本文主要是介绍006 高并发内存池_PageCache设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🌈个人主页:Fan_558
🔥 系列专栏:高并发内存池
🌹关注我💪🏻带你学更多知识

文章目录
- 前言
- 文章重点
- 一、回顾PageCache页缓存结构
- 二、PageCache结构设计
- 三、完善申请内存函数
- 小结
前言
本文将会带你走进高并发内存池PageCache页缓存的设计
文章重点
在此模块中,我们将要完成以下任务
1、回顾PageCache页缓存结构
2、PageCache结构设计
3、完善GetoneSpan获取一个非空的span与在PageCache中获取一个n页的span
一、回顾PageCache页缓存结构
前文提到这里我们就最大挂128页的span,为了让桶号与页号对应起来,我们可以将第0号桶空出来不用,因此我们需要将哈希桶的个数设置为129。
线程申请单个对象最大是256KB,而128页可以被切成4个256KB的对象,因此是足够的。当然,如果你想在page
cache中挂更大的span也是可以的,根据具体的需求进行设置就行了
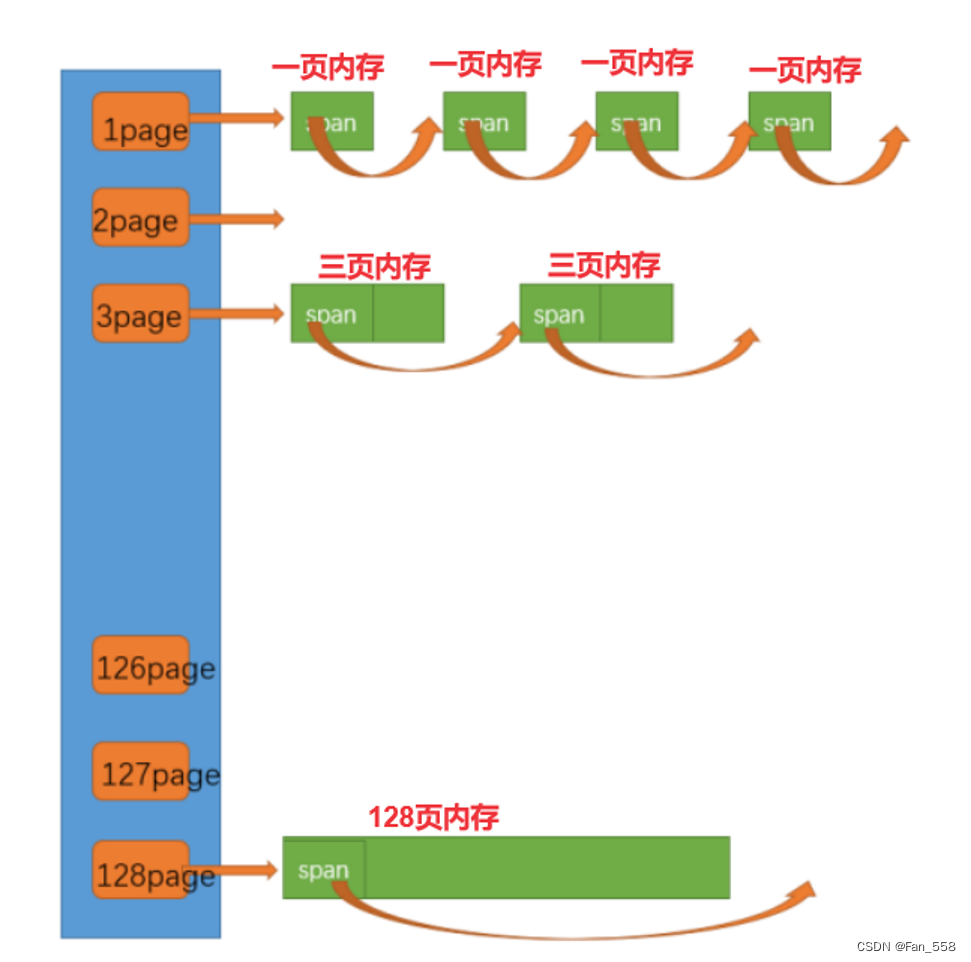
当线程向ThreadCache申请内存对象的时候,ThreadCache没有就要去CentralCache要,CentralCache没有就要去PageCache要,当PageCache也没有的话,只能去堆上申请,在定长池一篇文章中,我们提到过向系统申请内存的接口,并且封装了它
当PageCache中也没有内存时,此时需要向系统(堆)申请一个128Page大小的内存span,将kspan=128传入作为参数传入
#ifdef _WIN32
#include <Windows.h>
#else
#endifPageCache PageCache::_sInst;inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}
此时我们再来观察span的内部结构,其中_PageId是所申请大块内存起始页的页号,这个页号是与从堆上被分配的内存的起始地址有关系的,我们假设一页内存的大小是8K,那么将这个起始地址➗8K就是它的起始页号,再来观察传给VirtualAlloc的参数
kpage << 13,也就是用页数✖8K(2^13)作为所申请的内存大小
