本文主要是介绍音视频开发之旅(80)- AI数字人-腾讯开源AniPortrait-音频驱动的肖像动画,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、前言
2、效果展示
3、原理学习
4、遇到的问题与解决方案
5、资料
一、前言
一个月前阿里Emo发布,通过音频驱动的非常自然的肖像视频,引起很大反响。具体看下面的视频,但是并没有开源其代码。
这两天腾讯开源了其音频驱动的肖像视频的项目AniPortrait,它也实现了类似功能:音频驱动、参考视频表情动作驱动,或者通过预先生成的pose关键点视频来驱动。
AniPortrait开发者在EMO的issue上留言,哈哈
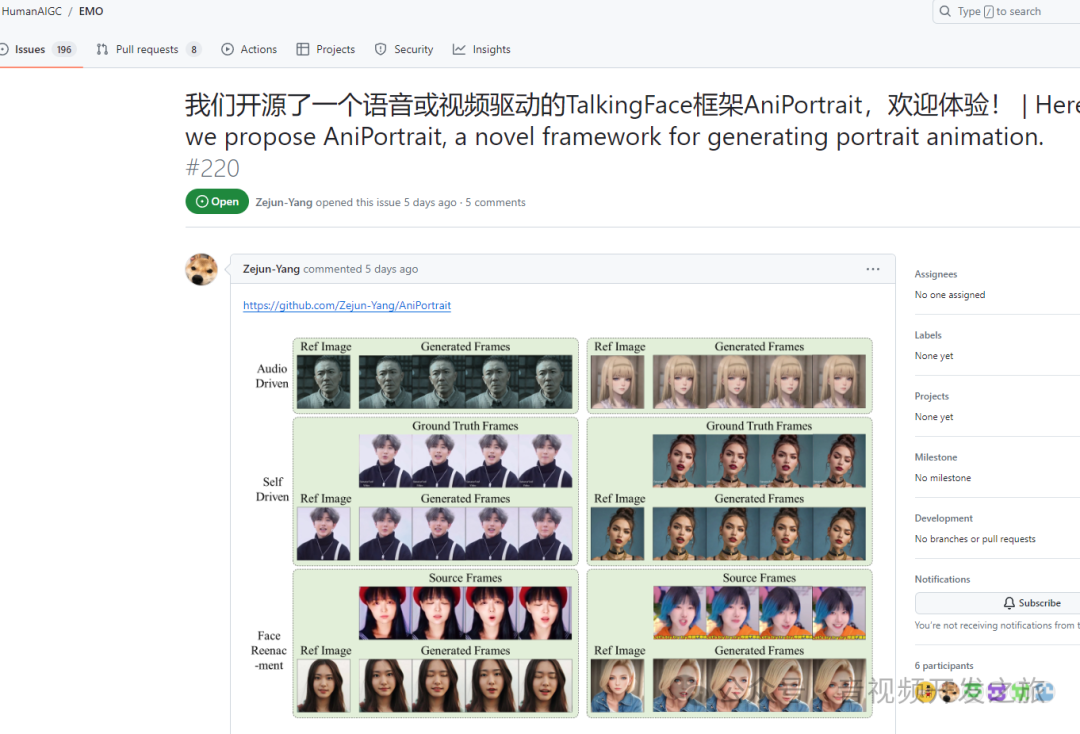
二、效果展示
效果来看和EMO差距还是蛮大,主要是唇形不自然,官方给出的效果就可用看出唇形特别是牙齿的问题。当使用自己的素材生成时,问题更明显
2.1 官方展示效果
Aragaki
lyl
2.2 自己使用效果
Aragaki
sd
solo
三、原理学习
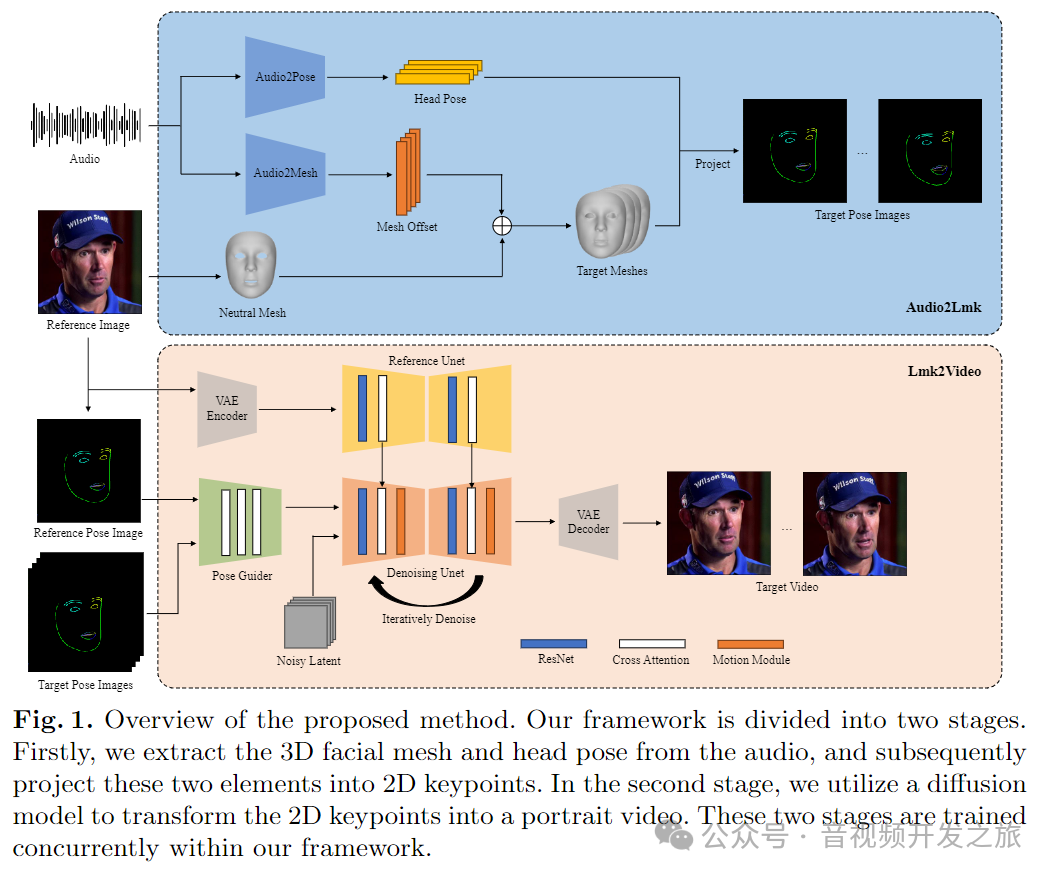
分为两个阶段:从音频提取关键点信息和从关键点信息生成视频
音频处理阶段(Audio2Lmk)
在这个阶段,系统首先解析音频信号,以抓取驱动动态人脸模型的关键数据。
-
音频输入: 包含人声的音频片段
-
Audio2Pose: 从音频中提取头部姿势信息
-
Audio2Mesh: 从音频中提取面部网格的变形信息(面部表情变化)
4. Neutral Mesh: 标准的没有任何表情的基础3D面部模型
5. Mesh Offset: 结合音频提取的信息,生成表达特定情绪或语音的目标面部模型。
6. Target Meshes: 经过偏移和调整后得到的一系列面部模型,它们将用来产生动画中人物的表情。
7. Project: 将复杂的3D面部数据转换为2D平面上的点集,为下一步的视频生成做准备。
视频生成阶段(Lmk2Video)
经过第一阶段的处理,得到了可以描述面部动态的2D关键点。在第二阶段,这些关键点将被用于生成最终的视频。
-
Reference Image: 提供一个参考帧,通常是一张静态的、人物正面的照片。
-
Reference Pose Image: 参考图像中人物姿势的一个标准表示,用于帮助系统理解参考帧中的人物姿势。
-
Denoising Unet:用于去除编码的潜在表示中的噪声,确保生成的图像尽可能清晰。
-
VAE Decoder:将去噪后的潜在表示解码成2D图像,反映了目标视频帧的姿势。
-
Motion Module:负责生成连续、平滑的面部运动,以创建逼真的视频。
四、遇到的问题与解决方案
