本文主要是介绍一起重新开始学大数据-MySQL篇-Day34-日期函数、计算、排序分组筛选、连表联查等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 一起重新开始学大数据-MySQL篇(2) |

| 日期函数 |

获取当前日期:
current_timestamp;–所有
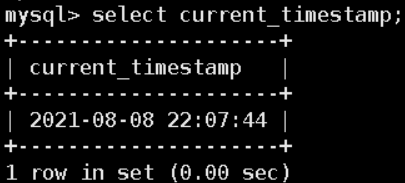
current_timestamp();–所有
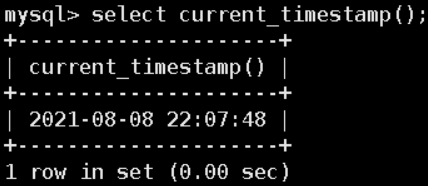
CURRENT_DATE();-- 年月日
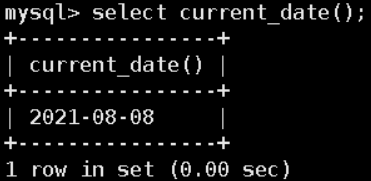
CURRENT_DATE;-- 年月日
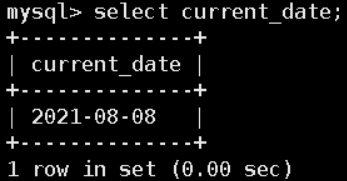
CURRENT_TIME();-- 时分秒
CURRENT_TIME;-- 时分秒

时间转str
格式:
date_format(date,format)
date:时间
format:格式
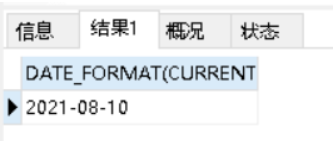
SELECT DATE_FORMAT(CURRENT_DATE(),'%Y-%m-%d');
str转日期
格式:
str_to_date(str,formaat)
例:
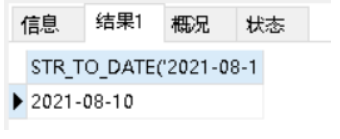
SELECT STR_TO_DATE('2021-08-10','%Y-%m-%d')
日期相减
格式:
datediff(expr1,expr2);
注意:
只能相减年月日,时分秒参与运算结果为null
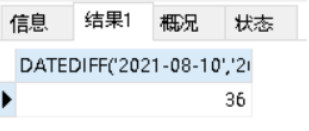
SELECT DATEDIFF('2021-08-10','2021-07-5');
函数向日期添加指定的时间间隔
格式:
DATE_ADD(date,INTERVAL expr unit);
date:时间
INTERVAL:关键字
expr:间隔的数值
unit:年月日时分秒(…,…,day,…,…,…)
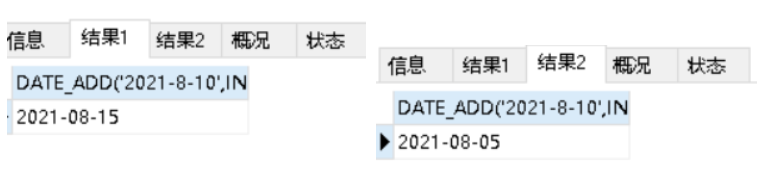
SELECT DATE_ADD('2021-8-10',INTERVAL 5 DAY);
SELECT DATE_ADD('2021-8-10',INTERVAL -5 DAY);
| 计算 |

round(x,d):四舍五入
x:值
d:保留几位小数点
SELECT ROUND(1.0);
SELECT ROUND(1.4);
SELECT ROUND(1.5);

ceil(x):向上取整
SELECT CEIL(1.0);
SELECT CEIL(1.4);
SELECT CEIL(1.5);

floor(x):向下取整
SELECT FLOOR(1.0);
SELECT FLOOR(1.4);
SELECT FLOOR(1.5);

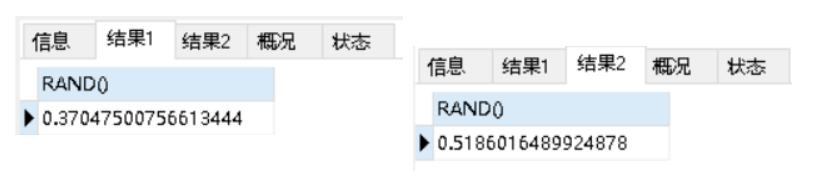
rand():随机数(0-1之间)
SELECT RAND();
SELECT RAND();
| 排序、分组、筛选 |

