本文主要是介绍55 npm run serve 和 npm run build 的分包策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
这里我们来看一下 vue 这边 打包的时候的一些 拆分包的一些策略
我们经常会使用到 npm run build 进行服务的打包
然后 打包出来的情况, 可能如下, 可以看到 chunk-vendors 是进行了包的拆分, 我们这里就是 来看一下 这里 npm run build 的时候的, 一个分包的策略
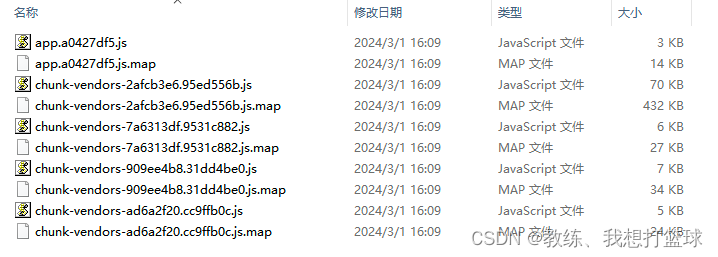
测试配置
在 vue.config.js 中配置 webpack 打包配置如下
对于 node_modules 下面的所有的依赖, 限定分包策略为 最小10kb, 最大10kb
const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({transpileDependencies: true,configureWebpack: {optimization: {splitChunks: {cacheGroups: {defaultVendors: {test: /[\\/]node_modules[\\/]/,priority: 10,minSize: 10000,maxSize: 10000,},default: {chunks: "all",minSize: 10000,maxSize: 10000,},}}}}
})
chunk-vendors 分组的分包策略
首先超过 maxSize 的包会被单独拧出来形成一个单独的包, 不管他的大小多大