1. audio2vid嘴唇动得太快 https://github.com/Zejun-Yang/AniPortrait/issues/7
可以在之后对预网格应用平滑AniPortrait/scripts/audio2vid.pyLine 155 in bfa1574pred = pred + face_result['lmks3d'], similar to what is done at,类似于在AniPortrait/scripts/generate_ref_pose.pyLine 85 in bfa1574pose_arr_smooth = smooth_pose_seq(pose_arr_interp)
2. video2video,源video需要和ref_image对齐吗?https://github.com/Zejun-Yang/AniPortrait/issues/27
将参考图片和参考视频处理成半身肖像的形式,尺寸作为正方形即可。可以参照demo中的样式,不需要严格对齐图片和视频的头部位置。3. Audio driven 可以生成独立的视频吗?https://github.com/Zejun-Yang/AniPortrait/issues/48
目前audio2video方法生成30fps的视频时口型较准确。您无需调整L参数大小,生成视频后使用其他补帧方法提升到60fps即可。需要更高清视频也可以使用其他视频超分方法进行后处理,如果算力有余量,也可以尝试修改指令为-W 768 -H 768。另外,如果需要去掉输出结果中的pose video,对audio2video.py文件作出如下修改:AniPortrait/scripts/audio2vid.pyLine 210 in 415eb04video = torch.cat([ref_image_tensor, pose_tensor, video], dim=0)--》video = torch.cat([ref_image_tensor, video], dim=0)
4. 音频驱动的视频图像闪烁 https://github.com/Zejun-Yang/AniPortrait/issues/20
闪烁问题可能归因于扩散模型,我们正在积极努力在未来解决这个问题。FreeNoise 可以减少闪烁。只需使用时域中值滤波器再次将其传递给 FFMPEG:ffmpeg.exe -i .\input.mp4 -filter:v "tmedian=3" output.mp4这将显着减少闪烁
5.Face reenacment inference error:RuntimeError: CUDA error: device-side assert triggered https://github.com/Zejun-Yang/AniPortrait/issues/42
