本文主要是介绍# Apache SeaTunnel 究竟是什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者 | Shawn Gordon
翻译 | Debra Chen
原文链接 | What the Heck is Apache SeaTunnel?
我在2023年初开始注意到Apache SeaTunnel的相关讨论,一直低调地关注着。该项目始于2017年,最初名为Waterdrop,在Apache DolphinScheduler的创建者的贡献下发展起来,后者支持SeaTunnel作为任务插件。
我最初对于SeaTunnel是什么以及为什么我会关心它感到困惑。这意味着我将在至少能回答我的这些问题的层面上,对Apache SeaTunnel有一个深度的介绍。那么,让我们开始吧。
什么是SeaTunnel?
Apache SeaTunnel的项目介绍是“一个高性能的、分布式的、大规模数据集成工具,提供了异构数据集成和数据同步的一体化解决方案。”它包括三个主要组件:
- 源连接器
- 转换连接器
- 目标连接器
许多源连接器(Connector)可供选择;在版本2.3.3中,可用的连接器如链接所示。它支持包括关系型、NoSQL和图形等格式,以及分布式文件系统(如HDFS)和对象存储(如S3)等。
如果源和目标之间的格式不同,则转换连接器(Transform Tonnector)会发挥作用,实质上它就是对数据进行映射。
目标连接器(Sink)是源的另一侧,但现在你是在写入数据而不是读取。截至本文撰写时,SeaTunnel声明已支持超过100个连接器。
有了这些组件,SeaTunnel可以解决数据集成和同步中常见的问题。因此,它提供了实时和批处理数据的高性能数据同步。文章称它可以“实时同步数十亿数据量”。虽然我不确定是什么意思,但考虑到像阿里巴巴这样的公司在使用它,它的速度可能非常快。
SeaTunnel的特性
我对系统中的连接器API功能印象深刻。正如前面所述,Apache SeaTunnel已有超过100个预先构建的连接器,但如果需要其他连接器,你可以创建自己的连接器。这些连接器不与特定的执行引擎绑定,而可以使用Flink、Spark或本地的SeaTunnel引擎。连接器的插件架构让我想起了Trino的生态系统。
数据可以以批处理或实时方式同步,并提供了各种同步选项。SeaTunnel一个很棒的特性是它可以与JDBC已配合工作,支持多表或整个数据库的同步。这就解决了CDC多表同步方案的需求。
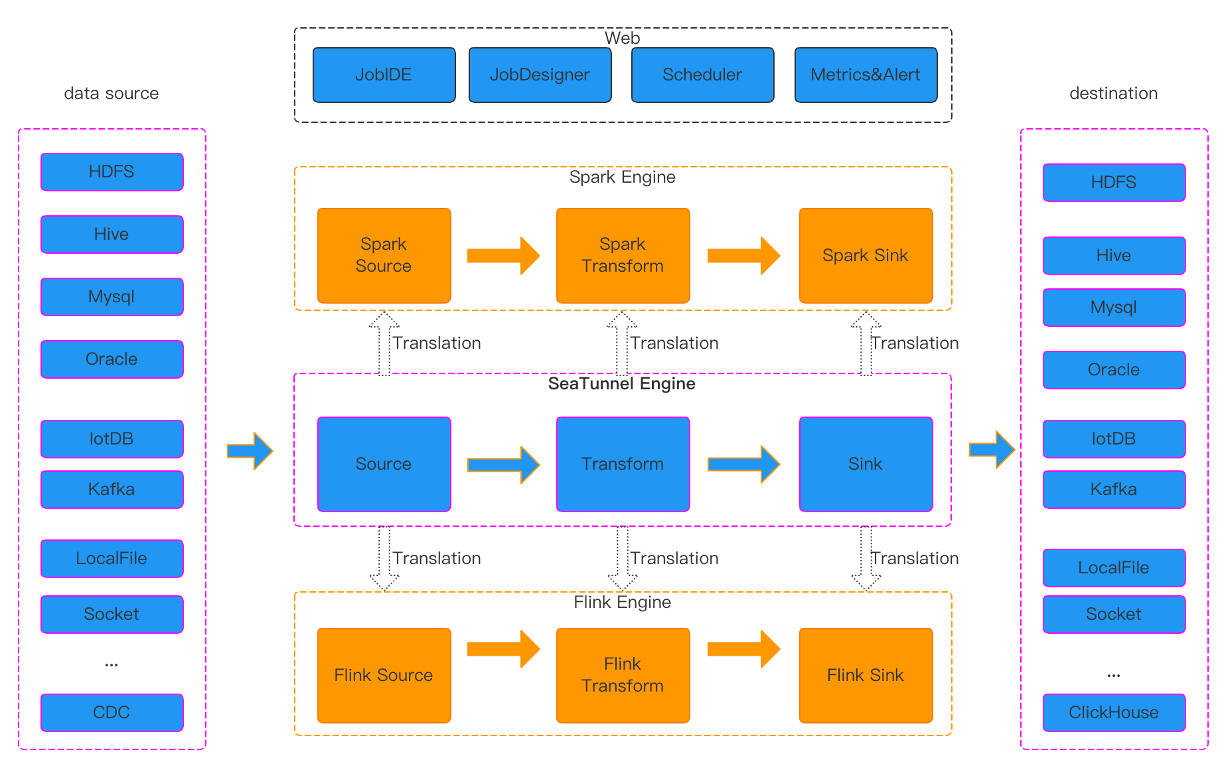
SeaTunnel的运行时流程如下所示:
- 配置作业信息并选择执行引擎。
- 源连接器并行读取数据,并将其传递到转换器、目标连接器或直接传递到目标。
请记住,SeaTunnel是一个EL(T)集成平台,因此它只能自行进行基本的数据转换:
- 更改列中的数据大小写
- 更改列名
- 将一列拆分为多列
SeaTunnel job
SeaTunnel job,或配置文件可能由四个部分组成:env、source、transform和sink。如果不执行转换,则可以忽略transform部分。配置文件可以采用hocon或json格式编写。从SeaTunnel文档中借鉴,以下是hocon格式的简单示例:
Copy code
env {job.mode = "BATCH"
}
source {FakeSource {result_table_name = "fake"row.num = 100schema = {fields {name = "string"age = "int"card = "int"}}}
}
transform {Filter {source_table_name = "fake"result_table_name = "fake1"fields = [name, card]}
}
sink {Clickhouse {host = "clickhouse:8123"database = "default"table = "seatunnel_console"fields = ["name", "card"]username = "default"password = ""source_table_name = "fake1"}
}虽然格式非常易于阅读和理解,但我可以看出,对于大型表格,它可能会变得相当复杂。我要在此评论一下,就像许多开源项目一样,SeaTunnel的文档相当缺乏,但据我观察的时间,该项目似乎有一个相当活跃的Slack频道。
SeaTunnel使用要求
它是一个Java系统,支持Java 8或Java 11版本,但应该与较旧的系统兼容。如果你已经安装了Java,则只需从其网站获取所需的插件(或编写自己的插件),并在配置文件中进行设置。之后,按照上文所述创建用于管理作业的配置文件。只要你有访问源和目标数据存储库的凭据,控制台就会提供反馈信息。
Apache SeaTunnel还提供了Web界面,供那些想要替代CLI的用户选择。这将是我个人使用这个系统的首选方式,因为它的可视性更好,但安装和使用也需要更多的步骤。
总结
SeaTunnel显然适用于某些场景,就我目前所看到的情况而言,在处理各种数据源和目标的大量数据时,它才会发挥作用。我完全可以预见,SeaTunnel还将在很多场景中让事情变得更简单,所以我会把这个项目放在我的工具箱里。SeaTunnel团队提供了一个很好的快速入门指南,帮助用户可以轻松地自行尝试,看看它是否能解决你的问题吧!
本文由 白鲸开源科技 提供发布支持!
这篇关于# Apache SeaTunnel 究竟是什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