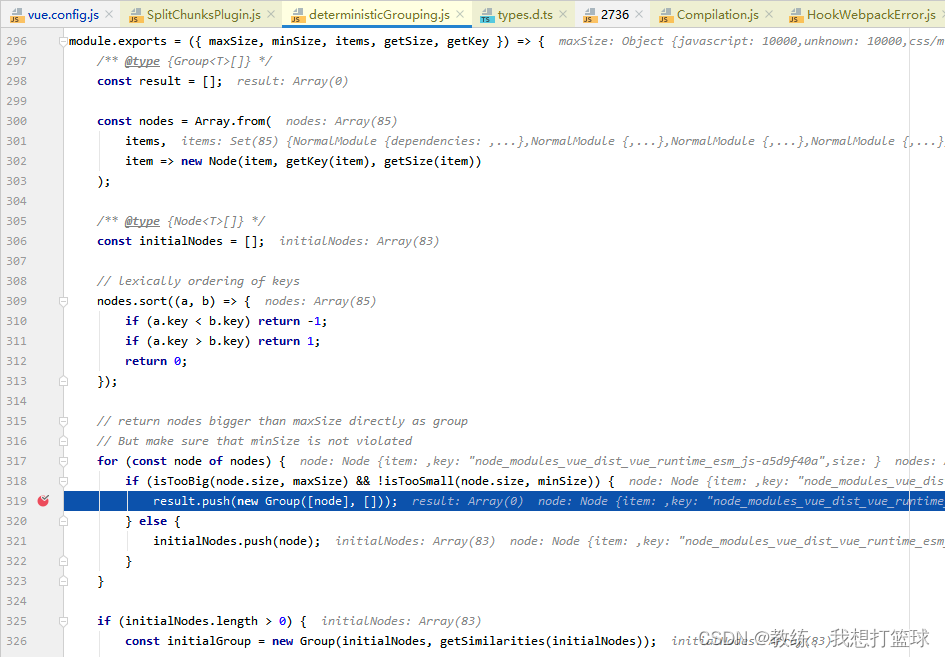
然后其次就是 具体的分包的处理了
如果当前 js 添加到当前包未超过 maxSize, 继续迭代下一个
如果当前 js 太小了, 则重新放回队列, 继续迭代下一个
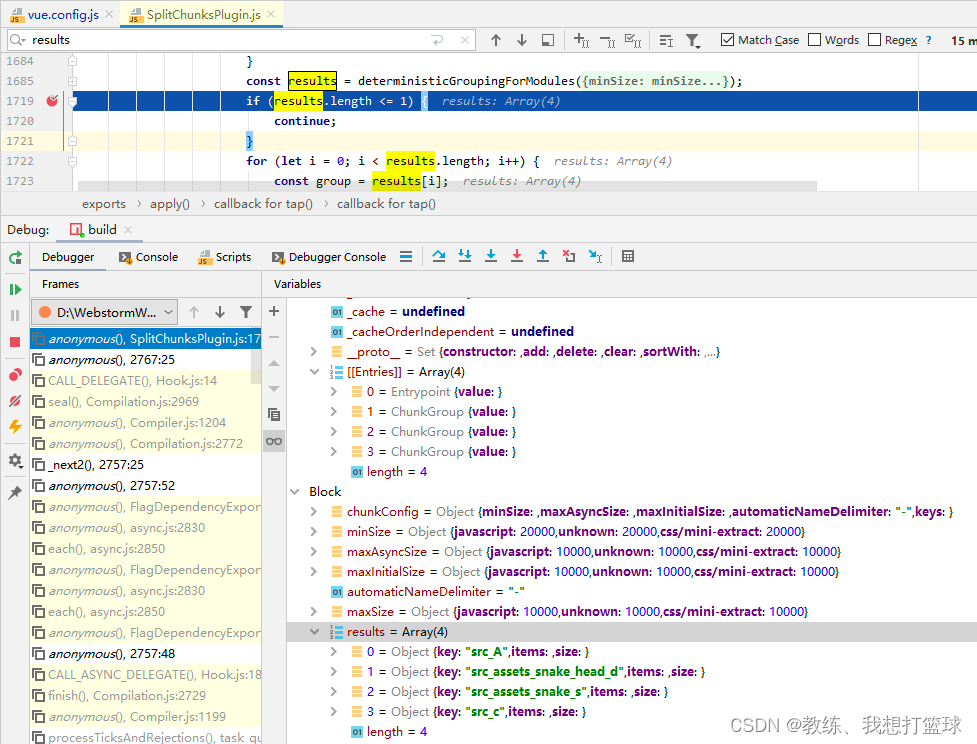
接下来就是 这里定义的一个拆包的算法了, 这里不细说, 我们也不关注具体的拆分的细节
循环结束, 拆分包的过程就结束了, 拆分成了 n 个小包
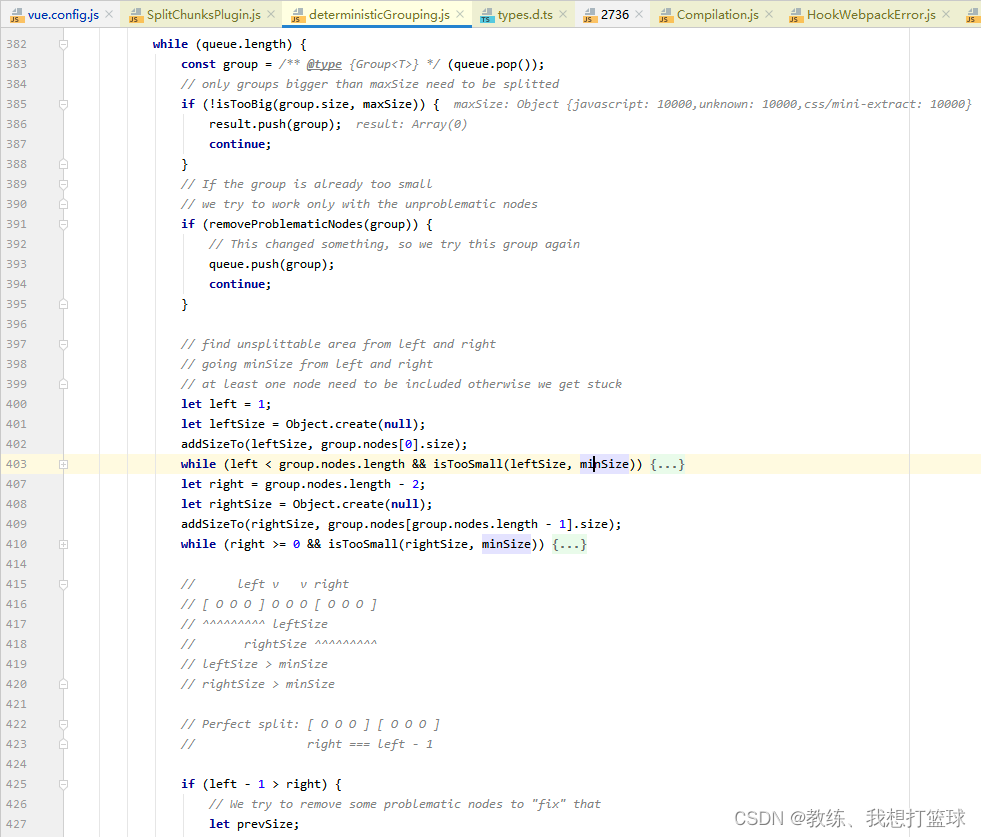
拆分的过程调试如下
比如这里 vue.runtime.esm.js 包 268kb, 超过了配置的 10kb 的大小, 直接拧出来形成一个单独的 chunk
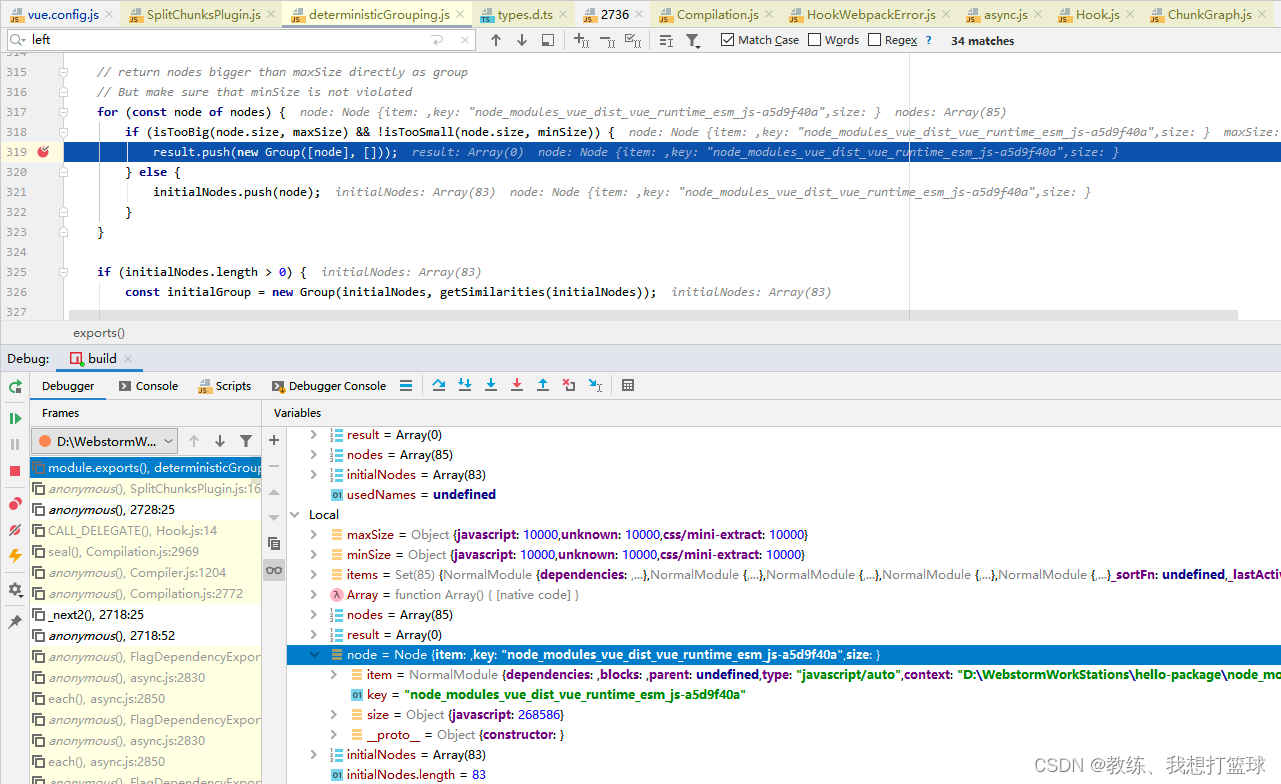
接下来 32 个 js, 合计 15kb, 形成一个 chunk
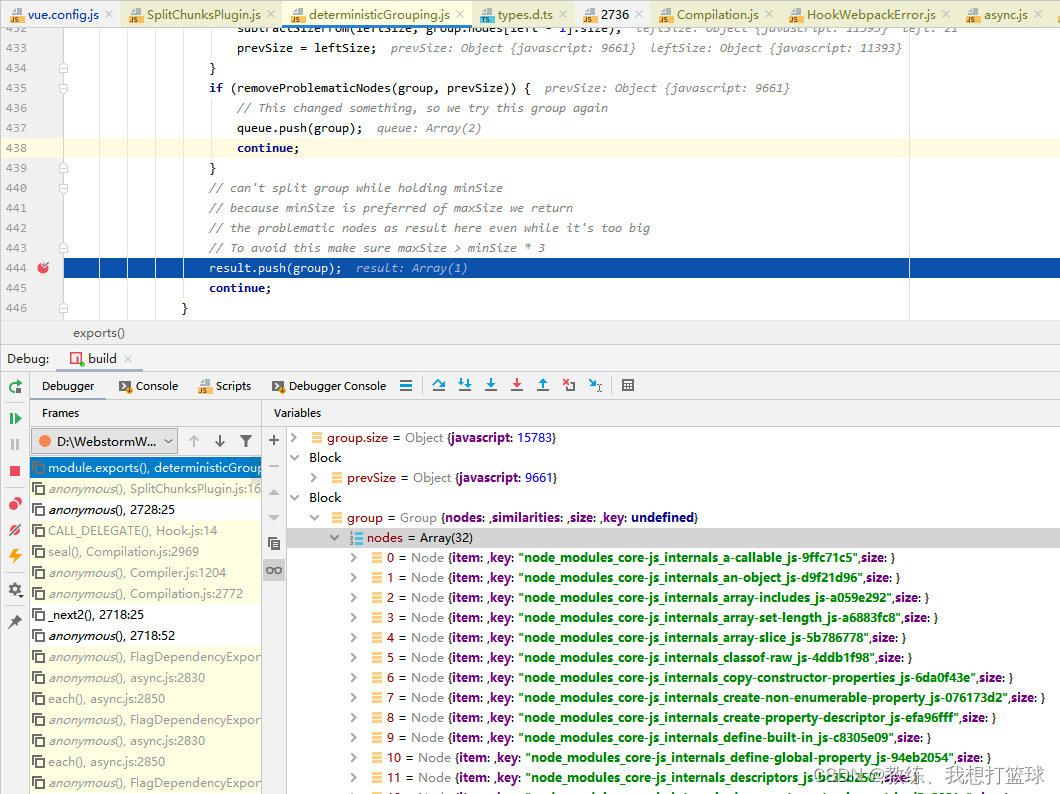
接下来也是 32 个 js 形成一个 chunk
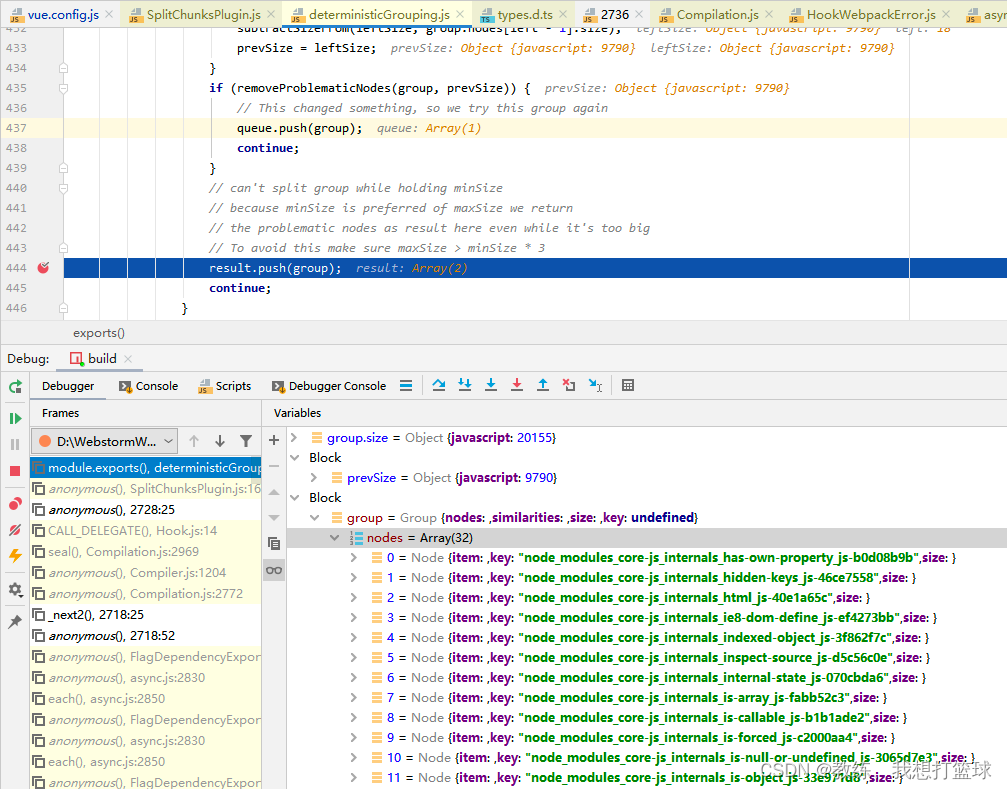
接下来是 剩余的 14 个 js 形成一个 chunk
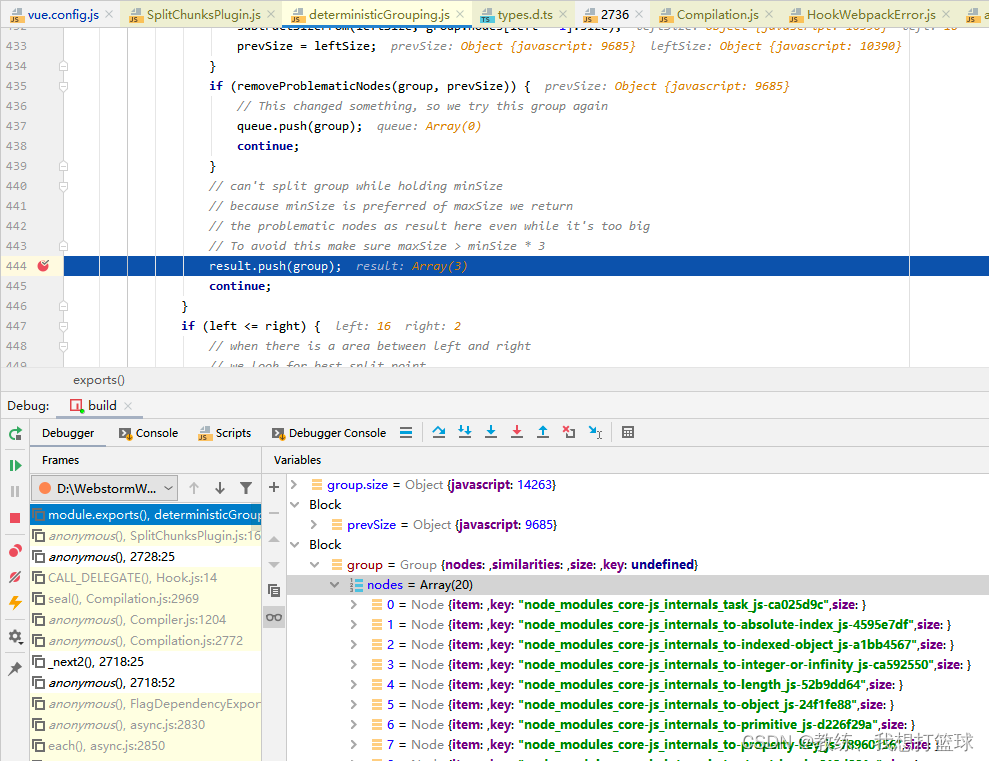
当前 chunk 的命名方式是获取 第一个元素的名称 和 最后一个元素名称 的最大公共部分
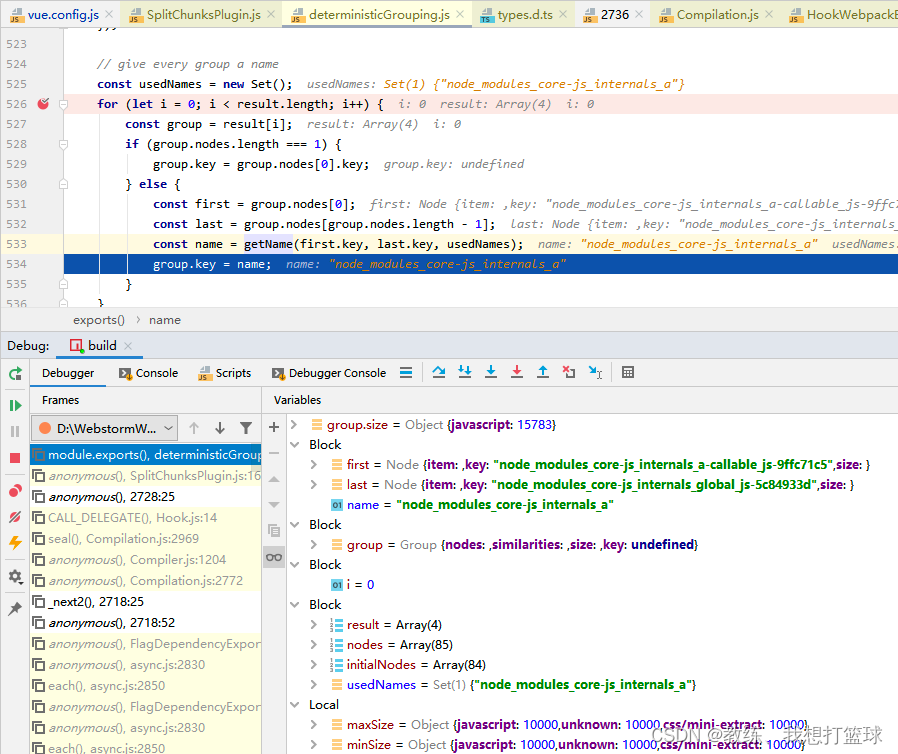
然后这里是在 compilation 中新增各个 chunk 的地方
chunk 的的名称后缀是根据 group 的名称进行 hash 生成的