RuntimeError: CUDA error: device-side assert triggeredCUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.For debugging consider passing CUDA_LAUNCH_BLOCKING=1.Compile with TORCH_USE_CUDA_DSA to enable device-side assertions
解决方案:
更改视频路径并重试它应该在配置文件中起作用。`pretrained_base_model_path: './pretrained_model/stable-diffusion-v1-5'pretrained_vae_path: './pretrained_model/sd-vae-ft-mse'image_encoder_path: './pretrained_model/image_encoder'denoising_unet_path: "./pretrained_model/denoising_unet.pth"reference_unet_path: "./pretrained_model/reference_unet.pth"pose_guider_path: "./pretrained_model/pose_guider.pth"motion_module_path: "./pretrained_model/motion_module.pth"inference_config: "./configs/inference/inference_v2.yaml"weight_dtype: 'fp16'test_cases:"./configs/inference/ref_images/Aragaki.png":- "./configs/inference/head_pose_temp/pose_ref_video.mp4"`
五、资料
1、项目:https://github.com/Zejun-Yang/AniPortrait
2、论文:https://arxiv.org/pdf/2403.17694.pdf
感谢你的阅读
接下来我们继续学习输出AIGC相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流
这篇关于音视频开发之旅(80)- AI数字人-腾讯开源AniPortrait-音频驱动的肖像动画的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








