本文主要是介绍Python struct模块的pack、unpack示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
import struct
pack、unpack、pack_into、unpack_from
import struct #pack - unpack
print
print '===== pack - unpack =====' str = struct.pack("ii", 20, 400)
print 'str:', str
print 'len(str):', len(str) # len(str): 8 a1, a2 = struct.unpack("ii", str)
print "a1:", a1 # a1: 20
print "a2:", a2 # a2: 400 print 'struct.calcsize:', struct.calcsize("ii") # struct.calcsize: 8 #unpack
print
print '===== unpack =====' string = 'test astring'
format = '5s 4x 3s'
print struct.unpack(format, string) # ('test ', 'ing') string = 'he is not very happy'
format = '2s 1x 2s 5x 4s 1x 5s'
print struct.unpack(format, string) # ('he', 'is', 'very', 'happy') #pack
print
print '===== pack =====' a = 20
b = 400 str = struct.pack("ii", a, b)
print 'length:', len(str) #length: 8
print str
print repr(str) # '/x14/x00/x00/x00/x90/x01/x00/x00' #pack_into - unpack_from
print
print '===== pack_into - unpack_from ====='
from ctypes import create_string_buffer buf = create_string_buffer(12)
print repr(buf.raw) struct.pack_into("iii", buf, 0, 1, 2, -1)
print repr(buf.raw) print struct.unpack_from("iii", buf, 0)结果:
===== pack - unpack =====
str: ?
len(str): 8
a1: 20
a2: 400
struct.calcsize: 8===== unpack =====
('test ', 'ing')
('he', 'is', 'very', 'happy')===== pack =====
length: 8
?
'/x14/x00/x00/x00/x90/x01/x00/x00'===== pack_into - unpack_from =====
'/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00'
'/x01/x00/x00/x00/x02/x00/x00/x00/xff/xff/xff/xff'
(1, 2, -1)Python是一门非常简洁的语言,对于数据类型的表示,不像其他语言预定义了许多类型(如:在C#中,光整型就定义了8种)
它只定义了六种基本类型:字符串,整数,浮点数,元组(set),列表(array),字典(key/value)
通过这六种数据类型,我们可以完成大部分工作。但当Python需要通过网络与其他的平台进行交互的时候,必须考虑到将这些数据类型与其他平台或语言之间的类型进行互相转换问题。打个比方:C++写的客户端发送一个int型(4字节)变量的数据到Python写的服务器,Python接收到表示这个整数的4个字节数据,怎么解析成Python认识的整数呢? Python的标准模块struct就用来解决这个问题。
struct模块的内容不多,也不是太难,下面对其中最常用的方法进行介绍:
常用方法
1、 struct.pack
struct.pack用于将Python的值根据格式符,转换为字符串(因为Python中没有字节(Byte)类型,可以把这里的字符串理解为字节流,或字节数组)。其函数原型为:struct.pack(fmt, v1, v2, …),参数fmt是格式字符串,关于格式字符串的相关信息在下面有所介绍。v1, v2, …表示要转换的python值。下面的例子将两个整数转换为字符串(字节流):
struct 类型:
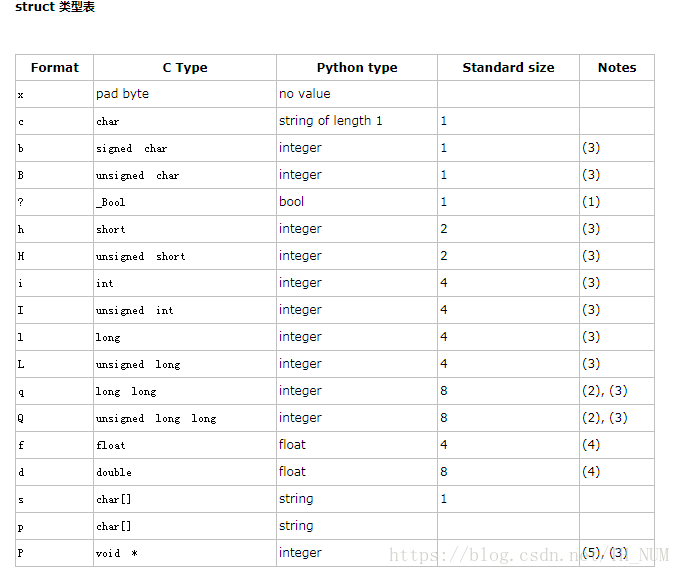
#!/usr/bin/env python
#encoding: utf8 import sys
reload(sys)
sys.setdefaultencoding("utf-8") import struct a = 20
b = 400
str = struct.pack("ii", a, b)
print 'length: ', len(str) # length: 8
print str # 乱码:
print repr(str) # '\x14\x00\x00\x00\x90\x01\x00\x00'格式符”i”表示转换为int,’ii’表示有两个int变量。
进行转换后的结果长度为8个字节(int类型占用4个字节,两个int为8个字节)
可以看到输出的结果是乱码,因为结果是二进制数据,所以显示为乱码。
可以使用python的内置函数repr来获取可识别的字符串,其中十六进制的0x00000014, 0x00001009分别表示20和400。
2、 struct.unpack
struct.unpack做的工作刚好与struct.pack相反,用于将字节流转换成python数据类型。它的函数原型为:struct.unpack(fmt, string),该函数返回一个元组。
下面是一个简单的例子:
#!/usr/bin/env python
#encoding: utf8 import sys
reload(sys)
sys.setdefaultencoding("utf-8") import struct a = 20
b = 400 # pack
str = struct.pack("ii", a, b)
print 'length: ', len(str) # length: 8
print str # 乱码:
print repr(str) # '\x14\x00\x00\x00\x90\x01\x00\x00' # unpack
str2 = struct.unpack("ii", str)
print 'length: ', len(str2) # length: 2
print str2 # (20, 400)
print repr(str2) # (20, 400)3、 struct.calcsize
struct.calcsize用于计算格式字符串所对应的结果的长度,如:struct.calcsize(‘ii’),返回8。因为两个int类型所占用的长度是8个字节。
import struct
print "len: ", struct.calcsize('i') # len: 4
print "len: ", struct.calcsize('ii') # len: 8
print "len: ", struct.calcsize('f') # len: 4
print "len: ", struct.calcsize('ff') # len: 8
print "len: ", struct.calcsize('s') # len: 1
print "len: ", struct.calcsize('ss') # len: 2
print "len: ", struct.calcsize('d') # len: 8
print "len: ", struct.calcsize('dd') # len: 164、 struct.pack_into、 struct.unpack_from
这两个函数在Python手册中有所介绍,但没有给出如何使用的例子。其实它们在实际应用中用的并不多。Google了很久,才找到一个例子,贴出来共享一下:
#!/usr/bin/env python
#encoding: utf8 import sys
reload(sys)
sys.setdefaultencoding("utf-8") import struct
from ctypes import create_string_buffer buf = create_string_buffer(12)
print repr(buf.raw) # '\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' struct.pack_into("iii", buf, 0, 1, 2, -1)
print repr(buf.raw) # '\x01\x00\x00\x00\x02\x00\x00\x00\xff\xff\xff\xff' print struct.unpack_from("iii", buf, 0) # (1, 2, -1)这篇关于Python struct模块的pack、unpack示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






