本文主要是介绍基于二级片内硬件堆栈的后向CFI 验证方法研究,第三章,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着计算机技术的发展,针对计算机系统的恶意攻击越来越多,造成了巨大的经济损失。面向返回导向编程等恶意攻击方式通过修改堆栈中程序返回地址劫持控制流,达到恶意攻击的目的。后向控制流完整性即返回地址的完整性验证,是一种保护函数返回地址的有效手段。
本文提出了一种基于二级硬件堆栈的后向程序控制流完整性验证方法,并在国产玄铁E906 RISC-V处理器中进行了实现和分析。基于现有针对返回地址的攻击方式和后向CFI的实现方法,建立了恶意攻击威胁模型,确定了设计的安全边界;设计了二级硬件堆栈结构,可通过专用片上硬件缓冲区自动暂存新入栈返回地址,并将缓存区中旧返回地址送入传统内存堆栈;提出了二级硬件堆栈的两种具体实现方法,即延迟验证和批处理验证,分别实现对内存堆栈中返回地址的细粒度逐个验证,和基于消息验证码的多返回地址的批处理验证;在国产玄铁E906 RISC-V处理器中分别实现了两种验证方法,采用公认的基准测试程序分别对两种实现进行功能仿真和FPGA验证,并针对不同缓冲区尺寸进行了安全性和系统开销分析。
实验结果表明,本文提出的二级片内硬件堆栈能够实现对后向程序控制流的监控和验证;在返回地址缓冲区大小为2个机器字时,延迟验证和批处理验证带来的性能开销分别不高于2.94%和4.20%;返回地址缓冲区大小为4时,延迟验证和批处理验证带来的性能开销均不高于0.72%;通过Xilinx Vivado工具评估延迟验证和批处理验证实现在返回地址缓冲区大小为4时分别带来了4.7%和4.1%的硬件资源开销。
系统源代码&交流 QQ 3270516346 wx wwwicer
第3章 二级片内硬件堆栈设计
文章目录
- 系统源代码&交流 QQ 3270516346 wx wwwicer
- 第3章 二级片内硬件堆栈设计
- 3.1 威胁模型
- 3.2 工作原理
- 3.2.1 返回地址的保存
- 3.2.2 返回地址的调用
- 3.3 延迟验证
- 3.4 批处理验证
- 3.5 本章小结
3.1 威胁模型
在本文中我们假设攻击者试图劫持后向控制流,即攻击者可以利用目标代码中以函数返回指令结尾的代码片段,利用内存损坏漏洞等,例如缓冲区溢出、数组越界等,将程序堆栈中函数的返回地址覆盖为这些代码片段的地址,从而在函数返回时,运行这些片段中的指令,完成攻击行为。
我们假设攻击者能够读取任意内存区域,知道任意内存布局并且可以读取源代码,攻击者可以通过分析源代码找出进行ROP等攻击时所需要的配件。攻击者可以读写数据存储区域改变函数返回地址发起ROP之类的攻击,但攻击者无法修改源代码以及专用寄存器,在处理器内部的数据是安全的,并且我们加载的程序是正确的。
3.2 工作原理
如2.3节所述,基于MAC机制在一定程度上保护了返回地址的安全性,但是在返回地址被压入堆栈时计算返回地址的MAC,此时处理器会暂停直到MAC计算完毕;同样在返回地址弹出堆栈时也需要计算MAC,此时处理器也会被暂停直到MAC计算完毕。在程序中返回地址调用频繁,这带来了不切实际的性能开销,严重降低处理器性能。
为了改进基于MAC机制系统的性能,我们提出了二级硬件堆栈,一种新的堆栈布局,在函数内存堆栈与处理器之间增加了一个硬件返回地址缓冲区(Return Address Buffer,RAB)。返回地址缓冲区的作用是保存函数最近的返回地址,而将RAB中先前的返回地址保存到堆栈中。除此之外,只有特定的指令才能访问RAB,例如存储器访问指令,因此存储在RAB中还没有进入堆栈的返回地址攻击者无法篡改,保存在RAB中的返回地址是安全的。图3.1展示了普通堆栈与二级硬件堆栈的区别,假设RAB的大小为m并且此时有n个返回地址,在二级硬件堆栈中,内存堆栈的0到m-1个返回地址帧不在使用存储随机值,堆栈第i个帧保存第(i-m)个返回地址,最近的m个返回地址保存在硬件RAB中。在二级硬件堆栈中,RAB中返回地址MAC的计算可以与处理器流水线并行,处理器不需要暂停。并且在RAB中没有进入堆栈的返回地址时安全的,可以不用验证直接使用,这减少了MAC的验证次数,极大减少了系统性能开销。下面分别介绍二级硬件堆栈中在子函数调用和返回时返回地址的处理。
