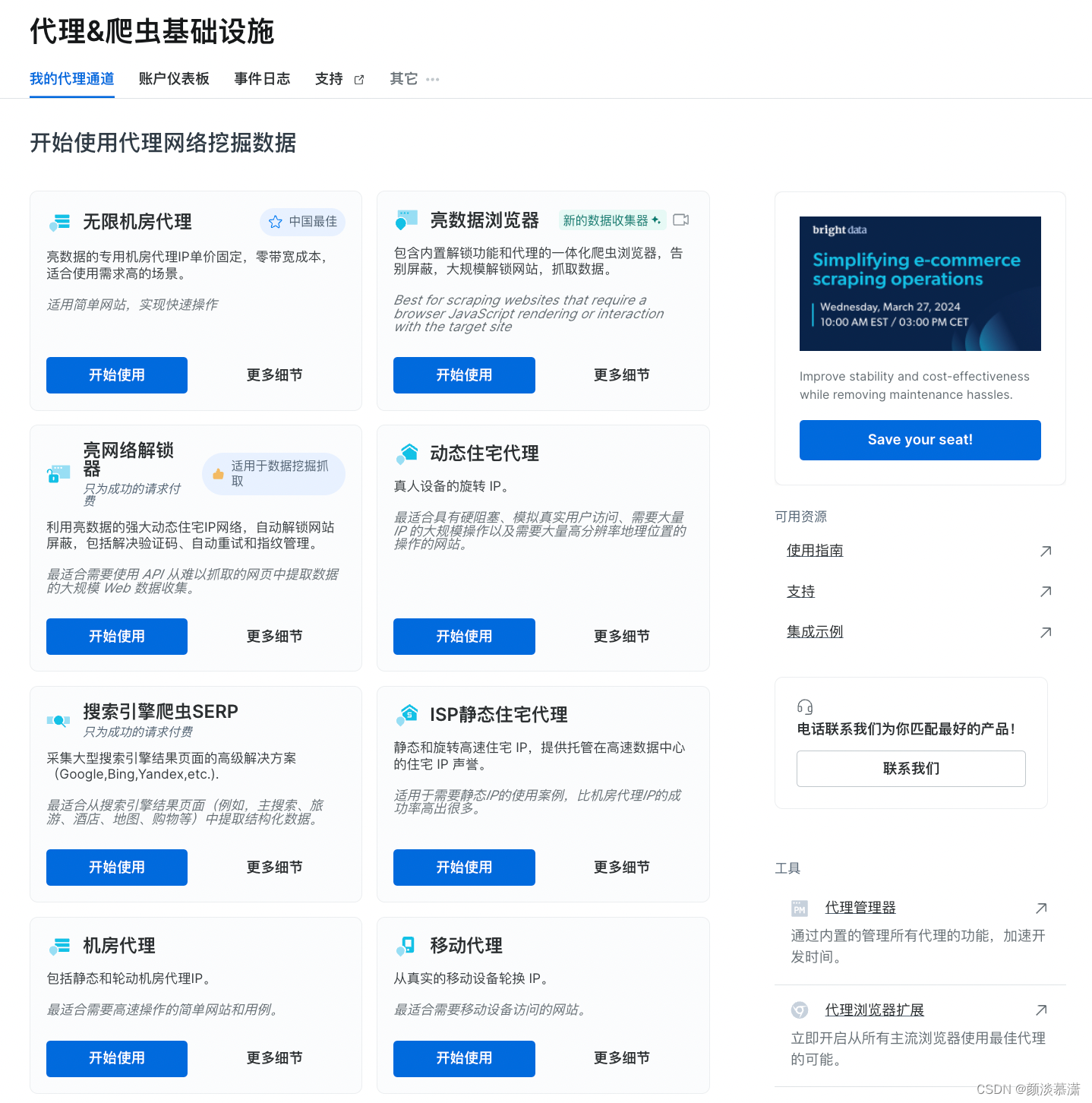
我选择的是无线机房代理,点击无限机房代理->开始使用

这两种IP类型都可以选择,我选择了共享,可