本文主要是介绍ForkJoinPool、CAS原子操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ForkJoinPool
ForkJoinPool是由JDK1.7后提供多线程并行执行任务的框架。可以理解为一种特殊的线程池。
1.任务分割:Fork(分岔),先把大的任务分割成足够小的子任务,如果子任务比较大的话还要对子任务进行继续分割。
2.合并结果:join,分割后的子任务被多个线程执行后,再合并结果,得到最终的完整输出。

类似于分治的思想,把大任务一点点拆分为一个个小任务。
如果要统计1~100之间的和,当然可以直接暴力for循环,不过也可以把它拆分为10个任务,计算1到10的和,11到20的和…
- ForkJoinTask:主要提供fork和join两个方法用于任务拆分与合并;一般用子类 RecursiveAction(无返回值的任务)和RecursiveTask(需要返回值)来实现compute方法。

public abstract class ForkJoinTask<V> implements Future<V>, Serializable
可以看到,ForkJoinTask实现了Future这个接口,也就是说,我们也可以通过ForkJoinTask来获取线程的状态、结果等。
- ForkJoinPool:调度ForkJoinTask的线程池;
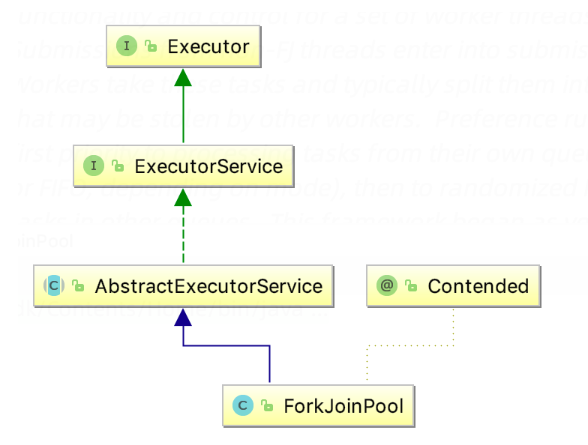
- ForkJoinWorkerThread:Thread的子类,存放于线程池中的工作线程(Worker);
- WorkQueue:任务队列,用于保存任务;
ForkJoinPool forkJoinPool=new ForkJoinPool(8);//最多拆分为8个线程java.util.concurrent.ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(new ForkJoinTask(1, 100));System.out.println(forkJoinTask.get());static class ForkJoinTask extends RecursiveTask<Integer>{int start;int end;public ForkJoinTask(int start, int end) {this.start = start;this.end = end;}@Overrideprotected Integer compute() {if((end-start)<=10){int count=0;for(int i=start;i<=end;i++){count+=i;}System.out.println("当前线程为:"+Thread.currentThread().getName());return count;}else{int mid=start+end>>1;ForkJoinTask subTask1=new ForkJoinTask(start,mid);subTask1.fork();ForkJoinTask subTask2=new ForkJoinTask(mid+1,end);subTask2.fork();return subTask1.join()+subTask2.join();}}}
计算1~100的和,如果end-start小于等于10就直接暴力进行加法运算,如果大于10,就继续拆分。
ForkJoinPool的设计思想

- 普通线程池内部有两个重要集合:工作线程集合(普通线程),和任务队列。
- ForkJoinPool也类似,线程集合里放的是特殊线程ForkJoinWorkerThread,任务队列里放的是特殊任务ForkJoinTask
- 不同之处在于,普通线程池只有一个队列。而ForkJoinPool的工作线程ForkJoinWorkerThread每个线程内都绑定一个双端队列。
- 在fork的时候,也就是任务拆分,将拆分的task会被当前线程放到自己的队列中。
- 如果有任务,那么线程优先从自己的队列里取任务执行,以
LIFO先进后出方式从队尾获取任务, - 当自己队列中执行完后,工作线程会跑到其他队列以
work−stealing窃取,窃取方式为FIFO先进先出,减少竞争。