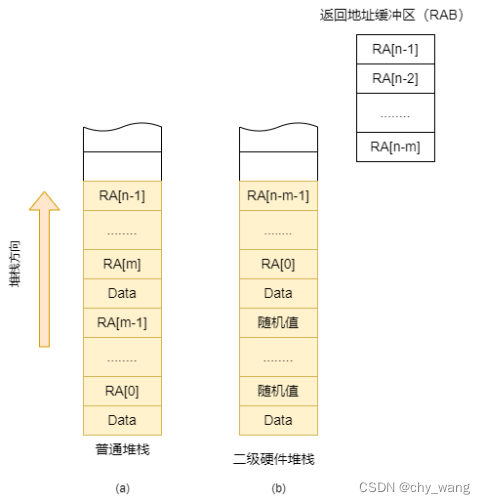
图3.1 (a)普通堆栈 (b)增加RAB的硬件堆栈
3.2.1 返回地址的保存
如图3.2所示,当程序调用第n个函数时,RAB中最早的返回地址RA[n-m]将会被推入内存堆栈,如果RA[n-m]的MAC已经被计算出来也会被推入内存堆栈,如果此时RA[n-m]的MAC还没有计算出来,则处理器会被暂停直到MAC计算完毕将MAC推入内存堆栈。该RAB条目会被最新的返回地址RA[n]覆盖,处理器继续执行其他指令同时如果MAC计算单元空闲RA[n]的MAC将会被并行计算。
3.2.2 返回地址的调用
如图3.3所示,在当程序返回第n个函数时,RAB中最新的返回地址RA[n]将用于返回,如果该返回地址从没有被推入内存堆栈,则该返回地址是安全的可以直接使用,否则就需要判断消息验证码效验是否正确,RAB中的该条目将被内存堆栈中的RA[n-m]所覆盖。
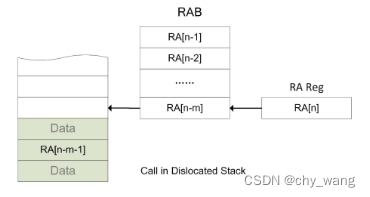
图3.2 返回地址保存
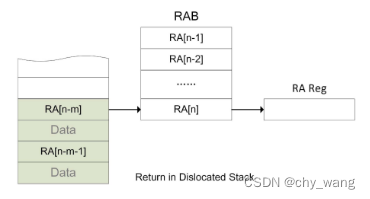
图3.3 返回地址调用
本文提出了两种硬件堆栈的验证方法,即延迟验证和批处理验证,都在一定程度上提高了系统的性能,在设计中返回地址缓冲区的条目是可以改变的,理论上条目的数量可以是2的任意次方,返回地址缓冲区越大系统性能开销越低。
3.3 延迟验证
只有当返回地址被推送到内存堆栈上攻击者才有机会修改返回地址,所以在基于MAC机制中返回地址从内存堆栈中弹出时需要进行验证以确保返回地址是可信的。在二级硬件堆栈中,只有特定的指令能够访问返回地址缓冲区,如果返回地址及其MAC未被推送到内存堆栈中就不会被攻击者破坏,而从内存弹出到返回地址缓冲区的返回地址及其MAC是不可信的,在使用该返回地址时需要进行验证。
在延迟验证中返回地址缓冲区设计了一个额外的标记字段,表示当前条目中的返回地址是否可信,当一个返回地址存储到RAB中时该返回地址时可信的,如果返回地址是从内存堆栈中弹出的则该返回地址是不可信的,可信的返回地址 在调用时不需要进行验证否则就需要进行验证,从而减少了不必要的MAC验证。在返回地址被推入返回地址缓冲区以后处理器接着执行下一条指令,MAC计算单元从返回地址缓冲区中取返回地址计算MAC并将计算的MAC存储到相应条目的MAC存储单元,在一定程度上实现了MAC计算与处理器流水线的并行,减少了流水线的暂停。
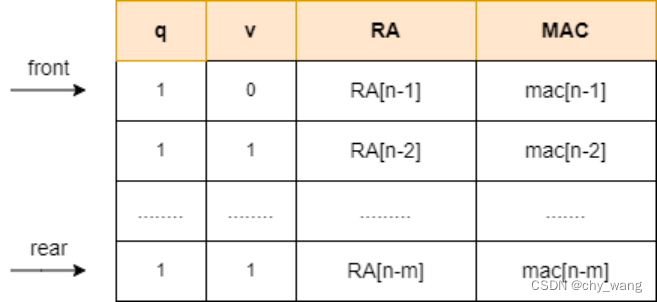
图3.4 延迟验证原理
在本文中,延迟验证方法的RAB包括四个区域,返回地址存储RA、消息验证码存储mac以及两个标记区域q和v,q和v在初始时都被标记为0,q为0表示当前条目的返回地址的MAC已经生成,v表示当前条目的返回地址是否可信,当返回地址从内存堆栈中弹出时该返回地址就是不可信的,如图3.4所示。同时包括两个硬件指针front和rear,front指向在下一次函数调用或返回时调用的返回地址,rear指向下一个返回地址计算其MAC的条目 。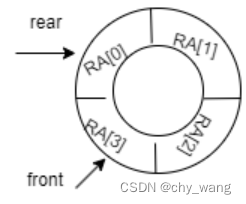
图3.5 延迟验证中RAB的环形表示
在保存返回地址时,将front指向的返回地址保存到内存堆栈中同时将其MAC保存到相应的MAC存储硬件堆栈中,如果该条目的MAC还没有计算出(q字段为0),则流水线将会被暂停直到MAC计算完毕。之后系统会将当前函数的返回地址保存到front指向的条目中,将该条目的v字段和q字段置1表示返回地址是有效的并且等待生成其MAC,同时将front加1。rear开始指向RAB的第一个条目,当rear指向的条目q字段为1时表示需要生成该条目返回地址的MAC,此时rear指向的返回地址就会送到MAC模块计算其MAC并把产生的MAC保存到该条目的MAC存储位置,MAC生成后将rear加1,rear又重复上述操作计算MAC。