然后 如图, 就是编译结果的 chunk-vendors-7a6313df 文件, 里面包含了 32 个 js 文件, 然后 minify 压缩之后, 只有 6kb
要看各个 chunk-vendors 中包含了那些 js, 只能通过运行时调试查看
然后 chunk-vendors-2afcb3e6 这个显然就是 vue.runtime.esm.js 文件, minifiy 压缩之后, 只有 70kb
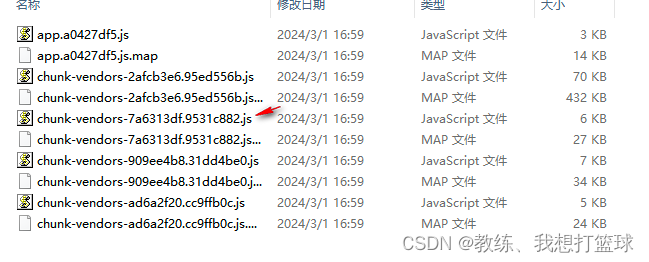
示例项目中各个 module 大小, 以及各个 chunk 对应的 module 列表如下 excel
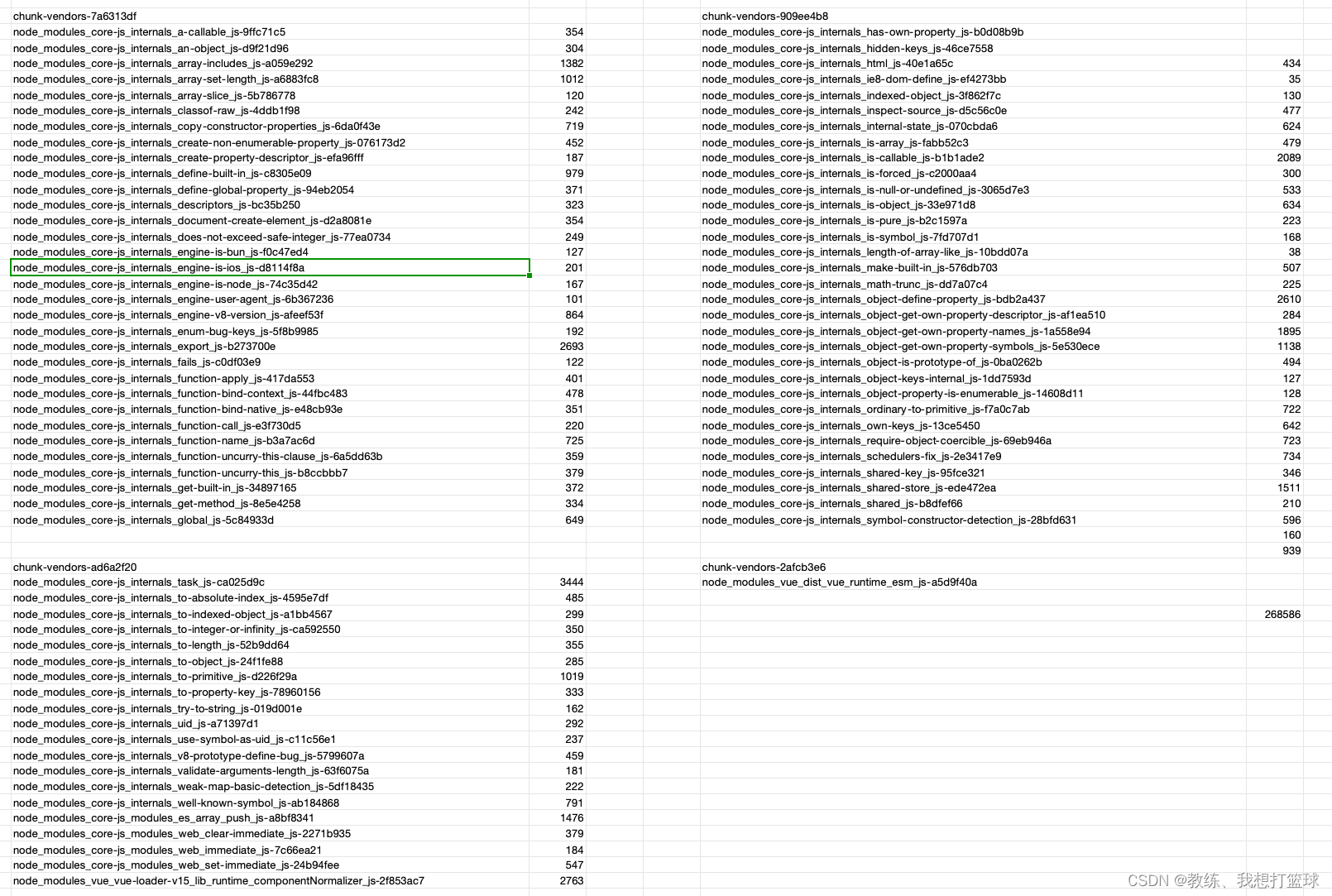
npm run serve 中的 app.js 中默认情况下的 chunk 的拆分
app.js 的拆分分了很多种情况, 这里 我们先来看下 默认的行为
vue.config.js 配置如下
const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({transpileDependencies: true,configureWebpack: {optimization: {splitChunks: {cacheGroups: {defaultVendors: {test: /[\\/]node_modules[\\/]/,name(module) {return "defaultVendors"},// chunks: "all",// minChunks: 3,priority: 10,// minSize: 10000,maxSize: 