本文主要是介绍用Python机器学习模型预测世界杯结果靠谱吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
看到kaggle、medium上有不少人用球队的历史数据来进行建模预测,比如用到泊松分布、决策树、逻辑回归等算法,很大程度上能反映强者恒强的现象,比如巴西、英格兰等大概率能进8强,就像高考模拟考试成绩越好,大概率高考也会考得好。
这个和人脑的预测是类似的,建立在你看了足够多的球赛,对每一个国家队、球员、教练、打法等都了如指掌,你才能有充分的判断依据。而且你还不能带有主观的倾向,意大利球迷肯定笃定意大利能夺冠,但他们在预选赛就被淘汰了。
但是阿根廷输沙特、德国输日本这样的黑天鹅事件,不管是AI还是人脑都是没法预测的,否则真成预言者了。买阿根廷、德国赢的人其实是选择了大概率事件,但并没有发生,他们的决策其实是对的。
因为世界杯比赛有很多变动因素,比如裁判规则、球员伤退、排兵布阵,甚至当地环境、食宿也都会有影响,所以在进行AI预测的时候,需要有很多维度的数据进行综合分析,单单从球队的历史成绩来判断,肯定是对准确率会有影响。
这其实是有贝叶斯定理的逻辑在里面,大胆假设,小心求证。
说了一大堆,还没讲如何用AI来预测。我前几天在kaggle看到过一个博主用了GBM梯度提升算法,它通过求损失函数在梯度方向下降的方法,层层改进。
大概描述下步骤:
1、数据准备。
该项目用了【FIFA 1992-2022世界排名】、【1872-2022国家队比赛结果】两个数据集。通过数据预处理对两个数据源进行连接


2、特征工程。
列出对预测比赛结果有影响的特征字段,共37个。特征选取主要根据历史经验、直觉判断,比如过去的比赛积分、过去的进球和损失、比赛的重要性、球队排名、团队排名提升等等。


接着要对各个特征进行相关性检测,判断对预测是否有帮助,如果没有帮助的特征则直接剔除。最后留下11个最重要的特征,用来建模分析。

3、建立模型。
数据处理了,接下来是通过机器学习模型对数据进行训练,然后得出预测结果。
这里用了梯度提升和决策树两个算法,最终选recall最高的,博主测试后选择了梯度提升算法。
算法具体使用操作方法如下:

4、预测世界杯比赛。
搭建好模型,就可以把世界比赛的对阵数据放到模型里进行预测。最终算出来小组赛、十六强赛、八强赛、四强赛、总决赛的得分情况。
从目前看,预测结果其实还是复制历史经验,小组出线情况基本和世界排名情况一致,没有超乎人的经验范围。对于黑马、黑天鹅并没有什么预测能力。
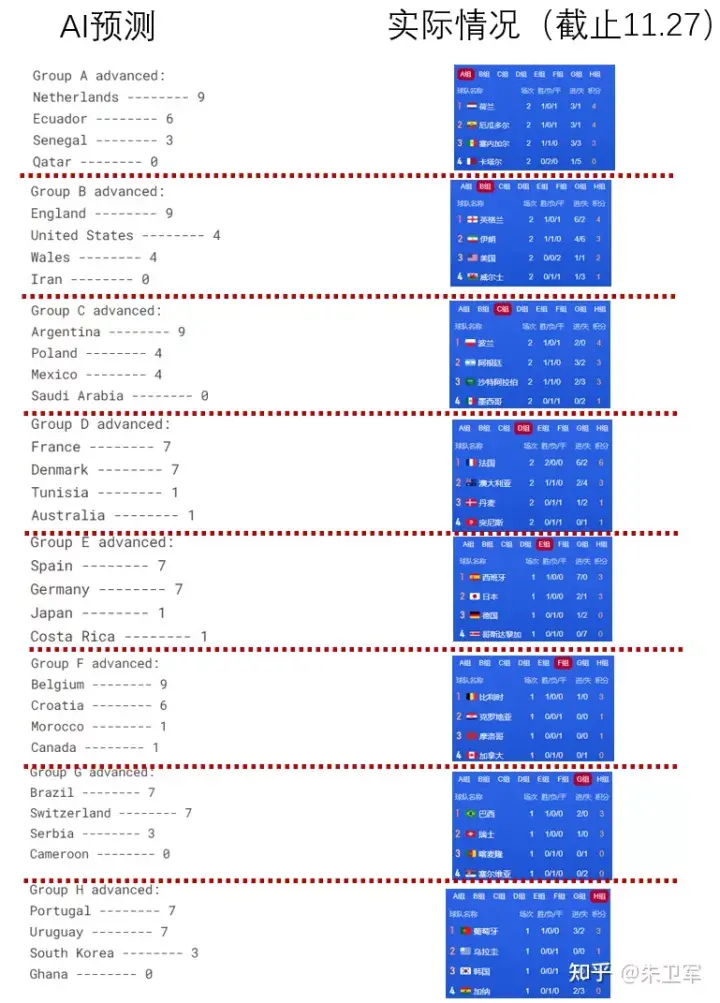
其他预测结果就不一一展示了,哦,最后好像预测是巴西夺冠概率较大。
总之,AI预测世界杯其实是对历史数据的归纳总结,而且完全依赖数据的喂养,能给出相对概率。
这和人的直觉一样,你觉得巴西会夺冠,肯定有一些过往的事实验证了你的直觉,不然就是瞎猜了。
这篇关于用Python机器学习模型预测世界杯结果靠谱吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