在调用返回地址时,会将front-1指向的返回地址分配给ra(x1)寄存器作为当前函数的返回地址。当front-1条目的v字段为1时不需要进行验证,如果此时正在生成此返回地址的MAC,则停止计算其MAC并将q字段置0;如果返回地址的q字段为0,已经生成该返回地址的MAC则同时将rear减1。如果front-1指向的条目的v字段为0,则将该条目的q字段置1并将rear减1,将返回地址送入MAC计算单元重新计算MAC,同时暂停流水线,如果新生成的MAC与RAB中的MAC相通则表明返回地址没有被篡改,程序正常执行,否则将产生系统异常。在将front-1中原有的返回地址弹出后,系统会将内存堆栈中弹出的返回地址以及从MAC存储单元弹出的MAC保存到front-1指向的条目,同时将front-1条目的v字段置0表示其返回地址还是不可信的,将front减1表示下一次存取的条目为当前条目。
当front和rear指针指向RAB中最后一个条目时,在对其进行加1就会指向第一个条目,即front和rear的值为0,RAB相当于一个环形结构,可以循环进行操作,如图3.5所示。
3.4 批处理验证
在延迟验证中,每个返回地址的MAC都需要单独保存并且MAC计算单元几乎每时每刻都在进行运算,在硬件实现时所消耗的硬件资源以及功耗较高。为此我们提出了批处理验证,在RAB中充满新的返回地址时进行验证,可以有效降低硬件资源占用和功耗,并且RAB在硬件实现时更简单。
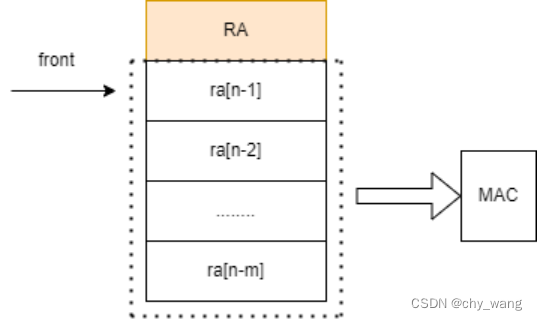
图3.6 批处理验证RAB原理图
在批处理验证中,返回地址缓冲区只需要存储返回地址的单元即可,节约了大量的硬件逻辑资源。同时需要一个硬件指针front,指向在下一次保存返回地址位置,初始时front为0指向第一个条目,如图3.5所示。在批处理验证中RAB中所有的返回地址组成一个块,例如RAB的大小为4则在返回地址中0到3为一个块,4到7为一个块以此类推,每一个块生成一个MAC。
在保存返回地址时,同延迟验证相同将front指向的条目中原有的返回地址保存到内存堆栈中并将当前函数的返回地址保存到front指向的条目中,并将front加1。在front加1后如果front溢出(值为0)说明在当前RAB中的返回地址为一个新的块,RAB中的返回地址将被送入MAC计算单元计算其MAC。在保存返回地址时,如果当前front值为0,则在保存返回地址的同时将当前块的MAC也保存到MAC存储单元。
当调用返回地址时,将front-1所指的返回地址分配给RA(x1)寄存器用于当前函数返回,同时将内存中的返回地址存储到front-1指向的条目。如果当前front不为0,则在返回时所调用的返回地址没有进入内存堆栈或者已经被验证过,可以直接使用。如果front为0,则当前使用的返回地址还没有验证,会暂停流水线将RAB中的返回地址送入MAC计算单元计算其MAC并与其MAC存储单元中弹出的MAC进行比较,如果不相等则该块中的返回地址已经被篡改产生系统异常。
可见,批处理验证所使用的硬件资源相对延迟验证较少,MAC计算单元计算频率下降功耗降低,同时不需要复杂的指针调用。但是在子函数调用相对较少的程序中,延迟验证可以在几乎没有延迟的情况下进行MAC计算,处理器性能开销更小。
3.5 本章小结
本章提出了二级片内堆栈的工作原理,并设计了两种实现方法。本章首先根据设计的攻击者攻击模型,在处理器与内存堆栈之间增加硬件缓冲区以保存最近的返回地址,并设计相应控制和外围模块,设计二级片内硬件堆栈。之后提出了惰性验证与批处理验证两种实现方法,延迟验证中MAC的计算可以与处理器流水线并行,并且只有进入过内存堆栈的返回地址需要验证,批处理验证可以一次验证多个返回地址。
这篇关于基于二级片内硬件堆栈的后向CFI 验证方法研究,第三章的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