10000,},// default: {// chunks: "all",// name(module) {// return "app11"// },// // filename: "app112"// // priority: -10,// // minSize: 10000,// maxSize: 10000,// },}}}}
})
增加路由配置文件如下, 如下配置了三个路由
import Vue from "vue";
import Router from "vue-router";Vue.use(Router)export default new Router({routes: [{path: '/',name: 'HelloWorld',component: () => import('../components/snake/Game.vue')}, {path: '/HelloWorld',name: 'HelloWorld',component: () => import('../components/HelloWorld')}, {path: '/AsyncQueue',name: 'AsyncQueue',component: () => import('../components/AsyncQueue.vue')}]
})
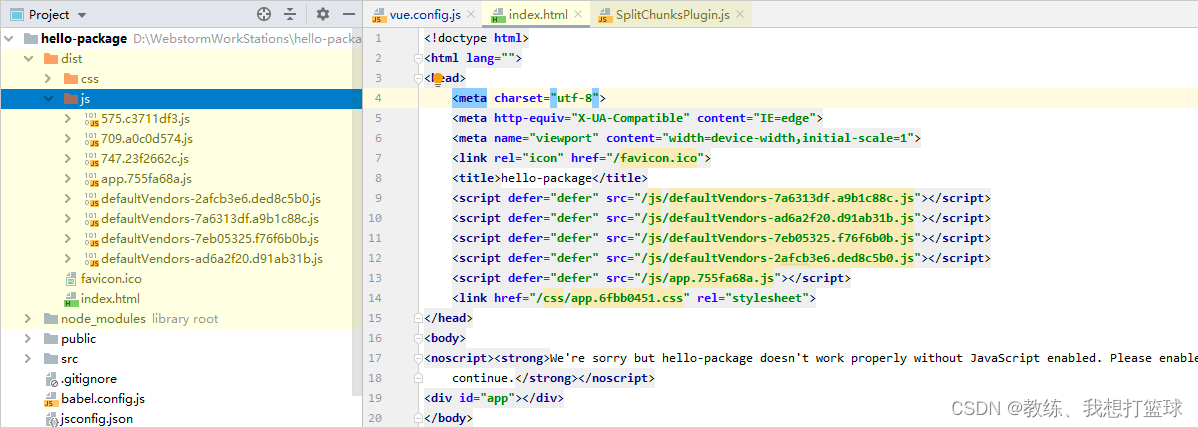
编译之后的生成的 js 相关的目录结构如下, 我们这里关注 app.js 相关的
即 app.js 和 src_components_xxx 相关的三个文件, 其他的为 node_modules 编译之后生成的项目文件
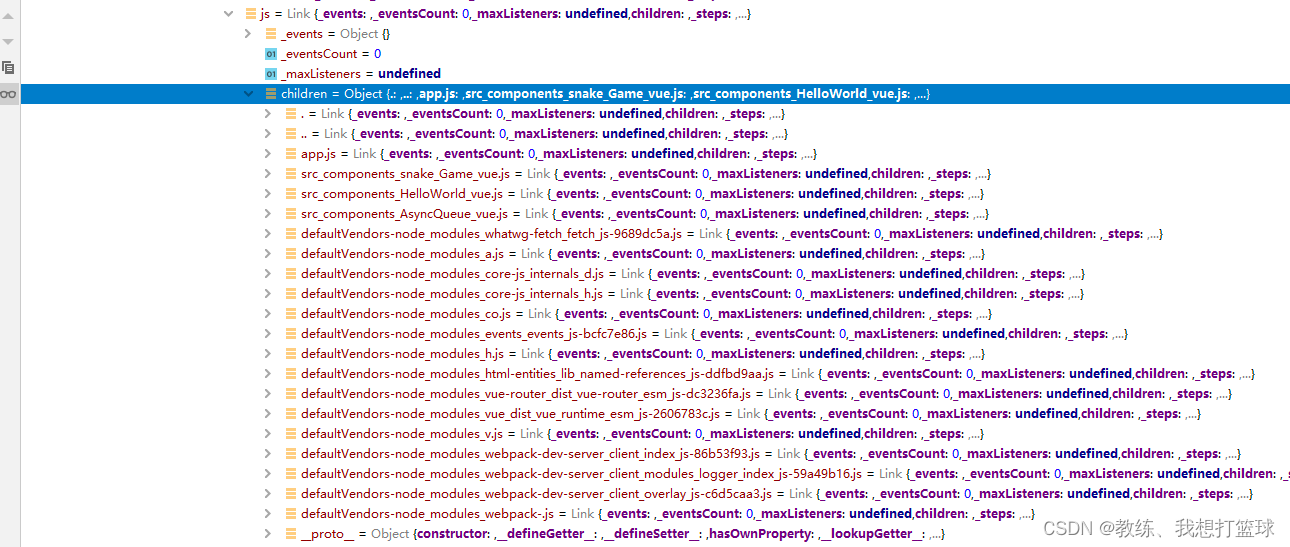
