本文主要是介绍【数据结构】链表之无头单向非循环链表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
链表的特点是:物理地址不连续
数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表
链表的结构:链表由数据域和指针域两部分组成,数据域是存储数据元素的部分,指针域一般指向下一个节点的指针。

链表的优点
在进行插入和删除操作时比较方便
链表的缺点
- 存储密度小,空间利用率低
- 要访问某特定元素,只能从链表开头进行遍历
头结点的作用
为了保持和后面结点的设计算法一致,保持算法的高效性
链表共有8种结构,分别为
- 单链表
- 双向链表
- 带头单链表
- 不带头单链表
- 非循环单链表
- 循环单链表
- 无头单向非循环链表
- 带头双向循环链表
然而在实际中最常用的就是最后两种:无头单向非循环链表、带头双向循环链表
具体结构如下:
1、无头单向非循环链表
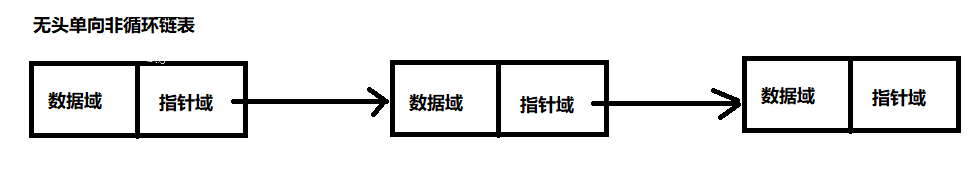
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。
2、带头双向循环链表

带头双向循环链表:结构复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。
无头单向非循环链表的模拟实现
无头单向非循环链表的接口
// 1、无头单向非循环链表增删查改实现
typedef int SLTDataType;
typedef struct SListNode
{SLTDataType _data;struct SListNode* _next;
}SListNode;
typedef struct SList
{SListNode* _head;
}SList;void SListInit(SList* plist);//初始化链表
void SListPushFront(SList* plist, SLTDataType x);
void SListPopFront(SList* plist);
SListNode* SListFind(SList* plist, SLTDataType x);
void SListInsertAfter(SListNode* pos, SLTDataType x);
void SListEraseAfter(SListNode* pos);
void SListDestory(SList* plist);
void SListPrint(SList* plist);具体实现
#include"slist.h"//初始化链表
void SListInit(SList* plist)
{plist->_head = NULL;
}//头插法
void SListPushFront(SList* plist, SLTDataType x)
{assert(plist);SListNode * cur = (SListNode *)malloc(sizeof(SListNode));//将要插入结点的值赋给cur,此时cur指向原来链表的头结点//新的链表的头结点即为curcur->_data = x;cur->_next = plist->_head;plist->_head = cur;
}//头删法
void SListPopFront(SList* plist)
{assert(plist);//判断要删除的结点是否为头结点,若是则需要一个临时结点保存头结点SListNode * tmp;if (plist->_head){tmp = plist->_head;plist->_head = tmp->_next;//将原链表头结点的下一个结点设置为头结点free(tmp);}
}//查找一个链表中的元素pos
SListNode* SListFind(SList* plist, SLTDataType x)
{assert(plist);SListNode * cur;for (cur = plist->_head; cur; cur = cur->_next)//单链表的遍历{if (cur->_data == x){return cur;}}return NULL;
}// 在pos的后面进行插入
void SListInsertAfter(SListNode* pos, SLTDataType x)
{SListNode * cur = (SListNode *)malloc(sizeof(SListNode));cur->_data = x;//创建要插入元素的值//待插入元素的指向下一个元素就是pos指向的下一个元素//将待插入的元素与下一个元素建立关系cur->_next = pos->_next;//断开pos与原来下一个元素的关系,建立pos与待插入元素的关系pos->_next = cur;
}//删除pos后的一个元素
void SListEraseAfter(SListNode* pos)
{SListNode * tmp = pos->_next;//建立一个临时结点来保存pos->next,由于链表的物理地址不是连续的,不保存将会无法找到pos指向的下一个元素pos->_next = tmp;//此时将pos与pos后的第二个元素(即tmp指向的元素)建立关系pos->_next = tmp->_next;//释放掉tmp,即删除pos后的元素free(tmp);
}void SListDestory(SList* plist)
{assert(plist);SListNode *tmp;while (plist->_head){tmp = plist->_head;plist->_head = plist->_head->_next;free(tmp);}
}void SListPrint(SList* plist)
{assert(plist);SListNode *cur;for (cur = plist->_head; cur; cur = cur->_next){cout << cur->_data << "->" << " ";}cout << "NULL" << endl;
}
测试
#include"slist.h"void ListTest()
{SList test;SListInit(&test);SListPushFront(&test, 1);SListPushFront(&test, 3);SListPushFront(&test, 5);SListPushFront(&test, 7);SListPushFront(&test, 9);SListPrint(&test);SListPopFront(&test);SListPrint(&test);SListInsertAfter(SListFind(&test, 3), 8);SListPrint(&test);SListEraseAfter(SListFind(&test, 8));SListPrint(&test);SListDestory(&test);
}int main()
{ListTest();system("pause");return 0;
}运行结果
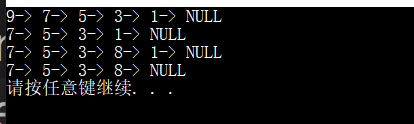
注意事项
单链表遍历的方法
for(cur = head; cur; cur = cur->next) //中间的cur是判空
{cur;
}
这篇关于【数据结构】链表之无头单向非循环链表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