以看到数量是1个,费用是$0.5
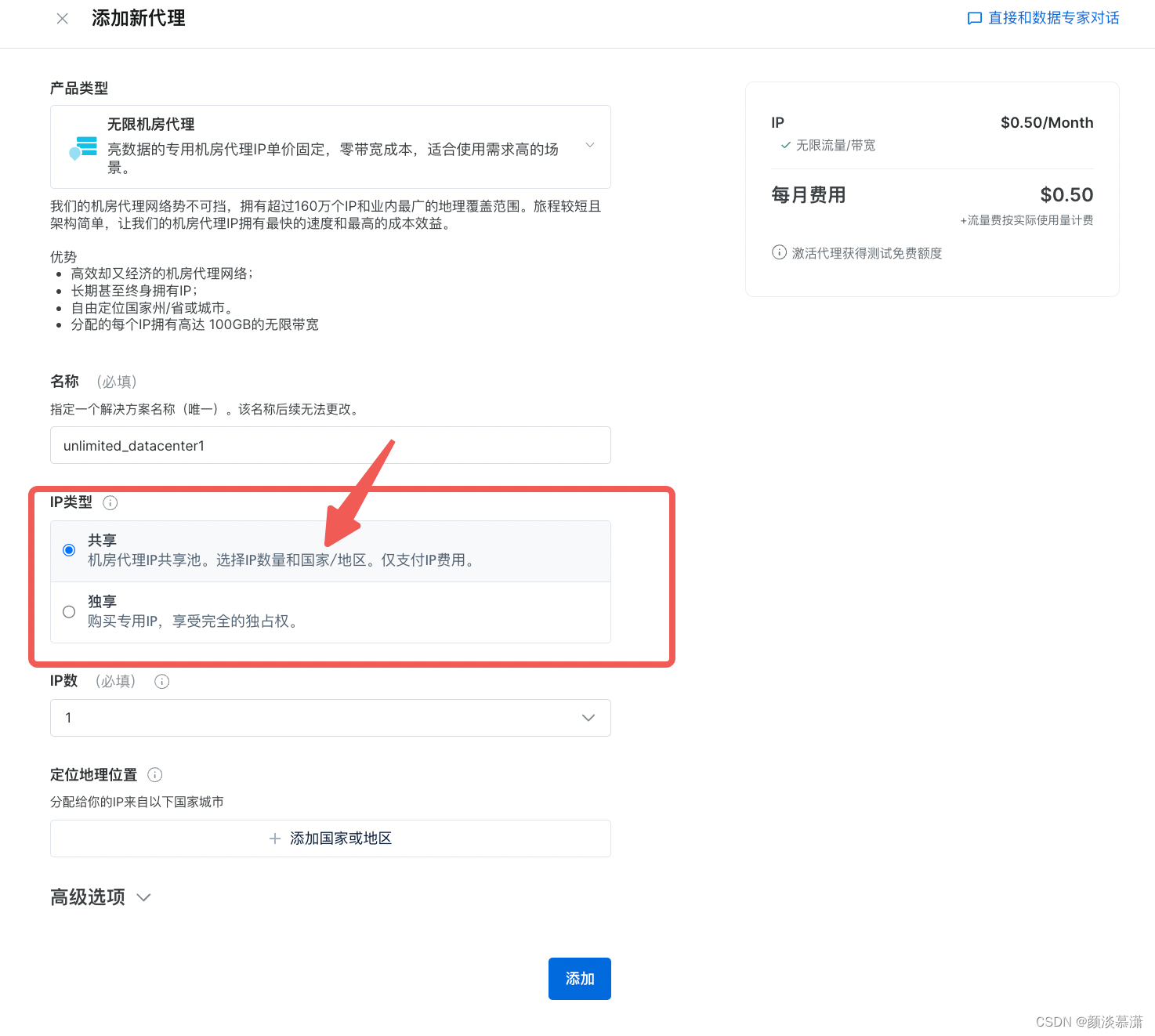
点击添加后,他会再提醒你一下,点击确定之后,付款就可以使用了!