然后我们看一下 app.js 中 chunk 的拆分
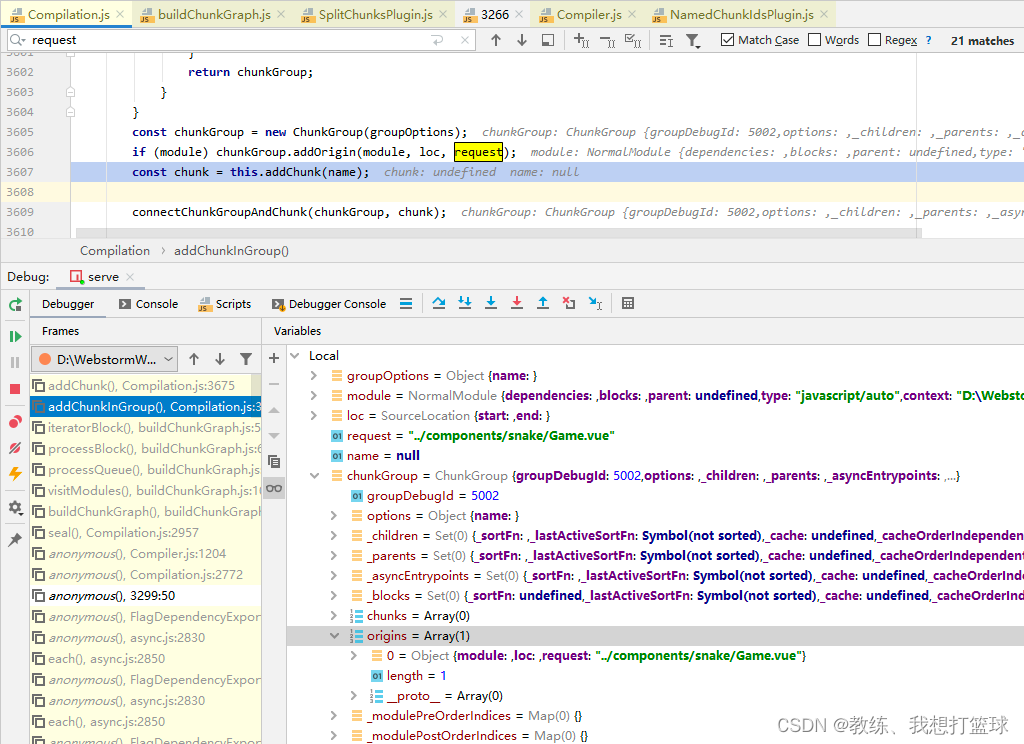
在 visit “src\router\index.js” 的时候, 发现了三个 import(), 然后 采集为 blocks
然后 这里单独拆分出来, 成为单独的 chunk
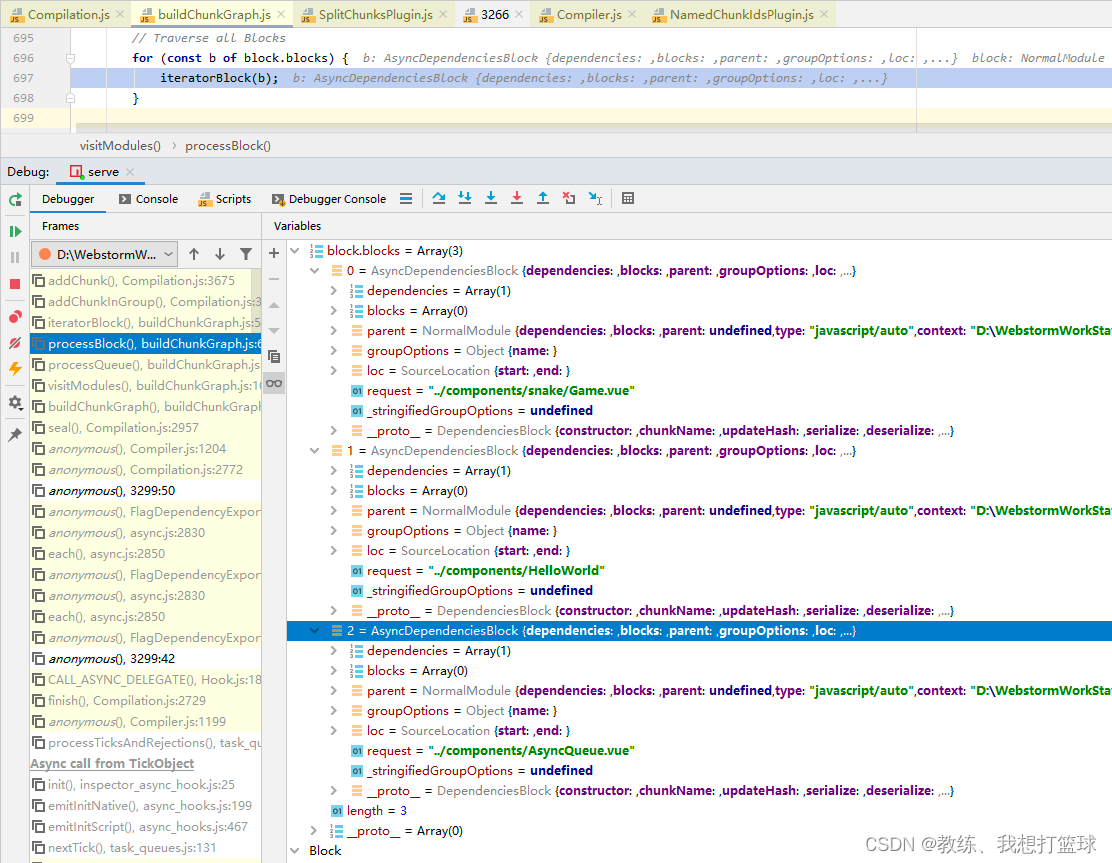
该 chunk 里面没有保存上下文的任何信息, 上下文的信息是保存在 chunkGroup 中的, 后面对 chunk 和 chunkGroup 进行了关联
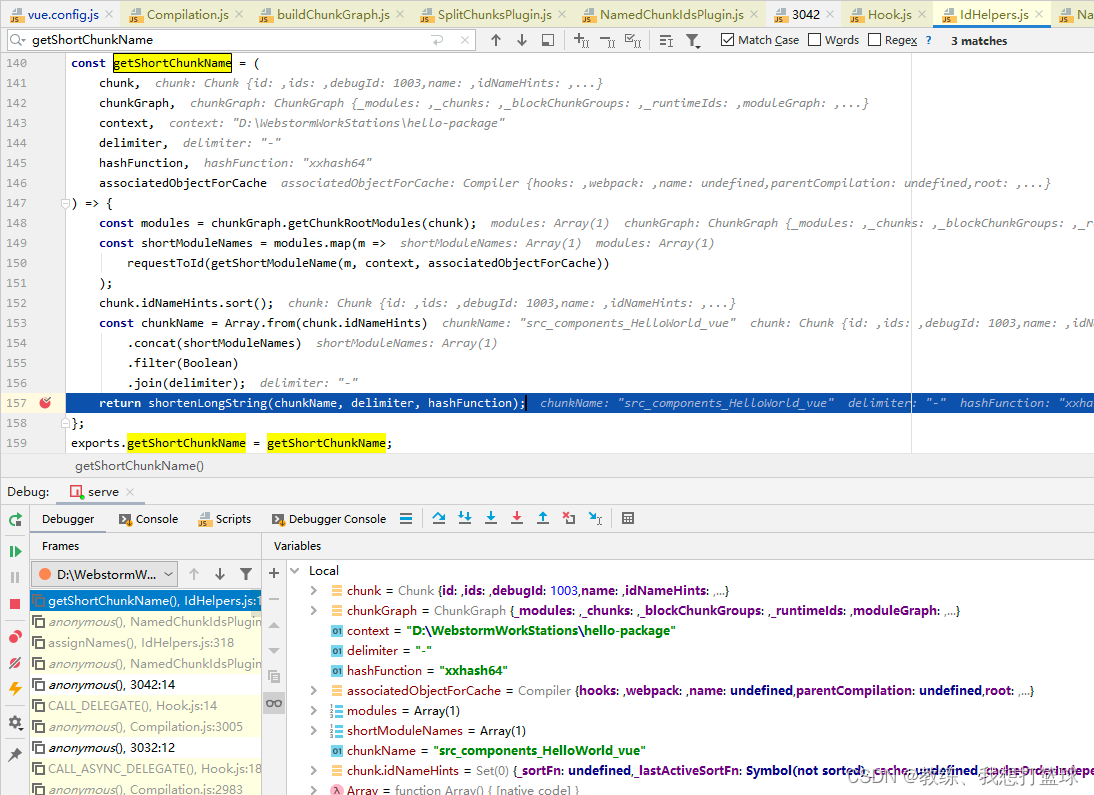
为目标 chunk 生成 chunkName 的地方是在 NamedChunkIdsPlugin.js 中, 从 chunkGroup 中相关数据中可以拿到目标 chunk 是属于哪一个文件的
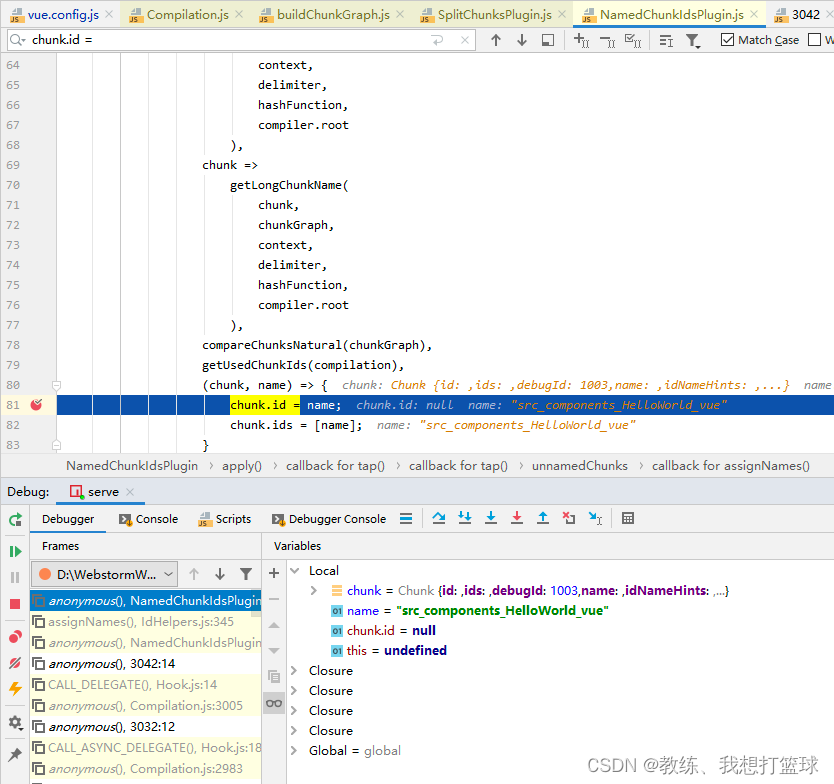
npm run build 中的 app.js 中默认情况下的 chunk 的拆分
整体的流程 和 上面 npm run serve 中的 app.js 的拆分情况如下
计算 chunk 的 id, 名称如下
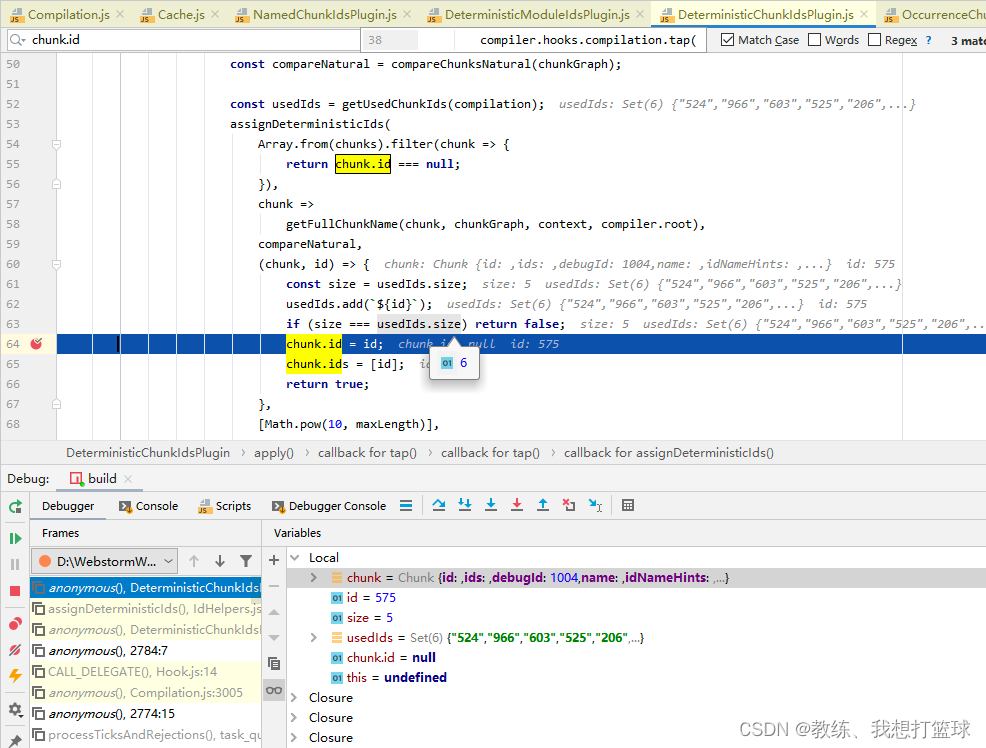
使用 numberHash 进行计算, 如果重复了, 就重新计算
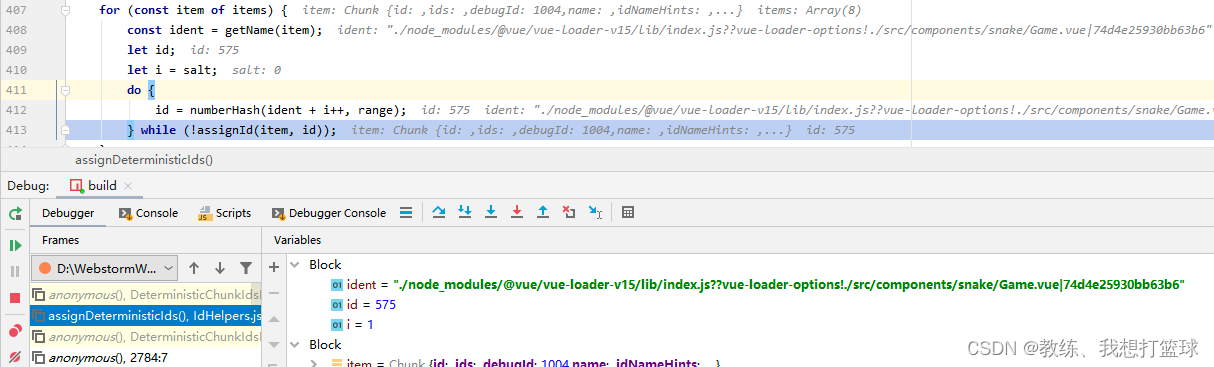
整体来说, chunk 名称和其内容没有什么较为明显的关联
因此, 只能通过 文件内容, 来定位具体的业务组件是在哪一个文件中了
