本文主要是介绍数字孪生|山海鲸数据管家简介及安装步骤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
哈喽,大家好啊,我是雷工!
最近在学习数字孪生相关的软件山海鲸,了解到采集Modbus协议需要先安装山海鲸数据管家,本节先学习数据管家及安装步骤,以下为学习笔记:
1、简介
数据管家是帮用户进行数据管理与转发的软件,能够解决山海鲸可视化等软件对数据接入过程中的许多常见问题。
本软件兼容多种操作系统(本例以Windows版本为例),不仅能够管理各种数据源,还可以对多种不同数据结构的数据进行融合,而且能够通过拖拽流程图的形式对数据进行处理并提供调用接口。
通过介绍了解感觉该软件应该是类似亚控的KingIOServer软件,负责数据采集管理的。
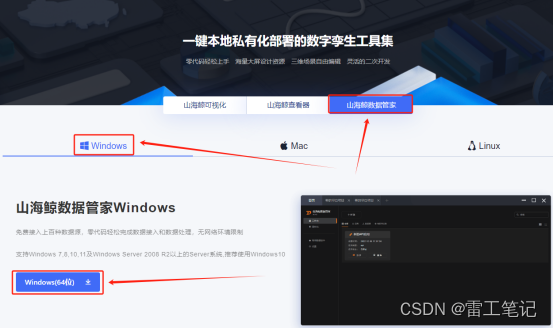
2、下载软件
首先找到软件的下载界面,找到对应系统的版本,点击下载。
3、安装步骤
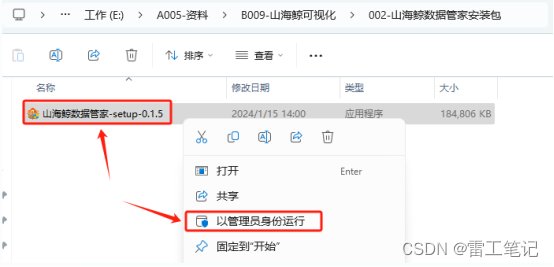
3.1、以管理员身份运行
选中下载的安装包,右键选择以管理员身份运行。
3.2、选择我同意
这篇关于数字孪生|山海鲸数据管家简介及安装步骤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