//管理以页为单位的大块内存
struct Span
{//给缺省值,可以不用提供构造函数PAGE_ID _pageId = 0; //大块内存起始页的页号(从堆上分配内存的起始地址size_t _n = 0; //页的数量Span* _next = nullptr; //双链表结构Span* _prev = nullptr;size_t _useCount = 0; //切好的小块内存,被分配给thread cache的计数void* _freeList = nullptr; //切好的小块内存的自由链表
};
二、PageCache结构设计
PageCache在整个进程中也是只能存在一个的,由此我们也将其设置为单例模式
//单例模式(饿汉
class PageCache
{
public://提供一个全局访问点static PageCache* GetInstance(){return &_sInst;}
private:SpanList _spanLists[NPAGES];std::mutex _pageMtx; //大锁
private:PageCache() //构造函数私有{}PageCache(const PageCache&) = delete; //防拷贝static PageCache _sInst;
};
当程序一运行,该对象就被创建
PageCache PageCache::_sInst;
三、完善申请内存函数
一、GetoneSpan模块
1、先在CentralCache对应桶中遍历span,如果不为空就返回(上文结尾提到)
2、这里需要注意:当CentralCache中span为空的时候,此时我们需要向PageCache申请,在此之前
需要先将CentralCache上对应的桶锁给解开,因为当一个线程持续向下申请,threadcache->centralcache->pagecache,此时直至申请到了pagecache,然而centralcache是有桶锁的,是需要线程一走后进行解锁的
不然当线程二申请,虽然申请不到,因为本就没有内存,但是如果线程二是释放呢,那么影响就很大了
所以就需要向pagecache申请之前将锁解开,这样如果其它线程释放内存回来,不会阻塞。
3、对于PageCache的结构我们是需要给一把大锁的,直接在申请PageCache的span函数加锁解锁即可
疑问:为什么不像CentralCache一样设置对每一个桶设置一个桶锁呢?