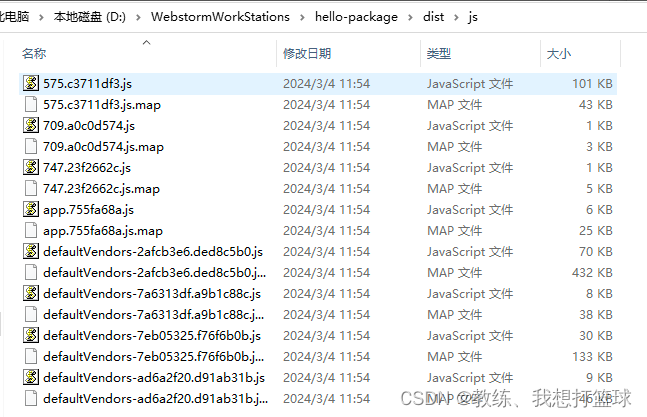
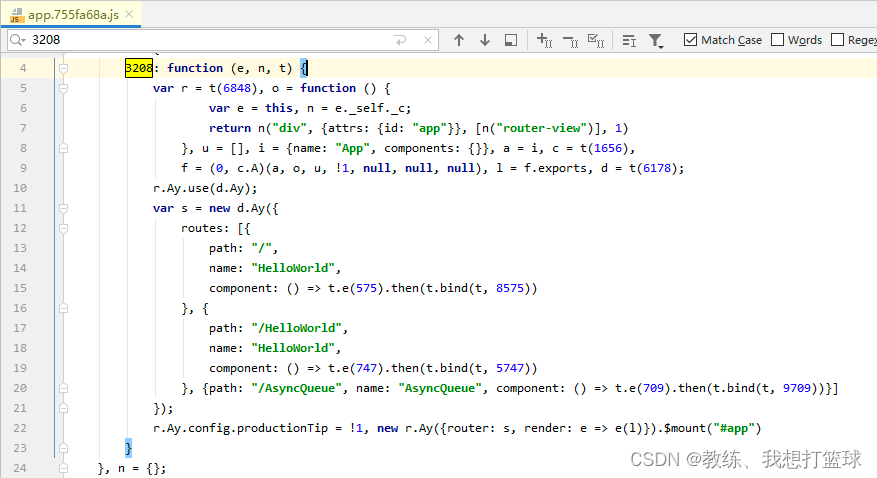
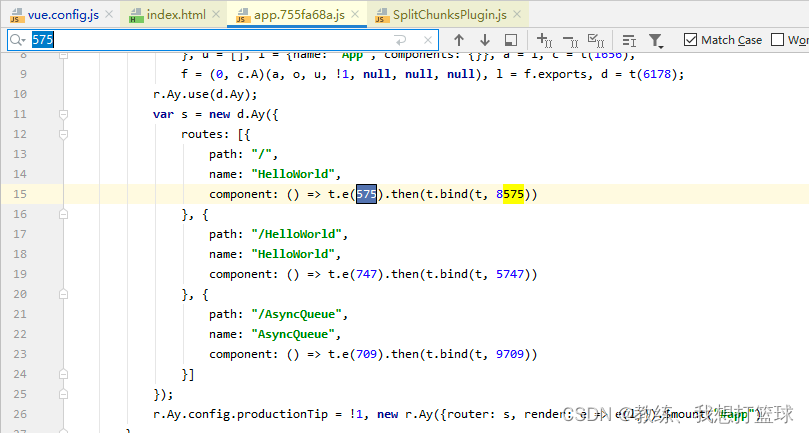
但是可以通过 app.js 来进行一个粗略的查找, entryPoint 编号为 3208

这里便是整个路由, 这两批可以看到 具体的路由信息, 以及组件信息, 比如 “/HelloWorld” 对应于组件 575
app.js 的手动拆包配置
和上面 chunk-vendors 的拆包的配置类似, app.js 相关, 也是可以手动配置 拆包
配置 vue.config.js 的配置如下, 其中 default 下面的配置对应的是 app.js 的配置
const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({transpileDependencies: true,configureWebpack: {optimization: {splitChunks: {cacheGroups: {defaultVendors: {test: /[\\/]node_modules[\\/]/,name(module) {return "defaultVendors"},// chunks: "all",// minChunks: 3,priority: 10,// minSize: 10000,maxSize: 10000,},default: {chunks: "all",name(module) {return "app11"},// filename: "app112"// priority: -10,// minSize: 10000,maxSize: 10000,},}}}}