2.4 数据集
另外,在数据集方面,它不仅支持自定义采集,还有数据集商城,是按照行业分类的,如果需要公共的数据,可以直接购买,就省去了采集的步骤。
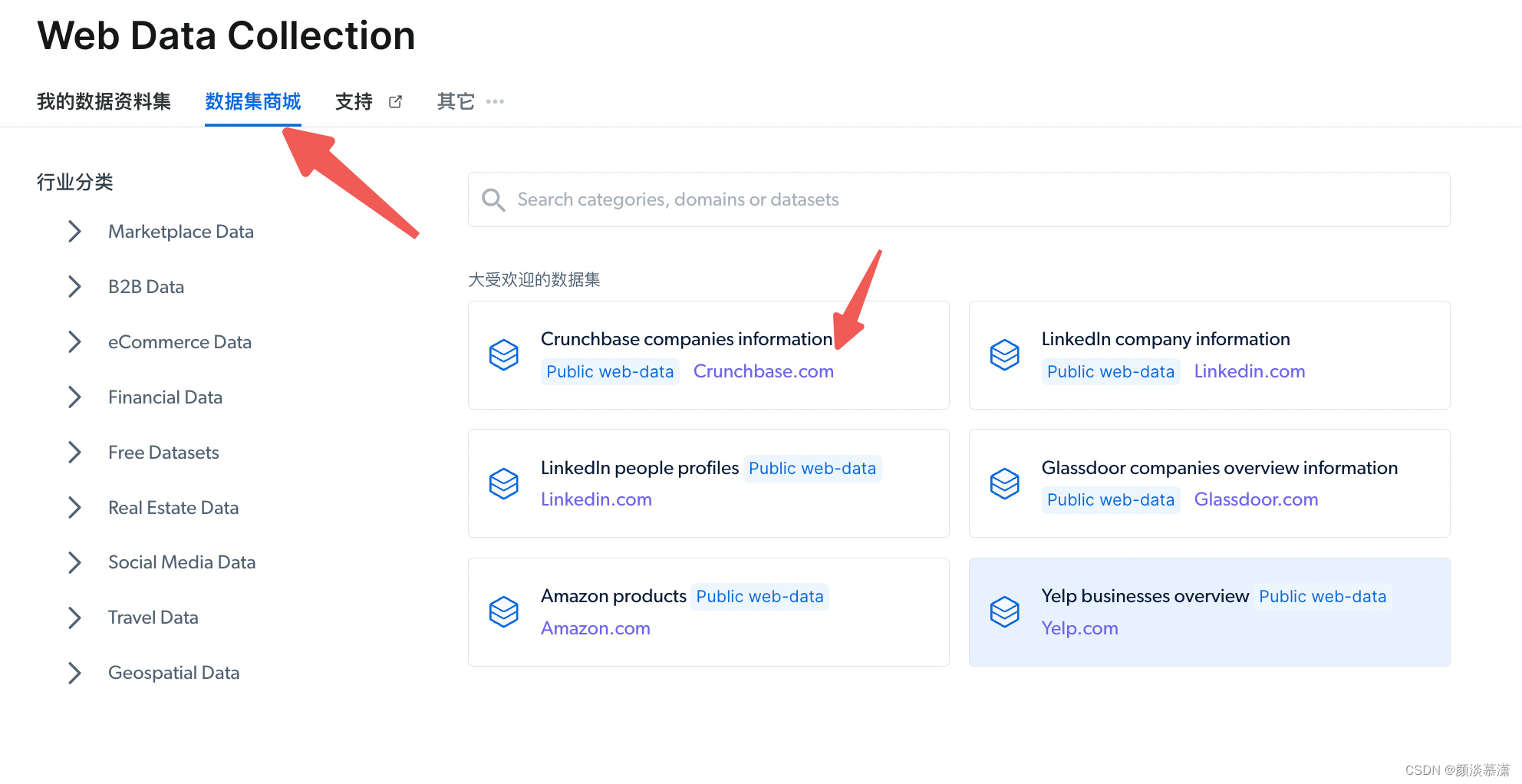
点击 Explore data products 之后,进入下面界面。
定制数据集的步骤:填写请求表单—>提交请求—>等待审核与响应—>获取定制数据集
操作之后会看到如下

它支持两种下载类型,JSON和CSV,

下载一下看到两种格式的数据,确实都是按照我的要求输出的。
JSON如下:

这是CSV样式

亮数据IP代理服务,用起来可真够灵活的,啥场合都能派上用场。无论是你想搞点市场分析,还是要查个广告真假,亦或是得盯紧点儿价格变动,甚至打理网站、捣鼓移动应用,都没问题。
特别是那个“Request a Custom Dataset”功能,简直就是神器,想怎么定制数据就怎么定制,想要啥数据源就有啥数据源。对那些挑剔的主儿来说,这个功能贴心到家了。
还有呢,除了能让客户自己通过IP代理服务去网上扒数据,亮数据还提供了一堆浏览器和解锁工具,让这活儿更轻松。要是客户手上没那技术活儿,也简单,直接买数据集服务得了。
三、总结
现在这信息满天飞的时代,IP代理服务可真是成了保护咱个人隐私、想上哪儿网就上哪儿网的神器了。只要连上了代理服务器,你的真正IP地址就藏起来了,什么地区的限制啊、封锁啊、审查啊,通通不是事儿,让你匿名上网,自由冲浪,就跟有了一张网络世界里的隐形斗篷似的。
亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
折扣代码:yandan
访问页面:访问页面
如有问题,可以关注“Bright_Data”亮数据官微,联系后台客服。
这篇关于突破数据障碍—如何使用IP代理服务获取量子科学研究领域最新数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







