本文主要是介绍浅显易懂的简单说一下jvm内存模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说起JVM大家都知道,它是运行java代码的基础。那么关于JVM 内存模型是不是很模糊 我用通俗易懂的方式说一下
我们这里先介绍 JVM 堆内存 它有两大块 包括 新生代内存,和老年代内存 。
为啥分为这两块, 你可以这样理解,(我这里先假设你懂GC回收方面的基础知识)。GC回收对象,有的对象被经常用到,有的呢没有被经常用到,这些经常用的对象 要是反复被创建是不是非常麻烦,举个生活中的例子,你整理一间屋子 是不是经常用到的东西会放到显眼,而且好拿的位置。不经常用的 都放床底下啦对不对。道理一样
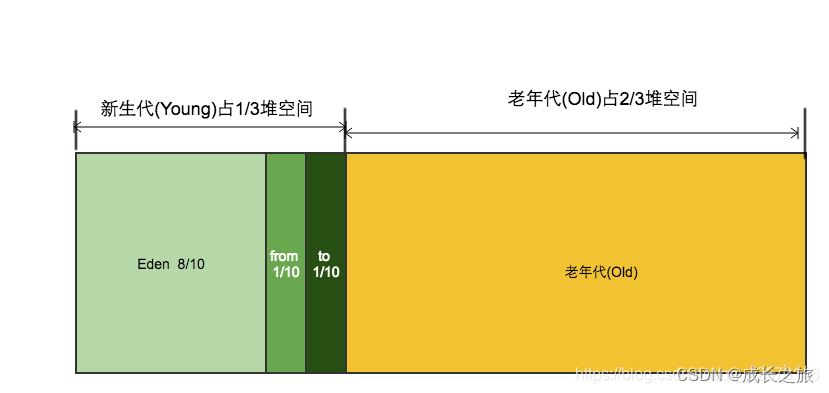
那么 经常用到的对象 会放到老年代内存中,新被创建的对象 会放到新生代内存中。
新生代内存包括啥。 如上图所示,新生代 包括 Eden、From Survivor、To Survivor
Eden这个单词啥意思 伊甸园的意思,代表新生的意思,也就是 你刚new 出来一个对象 就会进入的到这里,GC是垃圾回收,每隔一段时间会自动回收对象。
然后在看一下Survival 区 (包含From 和TO )这个区字面意思是幸存者区,也就是GC 清除Eden区 能幸存留下来的 都会移动到这里。
这里有一个问题,GC 依据什么 来确定这个对象到底清楚还是迁移到Survival区 GC 会通过GCRoot 来找这个对象 有没有被引用 ,如果 没有被引用旧清除掉
这里注意下,有一个问题,就是循环引用,你想啊 有两对象 相互引用对方 ,这两对象永远没有被使用了,但是还相互指向对方, 那是不是 永远不会被清除掉,这就是GC Root解决的问题, 可达性分析算法 ,原理就是一路追踪到最后, 看看到底最终的哪一个对象,有没有被人使用,最终没有被使用 那么整个一条链路 就没有存在的意义。
咱们话说回来,Minor GC 在运行是扫描Eden区 他看到对象 A 这次有引用了 就迁移到Survivor区,然后计数一次,每次扫描加1 等到计数达到15次之后 GC 认为他是一个 经常被使用的对象,那么 直接晋级到老年代区(先简单了解大体过程 一会在详细说 ,这涉及到GC算法问题)
在晋级到老年代区的时候,涉及到一个概念叫空间分配担保 ,在讲这个概念前 我需要给你讲一个生活场景便于理解。
对象晋级老年代的时候 发现老年代空间满了,放不下了咋办,为了避免这种情况,在执行Minor GC 时候 先看一下老年代空间还剩多少,够不够放新生代所有对象的空间(就是我先往大了预估我假设你们全部晋级老年代),如果够那没问题了 ,但是如果不够的话咋办,HandlePromotionFailure 检查一下这个开关如果是true 它会这样做,看看往次Minor GC 大部分都晋级多少对象 算一个平均数 预估一下,如果算出来的平均数能满足 晋级到老年到 那么来吧 。但是也有风险 这里只是 预估一下万一 预估不准确,那就歇菜了,但是预估的数据不满足 那么老老实实还是先把老年代 数据 清除一下腾腾地方 (FUll FC)
再说一下 GC 算法
