本文主要是介绍探索C语言中的联合体和枚举:让处理数据更加得心应手,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✨✨小新课堂开课了,欢迎欢迎~✨✨
🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:http://t.csdnimg.cn/Oytke
小新的主页:编程版小新-CSDN博客

C语言中有内置类型, 比如:int ,char,short ,double,float等,但是仅用这些是不方便使用的,此次有了自定义类型,给了程序员更大的权力,以更好的追求性能。联合体能够将不同的类型聚在一起,放在一个共同的空间里,仿佛一损俱损,一荣俱荣。而枚举类型的使用仿佛更加的贴近生活,比如表述一个星期有七天,一年有12个月等。用枚举来写,增加代码的可读性和可维护性。
一:联合体类型
1.联合体的定义
像结构体⼀样,联合体也是由一个或者多个成员构成,这些成员可以是不同的类型。但是编译器只为最大的成员分配足够的内存空间。
联合体的特点是所有成员共用同一块内存空间。所以联合体也叫:共用体。
给联合体其中⼀个成员赋值,其他成员的值也跟着变化。
2.联合体的声明
union un // 联合体关键字union+tag 标签
{
int i;
char c; // variable-name 联合体成员
float f;
} a,b,c; // variable-list 变量列表
(1) 普通联合体
union un
{int i;char c;float f;
};
(2)嵌套联合体
//嵌套联合体
union u1
{int arr[4];float f;
};union un
{int i;char c;union u1 u;
};(3)匿名联合体
//匿名联合体
union
{char s;int b;float f;
};小新:匿名联合体是一种比较特殊的联合体,匿名联合体顾名思义就是省略了它的名字,也就是所谓的tag-标签。匿名联合体只能使用一次,下次再要使用的时候,它已经不在了,这点要注意。
(4)typedef重命名的联合体
//typedef重命名的联合体
typedef union un
{int i;char str[4];
};3.联合体变量的创建和初始化
//联合体变量的创建和初始化
union un
{int i;char c;
};int main()
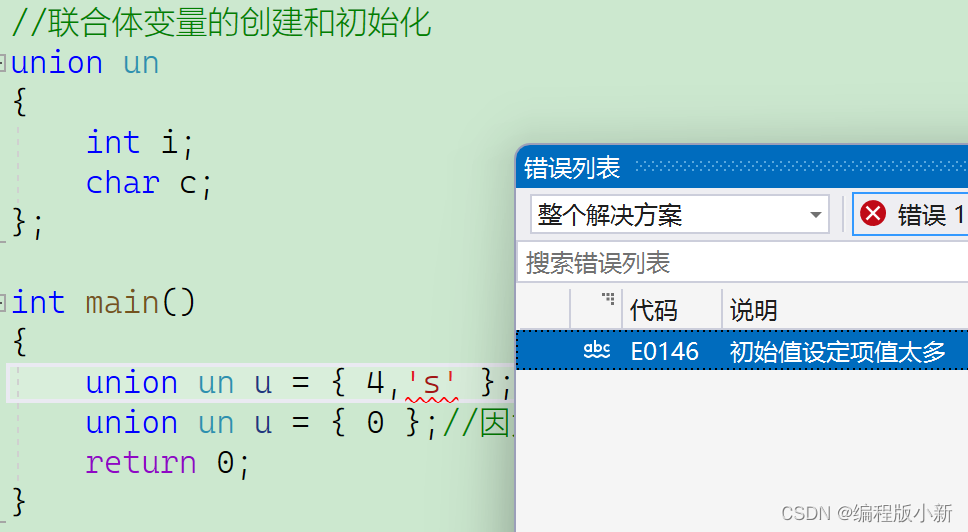
{//union un u = { 4,'s' }; //与结构体不同,这样初始化是错误的union un u = { 0 };//因为结构体成员公用一块内存区域,使用在初始化的时候只能初始化一个值return 0;
}
4.联合体的访问
联合体可以通过成员访问运算符(.)来访问其成员。与结构体相同,可以使用联合体变量和指向联合体的指针来访问成员。
#include<stdio.h>
#include<string.h>
union un
{int i;char c[10];
};int main()
{union un u = { 0 };printf("%d ", u.i);strcpy(u.c, "xiaoxin");printf("%s ",u.c );return 0;
}运行结果:

5.联合体的特点
联合的成员是共用同⼀块内存空间的,这样⼀个联合变量的大小,至少是最大成员的大小(因为联合 至少得有能力保存最大的那个成员)。
#include<stdio.h>
union Un
{char c;int i;
};int main()
{union Un un = { 0 };// 下⾯输出的结果是⼀样的吗? printf("%p\n", &(un.i));printf("%p\n", &(un.c));printf("%p\n", &un);return 0;
}运行结果:

由此可见,他们确实是共用一块内存。
#include<stdio.h>
union Un
{char c;int i;
};
int main()
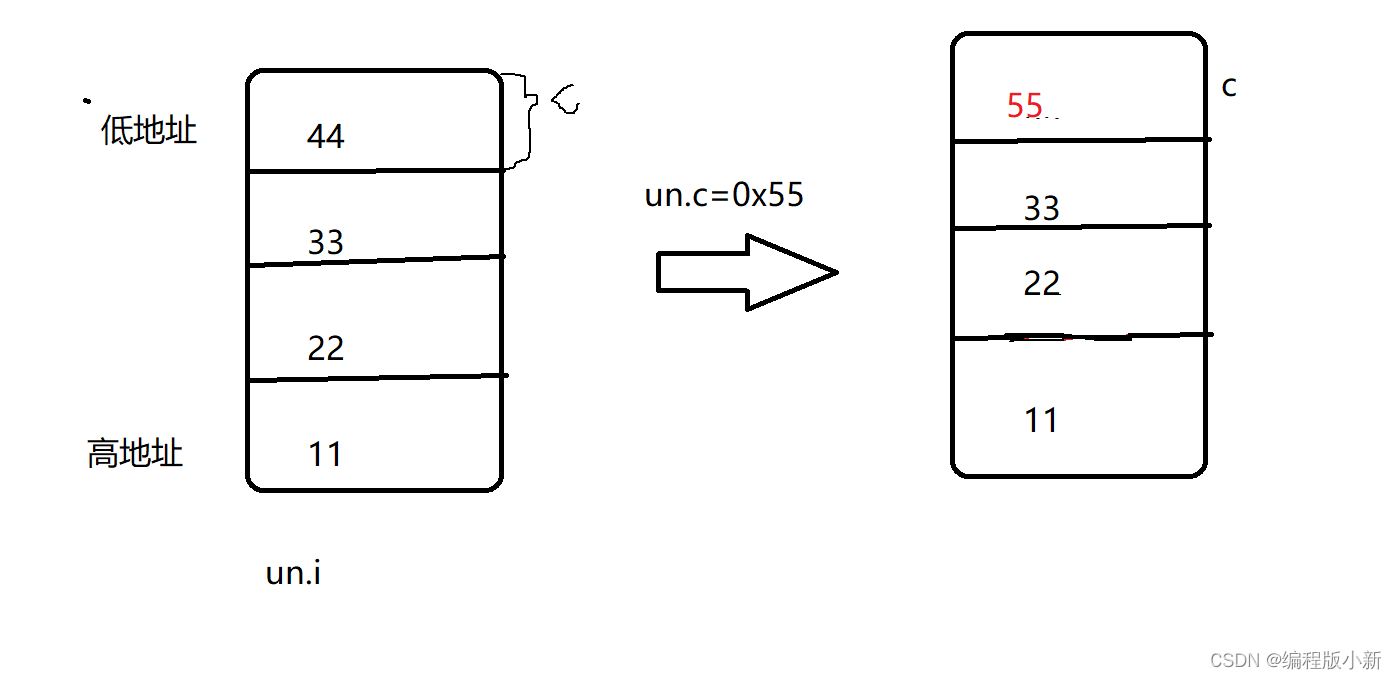
{union Un un = { 0 };un.i = 0x11223344;un.c = 0x55;printf("%x\n", un.i);return 0;
}运行结果:

用画图的方式来解释就是这样的。
6.联合体大小的计算
联合体在计算大小的时候和结构体一样,遵循着某种规则。
什么规则呢,如下:
• 联合的大小至少是最大成员的大小。
• 当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
示例1:
#include<stdio.h>
union Un1
{char c[5];int i;
};
union Un2
{short c[7];int i;
};
int main()
{//下⾯输出的结果是什么? printf("%d\n", sizeof(union Un1));//printf("%d\n", sizeof(union Un2));return 0;
}运行结果:

VS默认的最大对齐数是8,Un1的最大成员的大小是5,不是最大对齐数的整数倍,最终改为8;
Un2的最大成员的大小是14,不是最大对齐数的整数倍,最终改为16。
7.联合体的应用
使用联合体是可以节省空间的,举例:
比如,我们要搞⼀个活动,要上线⼀个礼品兑换单,礼品兑换单中有三种商品:图书、杯⼦、衬衫。 每⼀种商品都有:库存量、价格、商品类型和商品类型相关的其他信息。
图书:书名、作者、页数
杯子:设计
衬衫:设计、可选颜⾊、可选尺⼨
那我们不耐心思考,直接写出⼀下结构:
struct gift_list
{//公共属性 int stock_number;//库存量 double price; //定价 int item_type;//商品类型 //特殊属性 char title[20];//书名 char author[20];//作者 int num_pages;//⻚数 char design[30];//设计 int colors;//颜⾊ int sizes;//尺⼨
};
上述的结构其实设计的很简单,用起来也方便,但是结构的设计中包含了所有礼品的各种属性,这样 使得结构体的大小就会偏大,比较浪费内存。因为对于礼品兑换单中的商品来说,只有部分属性信息是常用的。
比如: 商品是图书,就不需要design、colors、sizes。 所以我们就可以把公共属性单独写出来,剩余属于各种商品本身的属性使用联合体,这样就可以减少所需的内存空间,⼀定程度上节省了内存。
struct gift_list
{int stock_number;//库存量 double price; //定价 int item_type;//商品类型 union
{struct //匿名结构体{char title[20];//书名 char author[20];//作者 int num_pages;//⻚数 }book;struct //匿名结构体{char design[30];//设计 }mug;struct //匿名结构体{char design[30];//设计 int colors;//颜⾊ int sizes;//尺⼨ }shirt;}item;};8.用联合体判断大小端
int check_sys()
{union{int i;char c;}un;un.i = 1;//00 00 00 01return un.c;//返回1是⼩端,返回0是⼤端
}二:枚举类型
1.枚举类型的定义
枚举是一种特殊的数据类型,用于定义一组有限的命名常量,这些命名常量又被称为枚举常量,它提供了一种简洁,可读性更高的方式来表示这些常量,并且通常具有类型安全性和可扩展性。
在实际应用中我们经常把能够且便于一一列举的类型用枚举来表示。
2.枚举的声明
enum 枚举类型名
{
标识符1,
标识符2,
...
};
(1) 普通枚举
enum un
{MON=1, //指定从1开始,否则默认从0开始TUE,WED,THU, FRI, SAT, SUN
};(2)匿名枚举
//匿名枚举
enum
{MON = 1, //指定从1开始,否则默认从0开始TUE,WED,THU,FRI, SAT,SUN
};(3)typedef重命名的枚举
typedef enum day
{MON = 1, //指定从1开始,否则默认从0开始TUE,WED,THU,FRI,SAT,SUN
};3.枚举的特点
小新:我们用一些例子来说明它的特点吧
#iclude<stdio.h>
enum un
{MON, TUE,WED,THU,FRI,SAT,SUN
};int main()
{for (int i = MON; i <= SUN; i++){printf("%d ", i);}return 0;
}运行结果:

{ }中的内容是枚举类型的可能取值,也叫枚举常量 。这些可能取值都是有值的,默认从0开始,依次递增1,当然在声明枚举类型的时候也可以赋初值
有请下一个例子登场
#include<stdio.h>
enum un
{red = 2,green,yellow,pink = 7,black,blue
};int main()
{printf("red = %d ",red);printf("green = %d ", green);printf("yellow = %d ", yellow);printf("pink = %d ", pink);printf("black= %d ", black);printf("blue = %d ", blue);return 0;
}运行结果:

也可以通过这种赋值的方式改变取值
4.枚举常量的创建和初始化
我们通常是用枚举常量来给枚举变量赋值的,在C语言中也可以用整数给枚举变量赋值,但是在C++中不能,C++要求的更加严格一些。
#include<stdio.h>
typedef enum un
{MON, TUE,WED,THU,FRI,SAT,SUM
}un;int main()
{un u = MON;//最好用枚举常量进行赋值return 0;
}5.枚举类型的大小
枚举类型的大小和int的大小相等,都是4个字节,不信的话,小新就来证明一下。
#include<stdio.h>
enum day
{MON, TUE,WED,THU,FRI,SAT,SUN
};enum color
{red,blue,yellow,green
};int main()
{printf("%zd\n", sizeof(enum day));printf("%zd\n", sizeof(enum color));return 0;
}运行结果:

6.枚举类型的优点
为什么使用枚举? 我们可以使用 #define 定义常量,为什么非要使用枚举?
枚举的优点:
1. 增加代码的可读性和可维护性
2. 和#define定义的标识符比较,枚举有类型检查,更加严谨。
3. 便于调试,预处理阶段会删除 #define 定义的符号
4. 使用方便,⼀次可以定义多个常量
5. 枚举常量是遵循作用域规则的,枚举声明在函数内,只能在函数内使用
7.枚举的应用
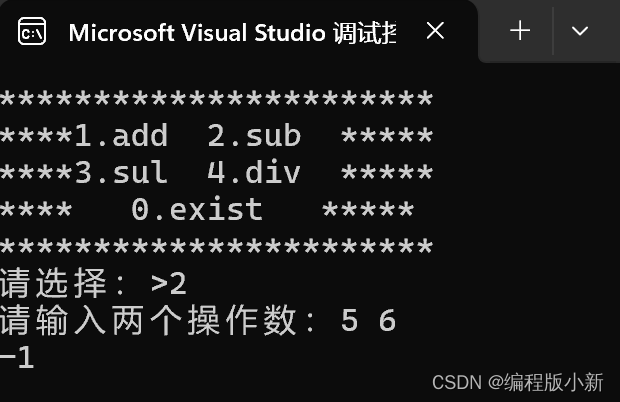
计算器的实现有多种方法,今天我们用枚举来实现计算器
运行结果:
下课了下课了~
下次还要来上课哦~

这篇关于探索C语言中的联合体和枚举:让处理数据更加得心应手的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