排序
格式:
order by 字段1 asc|desc,字段2 asc|desc...字段n asc|desc;
例如:按照age进行降序排列,age相同按照id进行降序排列
select * from students order by age desc,id desc;
注意:
默认升序asc,降序desc
如果有多个字段,按照先后顺序依次排序

group by 分组
格式:
group by 字段1,字段2...字段n;
注意:
多个字段,按照所有字段进行分组(一起分组)
有多少组显示多少条数据(默认情况下,没有经过条件筛选)
每组显示的数据为每组中默认第一条数据
gruop by 通常和聚合函数一起使用
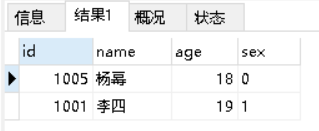
SELECT * from students GROUP BY sex;
筛选:where having
区别:having可以使用聚合函数
例如:
select * from students where age>=25;--可以
select * from students having age>=25;--可以
select sex,count(*) c from students group by sex where c>4;--不可以
select sex,count(*) c from students group by sex having c>4;--可以
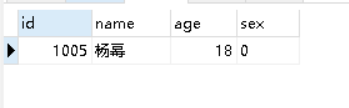
SELECT * from student GROUP BY sex HAVING sex='0';
TopN:前几条数据
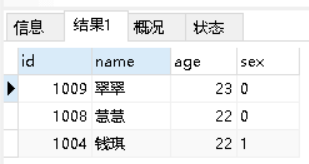
1.TopN age最大的前三个
select * from students order by age desc limit 0,3;
2.分组Top1 按sex分组后,求分组中年龄最大的一个
select * from students where age in (select max(age) m from students group by sex);
select * from students as stu1 where age=(select max(age) from students as stu2 where stu1.sex=stu2.sex);
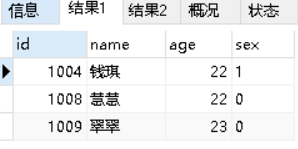
3.分组TopN 按sex分组后,求分组中年龄最大的三个
select * from students as stu1 where 3>(select count(*) FROM students as stu2 where stu1.sex=stu2.sex and stu1.age<stu2.age);
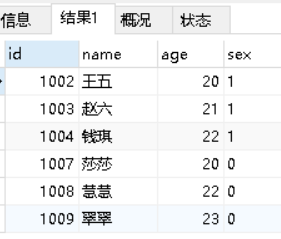
| 连表联查 |

union:结果集进行合并(纵向合并)
格式:
查询语句 union 查询语句
注意:
查询列数必须相同
字段为第一个sql语句的字段
union默认去重
union all不去重<./font>
例子
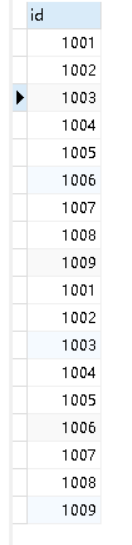
SELECT id from students UNION SELECT id from students;
SELECT id from students UNION ALL SELECT id from students;

left join(以左表为基准关联右表中的数据)
格式:
select * from 左表 left join 右表 on 关联条件;
注意:
左表匹配不到右表,以null不全
右表匹配不到左表,不显示
SELECT * FROM id LEFT JOIN students ON id.id=students.id;

right join(以右表为基准关联左表中的数据)
格式:
select * from 右表 left join 左表 on 关联条件;
注意:
左表匹配不到右表,不显示
右表匹配不到左表,以null不全
SELECT * FROM id right JOIN students ON id.id=students.id;

inner join(求两张表的交集)
格式:
select * from 右表 inner join 左表 on 关联条件;
注意:
关联条件可写可不写
如果不写可以写为select * from 表1,表2 where 子句;
SELECT * FROM id INNER JOIN students ON id.id=students.id;

mysql三大范式
1.原子性:字段不可在分割
2.唯一性:字段依赖于主键
3.冗余性:数据量过大
|
|
|
|
上一章-MySQL篇-Day33-SQL、建库建表、增删查改、聚合函数等
下一章-MySQL篇-Day35-练习题
|
|
|
|
| 听说长按大拇指👍会发生神奇的事情呢!好像是下面的画面,听说点过的人🧑一个月内就找到了对象的💑💑💑,并且还中了大奖💴$$$,考试直接拿满分💯,颜值突然就提升了😎,虽然对你好像也不需要,是吧,吴彦祖🤵! |



这篇关于一起重新开始学大数据-MySQL篇-Day34-日期函数、计算、排序分组筛选、连表联查等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







