本文主要是介绍Error while instantiating 'org.apache.spark.sql.hive.HiveSessionState',希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我在windows下面用idea运行spark-sql程序的时候,报了上面的那个错误,我尝试了很多方法,都没有啥效果,后来我往下继续阅读错误,发现了这个实质性错误Exception in thread "main"java.lang.UnsatisfiedLinkError。
如果是报Error while instantiating 'org.apache.spark.sql.hive.HiveSessionState',这个错误原因有很多,我建议大家检查是否做了如下操作:
1. 将配置文件拷贝到resources目录下面:
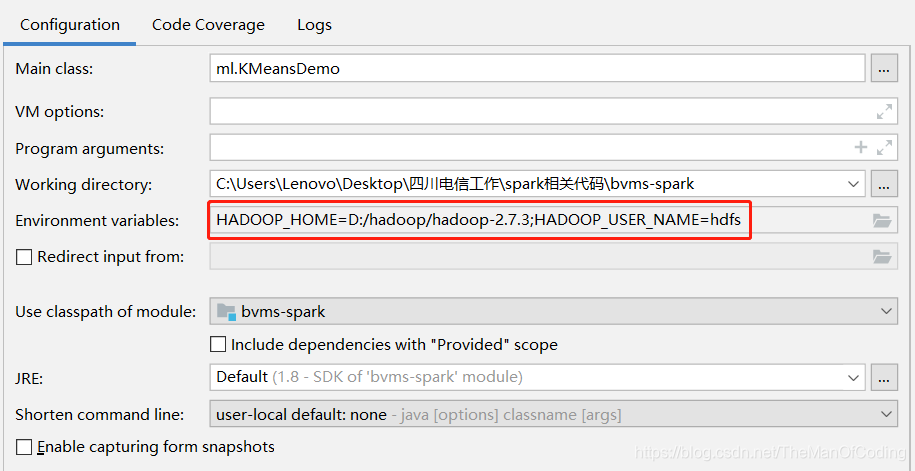
2. 配置运行时的环境变量,一个是指定windows上面的hadoop目录,另外一个是指定hadoop用户的名字(建议是采用集群里可操作hdfs的最大权限的用户名)。
3. 添加spark-env.sh下面的HADOOP_CONF_DIR这个参数。
4. 修改hdfs的权限配置。
5. 在hadoop环境的bin包下面添加winutils.exe和hadoop.dll。然后在C:\Windows\System32这个目录下面也拷贝hadoop.dll,重启idea或者eclipse。
我的这个问题恰巧是5这部分出了问题,我的环境是hadoop2.7.3,而我用的是hadoop2.2包里面的winutils.exe和hadoop.dull。导致了Exception in thread "main"java.lang.UnsatisfiedLinkError。
后来我在网上找到了最终解决方案:
我用的是hadoop2.7.1的bin包下面的winutils.exe和hadoop.dull
下载地址如下:
https://download.csdn.net/download/n1007530194/9221605
这篇关于Error while instantiating 'org.apache.spark.sql.hive.HiveSessionState'的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




