本文主要是介绍旋转目标检测AAAI2020之DAL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 介绍
- 摘要
- 讨论
- 方法
- 3.1 Analysis
- 3.2 Dynamic Anchor Selection
- 3.3 Matching-Sensitive Loss
- 实验
介绍
@article{ming2020dynamic,
title={Dynamic Anchor Learning for Arbitrary-Oriented Object Detection},
author={Ming, Qi and Zhou, Zhiqiang and Miao, Lingjuan and Zhang, Hongwei and Li, Linhao},
journal={arXiv preprint arXiv:2012.04150},
year={2020}
}
论文地址:https://arxiv.org/abs/2012.04150
项目地址:https://github.com/ming71/DAL
摘要
任意方向目标检测任务在航空图片、遥感图片、自然场景图片中广泛出现。因此,在近年来,该领域也受到了广泛的关注。如今很多的旋转检测模型使用大量不同方向的目标框去对齐真实目标。而IoU一直以来也是挑选正例和负例样本的重要方法。然鹅,经作者发现使用IoU去挑选正例和负例样本会导致如下两个问题:
- 进一步加剧的正负样本不平衡。对于旋转目标检测而言,预设旋转anchor要额外引入角度先验,使得预设的anchor数目成倍增加。此外,旋转anchor角度稍微偏离gt会导致IoU急剧下降,所以预设的角度参数很多。(例如旋转文本检测RRD设置13个角度,RRPN每个位置54个anchor)。
- 分类回归的不一致。当前很多工作讨论这个问题,即预测结果的分类得分和定位精度不一致,导致通过NMS阶段以及根据分类conf选检测结果的时候有可能选出定位不准的,而遗漏抑制了定位比较精准的anchor。目前工作的解决方法大致可以分为两类:网络结构入手和label assignment优化。
讨论
作者用旋转RetinaNet在HRSC2016数据集上实验可视化检测结果发现,很如下图b,很多低质量的负样本居然能够准确回归出目标位置,但是由于被分为负样本,分类置信必然不高,不会被检测输出;如图a,一些高质量正样本anchor反而可能输出低质量的定位结果。

为了进一步验证这种现象是否具有普遍性,统计了训练过程的所有样本IoU分布,以及分类回归分数散点图,结果如下图。文章将anchor和gt的IoU称为输入IoU,pred box和gt的IoU称为输出IoU。从中看出:
74%左右的正样本anchor回归的pred box后依然是高质量样本(IoU>0.5);近一半的高质量样本回归自负样本,这说明负样本还有很大的利用空间,当前基于输入IoU的label assignment选正样本的效率并不高,有待优化。
图c说明,当前的基于输入IoU的标签分配会诱导分类分数和anchor初始定位能力成正相关。而我们期望的结果是pred box的分类回归能力成正相关。从这里可以认为基于输入IoU的标签分配是导致分类回归不一致的原因之一。这个很好理解,划分样本的时候指定的初始对齐很好的为正样本,其回归后就算产生了不好的预测结果,分类置信还是很高,因为分类回归任务是解耦的;反之很多初始对齐不好的anchor被分成负样本,即使能预测好,由于分数很低,无法在inference被输出。
进一步统计了预测结果的分布如d,可以看到在低IoU区间分类器表现还行,能有效区分负样本,但是高IoU区间如0.7以上,分类器对样本质量的区分能力有限。【问:表面上右半区密密麻麻好像分类器完全gg的样子,但是我们正常检测器并没有出现分类回归的异常,高分box的定位一般也不赖,为什么?一是由于很多的IoU 0.5以上的点都是负样本的,即使定位准根本不会被关注到;二是预测的结果中,只要有高质量的能被输出就行了,其他都会被NMS掉,体现在图中就是右上角可以密密麻麻无所谓,只要右下角没有太多点可视化的检测结果就不会太差。】