首先PageCache不像centralcache一样匹配到哪个桶就去哪个桶中申请,没有就向pagecache申请,各个桶之间不会有过多的交集
但是PageCache不一样,如果第k号桶没有,会到k-128的桶全部遍历一遍,不是说桶锁不行,而是频繁的加锁解锁唤醒睡眠,效率变低
(在NewSpan在PageCache中获取一个n页的span函数模块会讲)
PageCache::GetInstance()->_pageMutex.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(AlignNum));PageCache::GetInstance()->_pageMutex.unlock();
Newspan模块申请一个n页的span先保留,我们先将此模块的代码逻辑完善
4、将一个从PageCache申请的大块内存切分成由一个span指向的自由链表
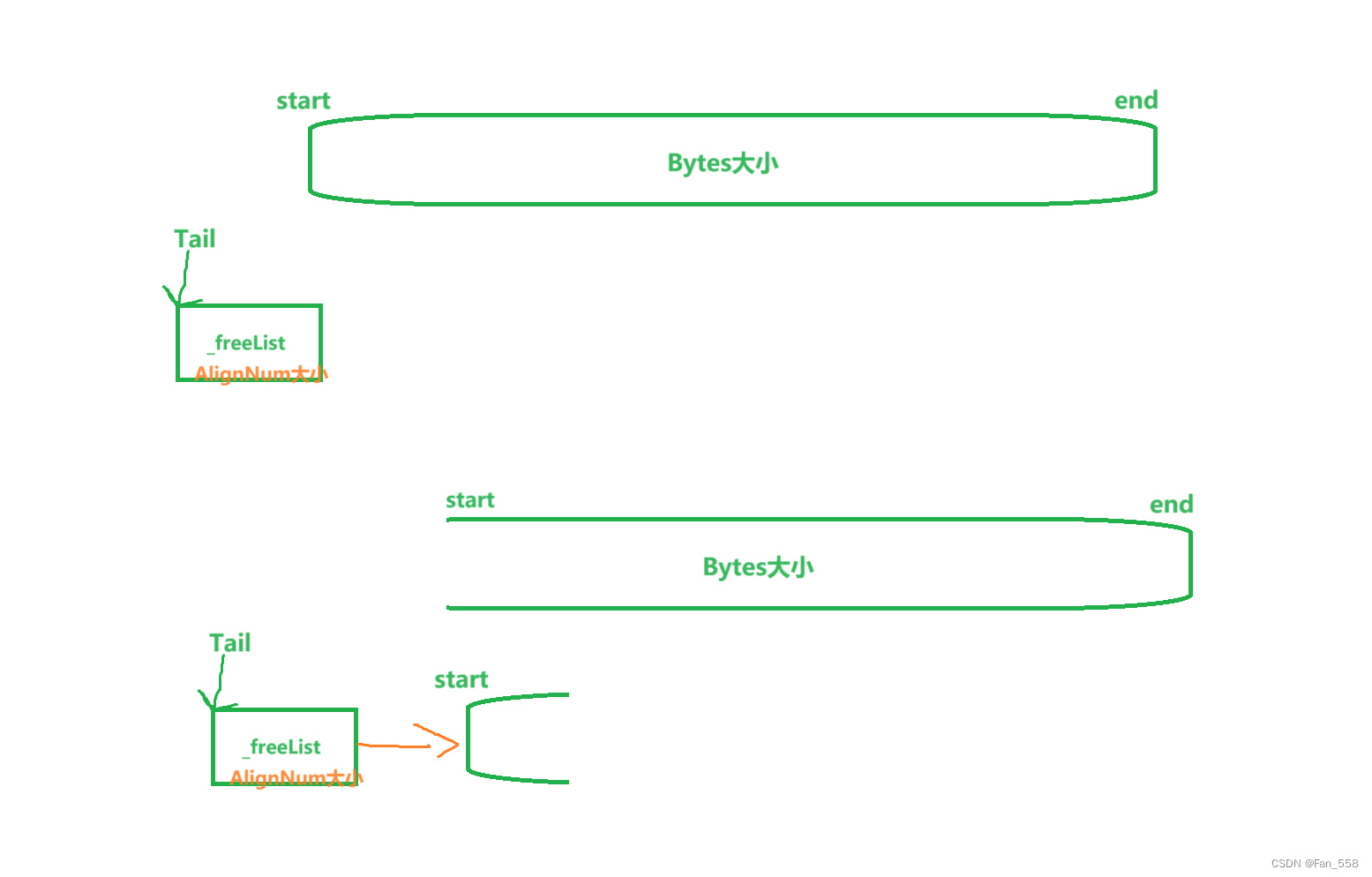
5、最后将一大块从PageCache申请到的内存且切好的自由链表挂在CentralCache对应的桶中
根据需求修改SpanList结构
//带头双向循环链表
class SpanList
{
public://初始化双向链表SpanList(){//初始化头节点_head = new Span;_head->_next = _head;_head->_prev = _head;}//头插void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}//头删void Erase(Span* pos){assert(pos);Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;//不需要真正delete该pos处的span,可能需要还给pagecache}Span* Begin(){return _head->_next;}Span* End(){return _head;}//头插void PushFront(Span* span){Insert(Begin(), span);}//头删Span* PopFront(){Span* front = _head->_next;Erase(front);return front;}bool Empty(){return _head->_next == _head;}
private:Span* _head;
public:std::mutex _mtx; //桶锁
};
获取一个非空的span:整体代码
//获取一个非空的span
Span* CentralCache::GetoneSpan(SpanList& list, size_t AlignNum)
{//从list中取出一个非空的span,遍历Span* it = list.Begin();while (it != list.End()){//存在非空的span就返回if (it->_freeList != nullptr){return it;}else it = it->_next;}//将centralcache的桶锁解开,这样如果其它线程释放内存对象回来,就不会阻塞了list._mtx.unlock();//没有非空的span,向PageCache中申请PageCache::GetInstance()->_pageMutex.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(AlignNum));PageCache::GetInstance()->_pageMutex.unlock();//这里不需要立刻立刻将该线程的桶锁给续上呢,不用,因为只有此线程是拿到这个span的,其它线程没有//计算大块内存的起始地址以及字节数char* start = (char*)(span->_pageId << PAGE_SHIFT); //起始地址size_t Bytes = span->_n << PAGE_SHIFT;char* end = start + Bytes;//将一大块从PageCache中申请的内存切分成由一个span指向的自由链表span->_freeList = start;start += AlignNum;void* tail = span->_freeList;while (start < end){FreeList::NextObj(tail) = start;tail = start;start += AlignNum;}list._mtx.lock();//将span挂到桶里面去list.PushFront(span);return span;