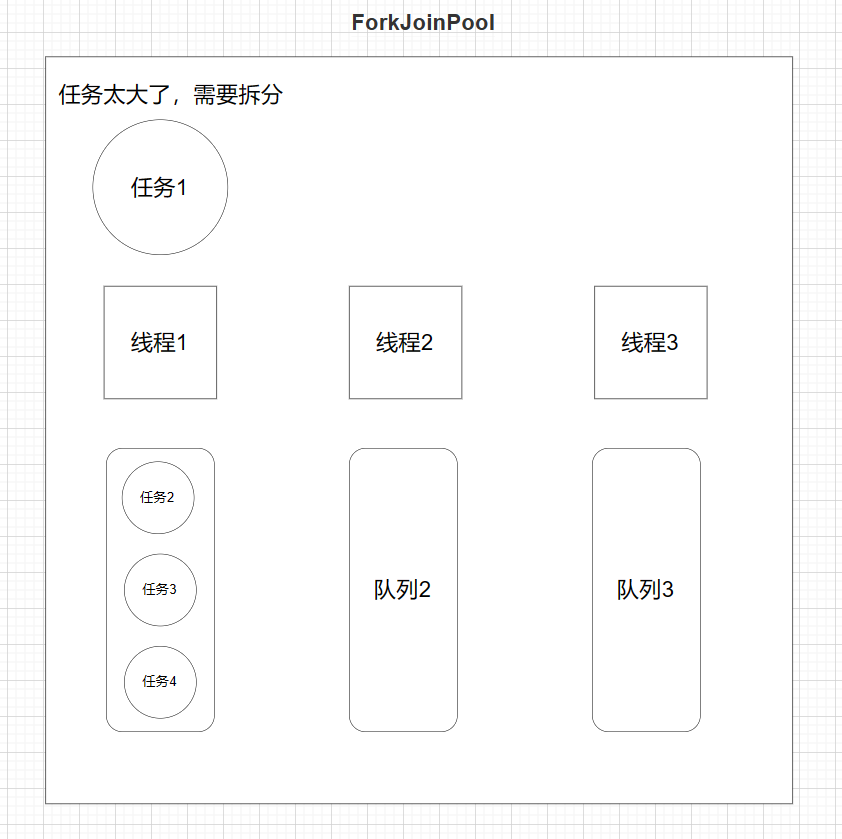
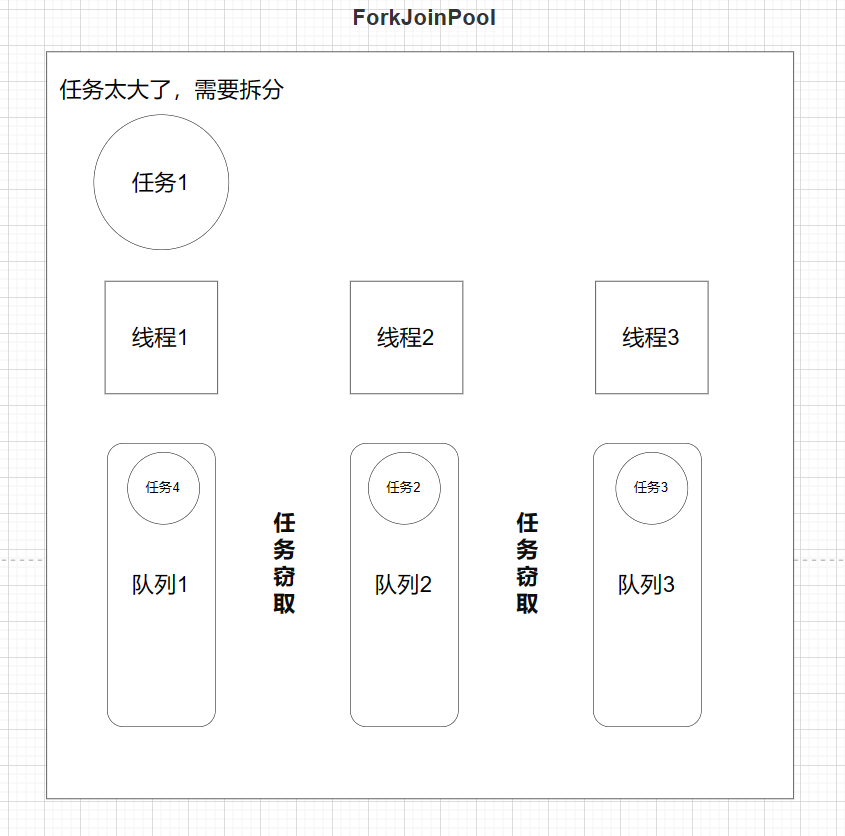
- 任务拆分:线程首先将大任务拆分成更小的任务。
- 本地队列:拆分出的小任务通常会被放置在执行这个任务的线程的本地队列中。这个队列是一个双端队列(deque)。
- 任务窃取:其他闲置的线程可以从这个队列的另一端窃取任务来执行。这意味着,虽然拆分出的任务最初是放在原线程的队列中,但其他线程可以参与处理这些任务。
- 负载均衡:通过这种方式,
ForkJoinPool试图在其所有线程之间实现负载均衡,从而提高效率。
举例:
假设你有一个大任务:计算从1加到10000的总和。这个任务可以通过拆分成更小的任务来并行处理。
- 任务拆分:线程A开始执行这个任务,它决定将任务拆分成两个更小的任务:第一个是计算1到5000的总和,第二个是计算5001到10000的总和。
- 放置在本地队列:线程A将这两个任务放入它的本地队列。此时,它开始执行其中一个任务(比如计算1到5000的总和)。
- 工作窃取:此时,另一个线程B处于空闲状态,它会查看线程A的队列。线程B发现队列中有待处理的任务(计算5001到10000的总和),于是它将这个任务从队列中窃取并开始执行。
- 并行处理:线程A和线程B现在都在执行一个较小的任务。一旦各自的任务完成,结果会被汇总。在这个例子中,两个任务的结果将被加在一起以得到最终的总和。
注意点
使用ForkJoin将相同的计算任务通过多线程执行。但是在使用中需要注意:
- 注意任务切分的粒度,也就是fork的界限。并非越小越好
- 判断要不要使用ForkJoin。任务量不是太大的话,串行可能优于并行。因为多线程会涉及到上下文的切换
CAS(比较交换)原子操作
在说CAS之前先说一下什么是原子操作
原子(atom)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为"不可被中断的一个或一系列操作" 。
CAS(Compare-and-Swap/Exchange),即比较并替换,是一种实现并发常用到的技术。CAS的整体架构如下:

- 初始状态:计数器的值为0。
- 线程A 读取计数器的值,得到0,打算将其增加到1。
- 线程B 也读取计数器的值,得到0,同样打算将其增加到1。
此时,假设两个线程都尝试执行CAS操作来更新计数器的值。
理想的CAS操作:
- 线程A 的CAS操作先执行,它比较当前计数器的值(0)与预期值(0),发现匹配,因此成功将计数器的值更新为1。
- 接着,线程B 尝试执行它的CAS操作。这时,它比较当前计数器的值(现在为1)与其预期值(0),发现不匹配,因此不执行更新。
在这个情况下,计数器的最终值是1,这是正确的结果。每个线程都试图将计数器增加1,但只有一个线程成功了,因为CAS操作确保了计数器的每次更新都是基于最新的、有效的值。
如果CAS不按预期行为:
假设当线程B的预期值不匹配时,CAS操作仍然执行了更改,将计数器从1增加到2。
这将导致以下问题:
- 数据不一致:这意味着两个线程的操作都基于同一个旧值(0),从而错误地假定计数器未被其他线程更改。
- 结果错误:最终计数器的值变为2,而实际上只应该被增加1次。这是因为线程B没有正确地检测到线程A已经更新了计数器。
public class TestAtomic {public static void main(String[] args) {AtomicInteger atomicInteger=new AtomicInteger(1);atomicInteger.addAndGet(1);atomicInteger.incrementAndGet();}
}
以上两种方法都是给当前值+1,addAndGet(1)表示是在当前值的基础上+1,incrementAndGet表示自增。
源码剖析
public final int incrementAndGet() {return unsafe.getAndAddInt(this, valueOffset, 1) + 1;}
public final int getAndAddInt(Object o, long offset, int delta) {int v;do {v = getIntVolatile(o, offset);} while (!compareAndSwapInt(o, offset, v, v + delta));return v;}
public final native boolean compareAndSwapInt(Object o, long offset,int expected,int x);
offset:当前变量的地址=当前类的地址+偏移量offset
compareAndSwapInt(o, offset, v, v + delta):判断是否交换成功了,没有成功会去一直获取内存中value的值。
由此可以看出CAS是有一定弊端的,在面临高并发的场景下,可以持续死循环,导致CPU飙高。
CAS虽然很高效的解决了原子操作问题,但是CAS仍然存在三大问题。
- 自旋(循环)时间长开销很大,如果CAS失败,会一直进行尝试。如果CAS长时间一直不成功,可能会给CPU带来很大的开销,注意这里的自旋是在用户态/SDK 层面实现的。
- 只能保证一个共享变量的原子操作,对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁来保证原子性。
- ABA问题,在使用CAS前要考虑清楚“ABA”问题是否会影响程序并发的正确性,如果需要解决ABA问题,改用传统的互斥同步可能会比CAS更高效。
ABA问题:
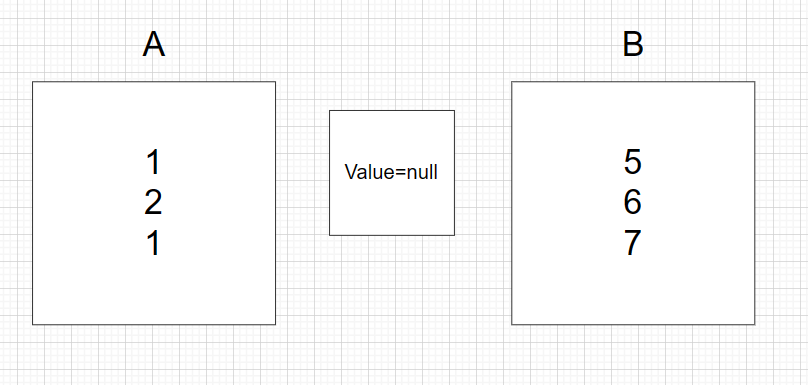
加入A拿到Value,并且进行了修改,A=1(这时候B拿到了A=1,接着A继续执行) —> A=2 —> A=1,这时候B一看,好家伙,Value还是1,该到我改了吧,这下直接A=5了,这就会导致原子性被破坏了。
可以通过引入AtomicStampedReference来解决ABA的问题
- AtomicStampedReference:原子更新带有版本号的引用类型。
public class TestAtomic {public static void main(String[] args) {AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(1, 1);int expectedReference = 1; // 当前期望的值int newReference = 2; // 新值int expectedStamp = 1; // 当前期望的版本号int newStamp = 2; // 新的版本号boolean wasUpdated = atomicStampedReference.compareAndSet(expectedReference, newReference, expectedStamp, newStamp);if (wasUpdated) {System.out.println("Update successful");} else {System.out.println("Update failed");}}
}
这篇关于ForkJoinPool、CAS原子操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