方法
3.1 Analysis
首先是baseline用的是附加角度回归的reitnanet。
直观来说,输出IoU能够直接反映预测框的定位能力,那么直接用输出IoU来反馈地选取正样本不就能实现分类回归的一致吗?但是进行实验发现,网络根本不能收敛。即便是在训练较好的模型上finetune,模型性能依然会劣化发散。推测是两种情况导致的:
- 输入IoU大,但是输出IoU小的anchor并不应该被划分为负样本,其更大概率还是正样本的,这部分容易学习的样本丢失严重影响收敛
- 任何样本都可能在训练过程中随机匹配到一个目标,但不应该因此直接确信为正样本,这在训练早期尤为严重
例如,一个anchor回归前IoU为0.4,回归后IoU是0.9,我们可以认为这是一个潜在高质量样本;但是如果一个anchor回归前是0,回归后0.9,他基本不可能是正样本,不该参与loss计算。反之亦然。可见这么简单的思路没有人采用,不是没人想到,而是真的不行。相似的label assignment工作中,即使利用了输出IoU也是用各种加权或者loss等强约束确保可以收敛,有一个只利用输出IoU进行feedback的工作,但是我复现的时候有很多问题,实验部分会介绍。
3.2 Dynamic Anchor Selection
可以理解为输入IoU是目标的空间对齐(spatial alignment),而输出IoU是由于定位物体所需重要特征的捕捉能力决定的,可以理解为特征对齐(feature alignment)能力。据此定义了匹配度(matching degree)如下:
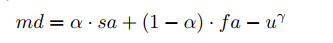
前两项比较好理解,通过输入IoU表征的空间对齐能力对anchor的定位性能作先验缓和上面的两种情况以稳定训练过程。第三项表征的是回归前后的不稳定性作用,对回归前后的变化进行惩罚。实际上这一项是有效利用输出IoU的关键,后面的实验会证明这一点。自己私下的实验中发现,有了 f a fa fa和 u u u两项(即α = 0)实际上就能实现超越输入IoU的labelassignment了,但是输出IoU很不稳定,参数比较难调,而加入空间先验后稳定了很多,效果也能保持很好的水平。
这个不确定性惩罚项u uu有很多表征形式,之前试过各种复杂花哨的表征和加权变换,虽然相对现有形式有所提升但是提升空间不大。没必要搞得故弄玄虚的,所以最后还是保留了这种最简单的方式。
有了新的正样本选择标准,直接进行正常的样本划分就能选出高质量的正样本。这里还能进一步结合一些现有的采样和分配策略进一步获得更好的效果(如ATSS等),论文没有展示这部分实验可以自己尝试。学习策略上,在训练前期为了避免输出IoU的不稳定影响,采取逐渐加大空间对齐影响系数,直至设定值。实验证明这个策略不影响最终效果,只是加速收敛。
3.3 Matching-Sensitive Loss
得到匹配度矩阵后,我们可以将其加权到训练loss中,核心思想是增强分类器对高质量样本的识别效果,从而解决Motivation中提到的分类回归不一致的问题。具体而言就是将匹配度矩阵进行补偿,最大值补偿到1,补偿值加权到正样本上去,使之更多地关注高性能样本的分类和回归性能。一开始我采用的是直接将md加权到loss,效果很差找问题调了一段时间才解决。补偿加权的方法相比直接加权有两个好处:
- 避免分类器对匹配度划定的负样本进行不合理的关注。比如在md补偿的策略下,一个低质量正样本可能导致很大的补偿值从而带来一堆低质量正样本;
- 由于匹配度是介于[0,1],直接加权将导致正样本被进一步稀释;
- 确保分类和回归任务对补偿的anchor的足够关注,每个样本至少有一个anchor能学好。例如对于某个gt最大md为0.2,直接加权将导致其loss贡献很小,本来就难匹配的目标更难学了。
损失函数表示和具体分析如下:
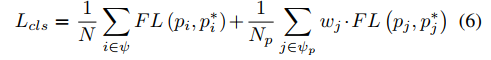
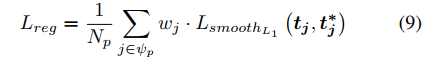
对于分类任务而言,如果正样本全部置为1,就无法区分高效md不同的样本了(显然md=0.1和md=0.9的样本被分为正样本的概率不应该一样)【问:检测器正常情况下就是这么做的,咋就没你这么多事?不是不能区分。可行的原理是通过不断的学习,优化下降loss来对“边缘”程度不同的hard example进行判断。所以我们看到定位能力和分类分数常常不会差得很远,这都是反复的优化的结果。显然这种策略有效但是很笨,其中显然还有东西可以做,可以大大提高训练效率】。所以这里通过构造带有定位潜力信息的md补偿矩阵来加权loss进一步关注高质量正样本的学习情况,使得分类得分更加准确有效,提高NMS的准确性。
对于回归任务而言,早在cascade RCNN就提出过高精度anchor对loss贡献相对小而难以优化的问题,还有很多工作从IoU分布、重采样、归一化等方法缓解这个问题。这里我们采用的还是匹配度信息,方法也是很质朴的对正样本re-weight;只不过加权关注的不再是空间对齐的anchor,而是对根据md度量的高质量样本给予更多的关注。
采用匹配度敏感的loss能够有效增强检测器的精确定位样本的区分能力,如下图所示,左边是正常训练检测器,可以看到定位精度上高性能部分的额区分度很低,但是加了MSL后样本的定位性能大大提高,同时分类分数也对应提高,越往右上角颜色越深,分类分数和定位性能有较好的关联性。很多分析由于原论文篇幅有限没有展开。

实验
参见原论文或https://zhuanlan.zhihu.com/p/337272217
这篇关于旋转目标检测AAAI2020之DAL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