})
打包之后结果如下, 可以看到的是 拆分的和 chunk-vendors 的拆分貌似类似
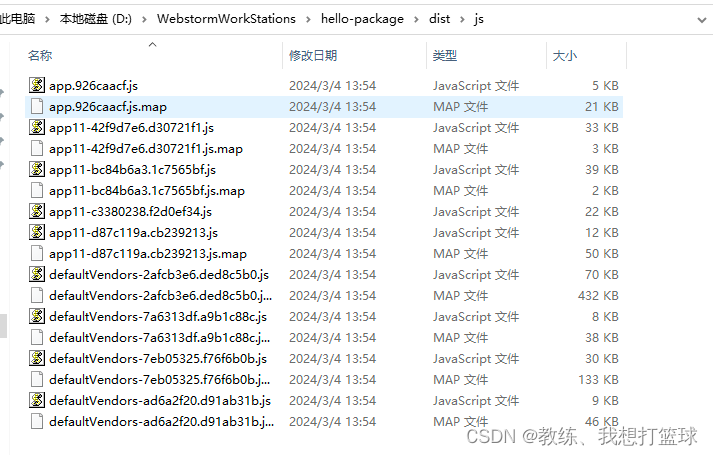
假设是手动配置了分包的相关配置, 这里 具体的拆分就是和 chunk-vendors 类似的分包拆分处理
在 SplitChunksPlugin 中进行的处理, 这里可以参见上面的 chunk-vendors 的分包策略处理
app.js 的默认分包 和 手动配置的分包 的差异
这个是从另外的一个维度 来进行的分析
在默认的分包处理下, 可以看到 我们这里访问 HelloWorld, 仅仅是请求了 HelloWorld 的相关的组件
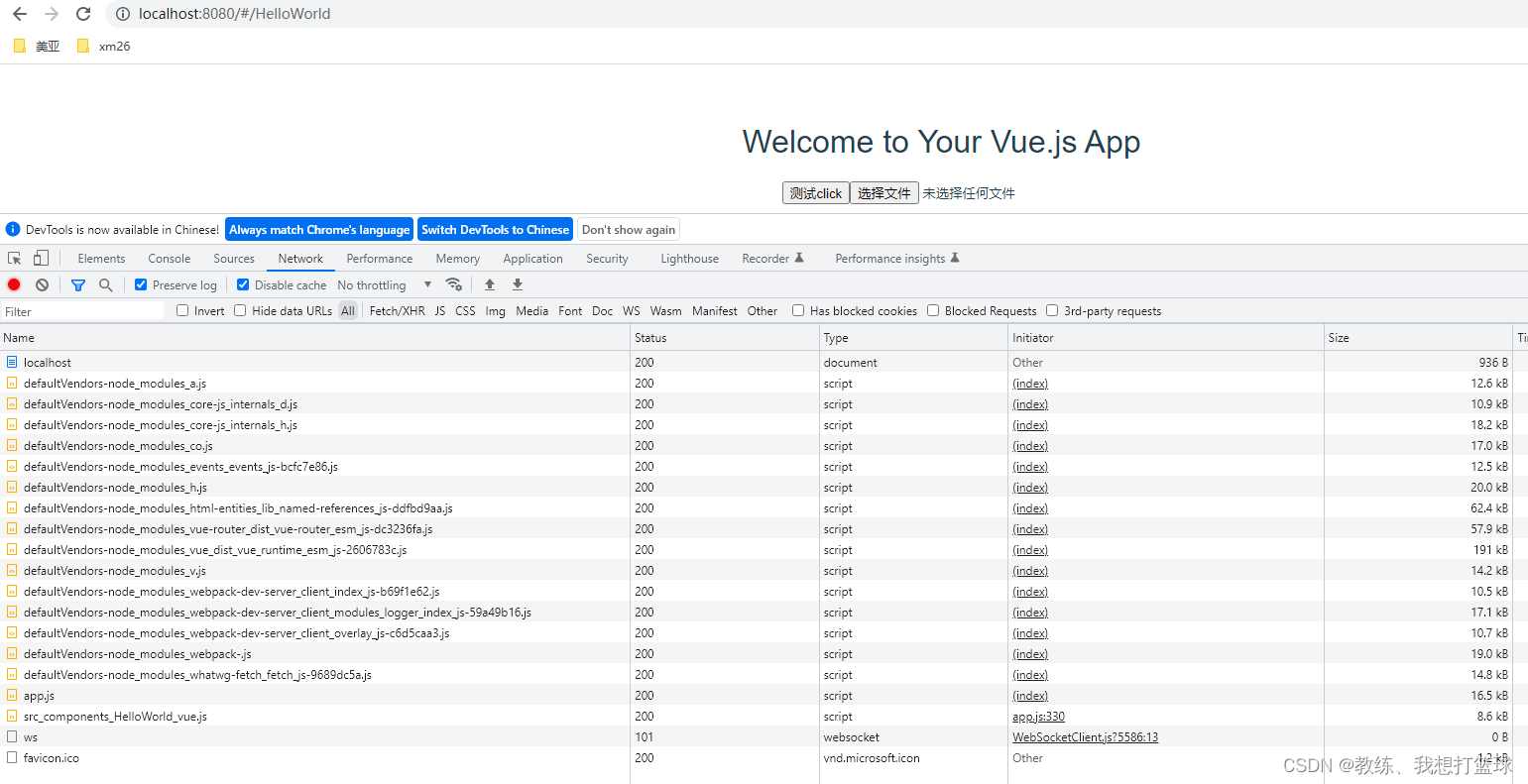
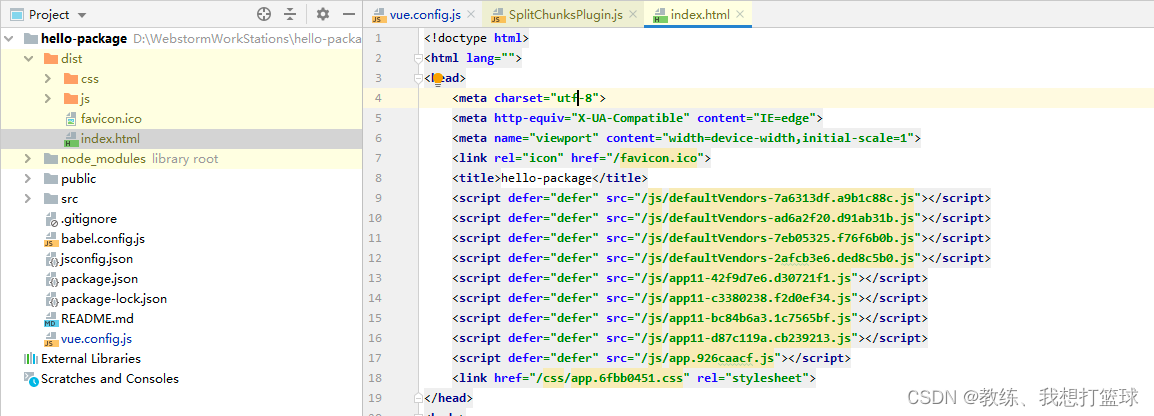
编译出来的 index.html 如下, 可以看到的是 仅仅是导入了 app.js 这个入口的 chunk
对于路由下面的各个情况, 是导入的各自的 js
js 的映射如下
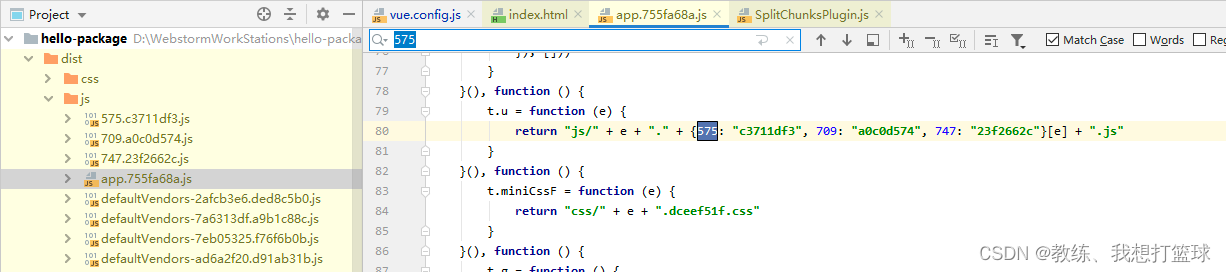
在手动分包的处理下, 可以看到 请求了 app.js 囊括的所有的 js
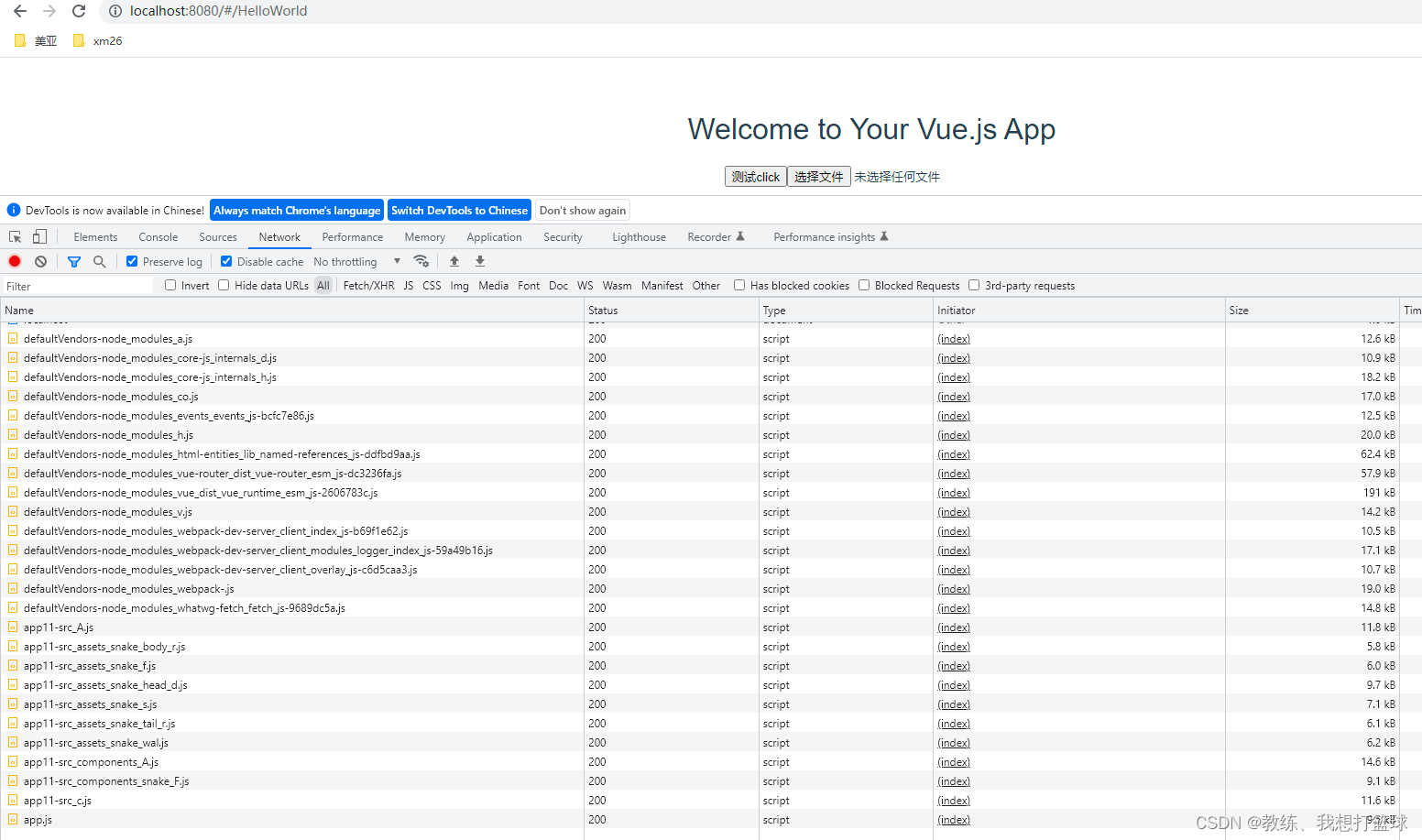
编译出来 index.html 如下, 可以看到是 引入了所有的包, 不管是进入哪一个页面, 都是请求的全量的 app.js 和 chunk-vendors.js
app.js 的默认分包的每一个组件包含了那些东西?