你想这样一个场景,好声音开始的时候 是海选,在茫茫人海的参赛选手中选择基本上,唱功还可以的 人参加节目。这意味着是不是要淘汰掉很多人,简单理解是大量的人中选出一小部分 ,而 到了最后的上电视节目参赛环节,就是再一小部分人中,那么逐步再淘汰一部分人。
先看 海选环节应该是找出唱功还可以的参加节目,然后剩下的人淘汰掉,你不能反过来说 我找不优秀的, 剩下的都是优秀的吧,那不有毛病吗。我们的新生代Eden区就类似于 海选阶段,这里用到的算法是 复制算法,把优秀的人标记一下然后,复制到 一个区域(就类似于好声音海选出来的选手参加节目)然后把剩下的 全部清除掉。
说一下具体过程:具体是这样 ,在执行Minor GC 时候 先把Eden区和Survivor 中的From 区满足 要求的 挑选出来,挑选出来之后 放到Survivor TO 区 然后把剩下淘汰掉 就是吧Eden 和From 区 统一清除掉,然后呢 在把TO 区放回到From区,这里注意下假如TO区满了 直接 放到老年代里边去,也就是TO区只是一个腾挪的地方
好声音最后 上节目进行淘汰赛 ,把唱的不好的人一个个淘汰掉 ,这就类似于我们的老年代, 里边都是一个长久存活对象 要找出来 没有被引用的,这就用到标记清除算法,就是先标记,找出没有引用的对象,然后再清除掉就可以了(这里记住是两步 先标记再清除)。
其实关于标记清除算法 真正在的收集中是有优化的,叫标记清除整理算法,因为 你标记清除之后 内存空间会不连续,他在清除之后会整理一下,统一移动到一端,然后 留出空闲的连续空间,这样 可以 保证一些连续的空间可以使用(例如数字)。
再说一下三色标记:
先说一下为什么要三色标记,以下摘抄自阿里-通义灵码
JVM 中的三色标记算法主要用于实现并发的垃圾收集(Garbage Collection, GC),特别是用于解决在垃圾回收过程中如何安全地并发进行对象标记的问题。传统的标记清除算法在进行标记阶段时通常需要暂停所有的用户线程(Stop-The-World),以确保在此期间不会发生对象引用关系的变化,从而准确地标记出哪些对象是“存活”的,哪些是“垃圾”。
三色标记算法通过引入三种颜色来区分对象的不同状态,从而允许标记过程与用户程序并发执行:
白色:表示对象尚未被垃圾收集器访问过,可能是垃圾。
灰色:表示对象已被垃圾收集器发现,但其引用的对象还没有被访问和标记。
黑色:表示对象已经被垃圾收集器访问过,不仅自身是可达的(即非垃圾),而且其引用的所有对象也都已经被标记过(或递归标记过)。
GC 在并发标记(虽然JDK 没有完全舍弃STOP THE WORLD)的过程中,为了 防止 和用户线程产生标记冲突 比如 本来应该清除的对象 标记为存活, 本来应该存活的对象 标记为清除
第一种好办,大不了下次在清除,但是第二种就危险了。举个例子 A对象引用B对象B引用C对象
A>B>C. 现在用户线程突然改动了A>C, B到C的引用关系删除,而GC 正好执行到B 发现B没有指向了 所以 这个时候 就认为 C要删除 。(其实就是GC不会返回去再查一下)。这就是三色标记中的误标问题。
这篇关于浅显易懂的简单说一下jvm内存模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