}二、NewSpan模块:
将转化好的需要申请的页数传参给NewSpan
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(AlignNum));
将申请的字节数转化为页数,不足一页给一页
static size_t NumMovePage(size_t size){size_t num = NumMoveSize(size);size_t npage = num * size;npage >>= PAGE_SHIFT;if (npage == 0)npage = 1;return npage;}
NewsSpan:从PageCache中获取一个n页的span
1、首先查看对应页数(K)的桶中是否存在span,如果存在直接返回,若不存在,遍历整个PageCache结构中K之后的桶中是否存在非空的span,如果有直接返回,如果都没有,只能向堆进行申请一个128Page大小的内存span
2、然后将申请的内存起始地址转换成页号_pageId,_n赋值成页数的大小即128,最后将128Page大小的span挂到对应的桶中
newBigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;newBigSpan->_n = NPAGES - 1;//在pagecache对应的桶中插入刚申请的内存span_spanLists[newBigSpan->_n].PushFront(newBigSpan);
3、最后复用自己,这时遍历K以后桶的时候,遍历到第128个桶时,就获取到了span,然后将128-K页重新找对应的桶挂起来,返回K页内存大小的span
//复用自己,重新进行切分return NewSpan(K);
//在pagecache中获取一个n页的span
Span* PageCache::NewSpan(size_t K)
{std::cout << K << std::endl;assert(K > 0 && K < NPAGES);//检查pagecache第K个桶是否有spanif (!_spanLists[K].Empty()){return _spanLists[K].PopFront();}//查看第K个桶的后面的桶是否有span(K+1:跳过当前没有span的桶)for (size_t i = K + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){//切分spanSpan* Nspan = _spanLists[i].PopFront();Span* Kspan = new Span;//起始页号Kspan->_pageId = Nspan->_pageId;//页数Kspan->_n = K;Nspan->_pageId += K;Nspan->_n -= K;//将切分剩下的页缓存重新挂起来_spanLists[Nspan->_n].PushFront(Nspan);return Kspan;}}//其余桶为空,此时向(堆)系统申请一个128Page的内存块Span* newBigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);newBigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;newBigSpan->_n = NPAGES - 1;//在pagecache对应的桶中插入刚申请的内存span_spanLists[newBigSpan->_n].PushFront(newBigSpan);//复用自己,重新进行切分return NewSpan(K);
}小结
今日的项目分享就到这里啦,三层申请内存的结构终于完成啦,下期预告:测试三层内存架构,欢迎交流学习~
如果本文存在疏漏或错误的地方,还请您能够指出!
这篇关于006 高并发内存池_PageCache设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