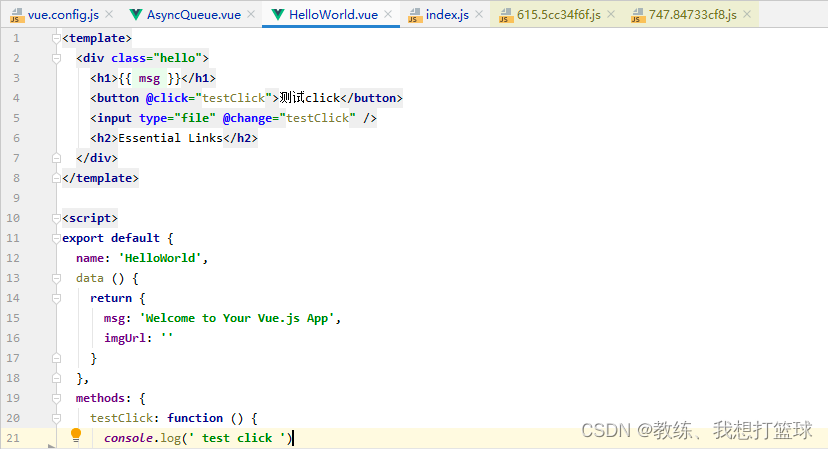
HelloWorld.vue 文件内容如下
AsyncQueue.vue 文件内容如下, 导入了一个 HelloWorld.vue 的组件
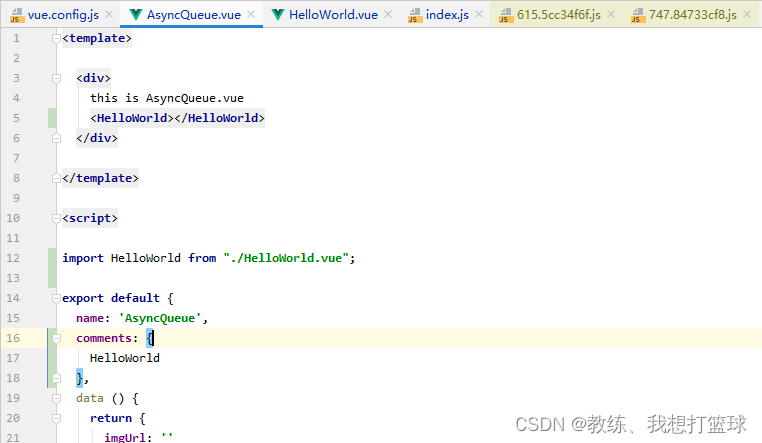
然后编译完之后的 import('../components/HelloWorld') 如下
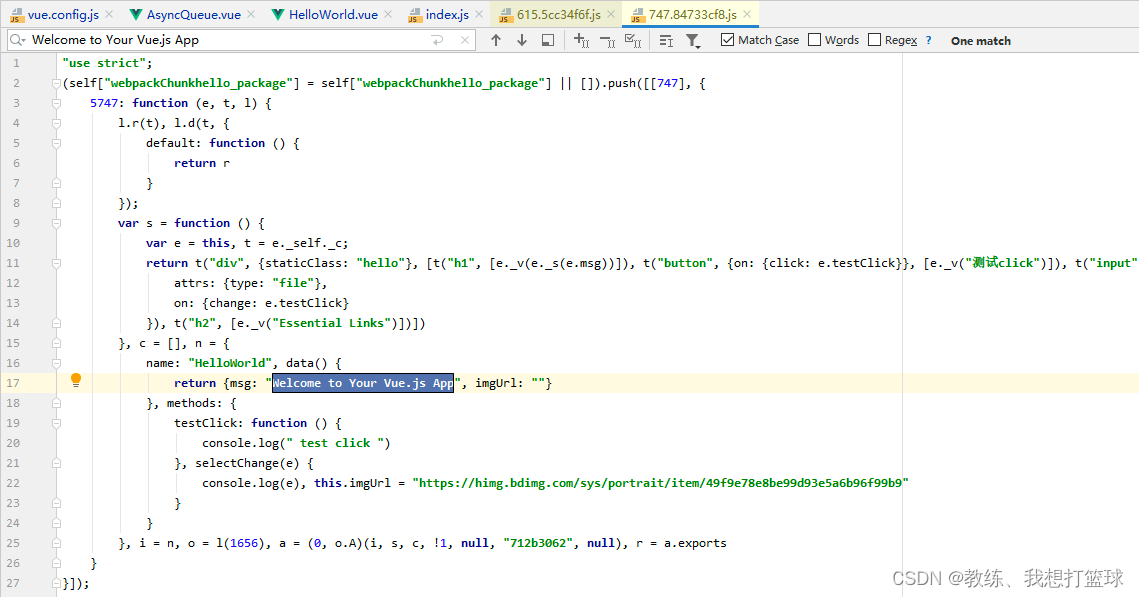
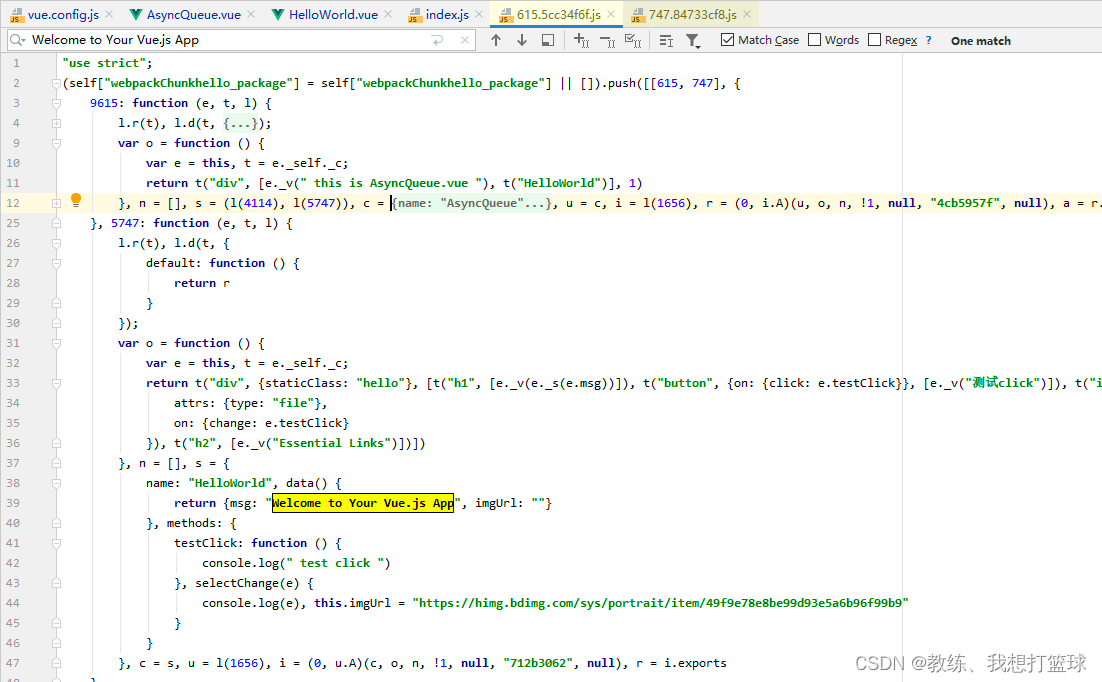
然后编译完之后的 import('../components/AsyncQueue) 如下
可以看到 编译之后的结果 是将使用到的组件都内联进来了, 这样可能导致一些公用组件的内容被内联很多次, app.js 总共的包大小 膨胀
但是 页面时按照需要导入的对应的 js
增加了一些 编译器编译的开销, 服务器存储的开销, 减小了客户端请求的开销
完
这篇关于55 npm run serve 和 npm run build 的分包策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




