本文主要是介绍怪兽充电基于 ShardingSphere 的“架构充电”全记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 怪兽充电业务中对 ShardingSphere-JDBC 的使用
背景介绍
随着怪兽充电应用的并发量越来越大,产生的数据量(用户,订单,活动等)与日俱增。传统关系型数据库已经很难支撑单库单表动辄百万、千万级别的数据体量,其性能已然无法满足业务发展的性能要求,而分库分表却是面对此列问题一个行之有效的解决方案。
技术选型
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈。在 Database Plus 理念的指导下,ShardingSphere 旨在碎片化的异构数据库上层构建生态,在最大限度的复用数据库原生存算能力的前提下,进一步提供面向全局的扩展和叠加计算能力。使应用和数据库间的交互面向 Database Plus 构建的标准,从而屏蔽数据库碎片化对上层业务带来的差异化影响。
其中,ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。ShardingSphere-JDBC 通过统筹协调分库分表下的数据读写,让业务开发人员只需关注数据层之外的工作,而不需要用业务代码来人工判断库表选择。
应用示例
UCS,是怪兽用户中心服务,提供于 Server 端用户基础功能,2018 年从 PHP Server 中剥离,转到 Java 技术栈并实现微服务化。其中涉及到新的库表设计和数据清洗迁移,整个切换过程保证基本功能的同时要做到:
• 稳定性:不停机上线,在短时间内完成平滑发布;
• 准确性:保证千万级数据量清洗准确;
• 可扩展性:满足数据增长带来的性能问题及拓展性。
数据清洗迁移方案
-
初步数据同步
-
应用server切断入口(用户)
-
数据同步(距上次时间点的更新和新用户)
-
数据清洗
-
用户中心发布
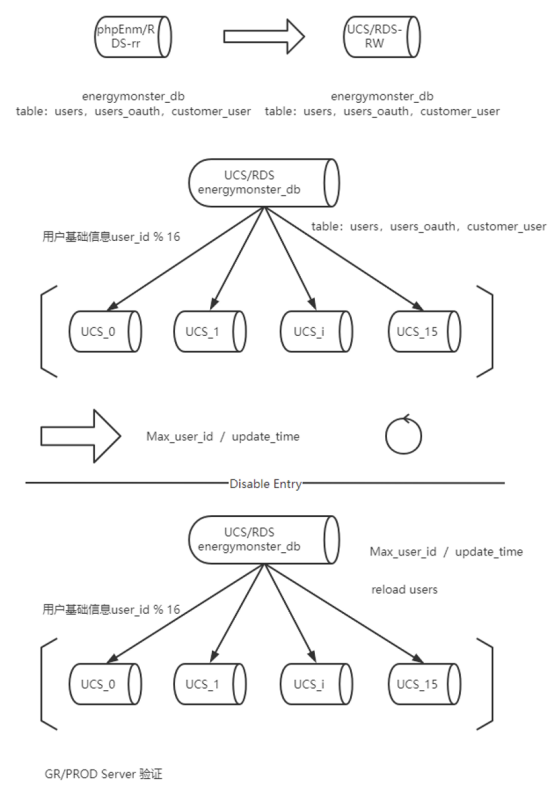
数据分片策略
数据库采用 sharding 分库设计,分 16 个库。默认以 user_id 为分片键 key,分片策略 user_id 取模 16。如:用户表的 ${user_id % 16}。对于不携带分片键的 SQL,则采取广播路由的方式。
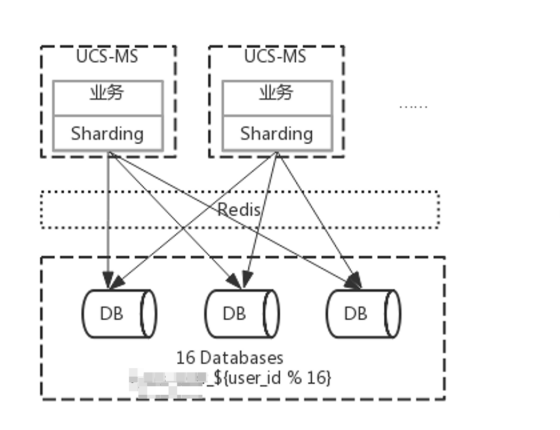
user_id 作为分片键是考虑到 user_id 能够覆盖到大部分的业务场景,另外其它字段不能保证不为空。在本地测试中,分片键策略查询(openId,mobile)用时 50ms~200ms 范围内。
分片算法的使用
目前提供 3 种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
-
标准分片算法,对应 StandardShardingAlgorithm,用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
-
复合分片算法,对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要开发者自行处理其中的复杂度。
-
Hint 分片算法,对应 HintShardingAlgorithm,用于处理使用 Hint 行分片的场景。
2 ShardingSphere-JDBC 版本升级
背景
公司在订单、库存、财务等多个业务场景中使用 ShardingSphere-JDBC,各个研发组所使用版本较为分散,且跨度大。截止到 2021 年,内部各团队应用 ShardingSphere-JDBC 的版本从 1.X 到 4.X 都有(升级项目开启时官方最新版本为 4.X),不利于研发后期统一维护,而且低版本存在一些潜在 bug 和功能缺失。基于统一管理和健壮性要求,在前期充分调研和沟通后,我们于 2021 年 4 月推动实施公司 ShardingSphere-JDBC 版本统一,升级至 4.1.1 稳定版本。
由于存在版本升级跨度大,在服务升级过程中不可避免会遇到一些不兼容问题和使用误区,以下是一些问题记录:
1. 升级后服务启动耗时较长
服务启动时 ShardingSphere-JDBC 会检查分表元数据一致性,配置项:max.connections.size.per.quer(每个查询可以打开的最大连接数量)默认为 1,当表数量较多时,加载会比较慢,需参照连接池配置,适当提高该值,以提高加载速度。
2. 分表查询无分片键,出现无响应

逻辑 SQL 查询时不指定分片键,会以按广播形式按全库表路由查询所有表,上述配置项一个数据库共 108 张真实表,根据 maxConnectionsizeperquery=50 的配置,ShardingSphere-JDBC 使用连接限制模式并分 3 组查询请求后采用内存归并结果,一次查询需获取 36 个数据库连接,但是 druid 线程池配置的 maxActive 为 20,造成一直等待获取数据库连接,产生死锁现象。
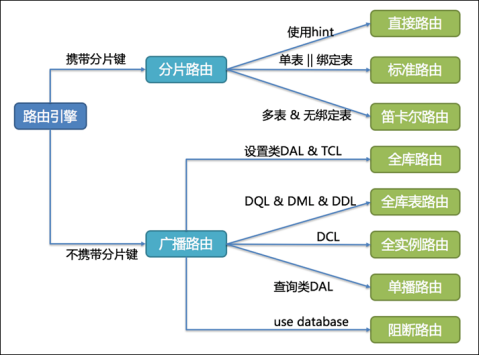

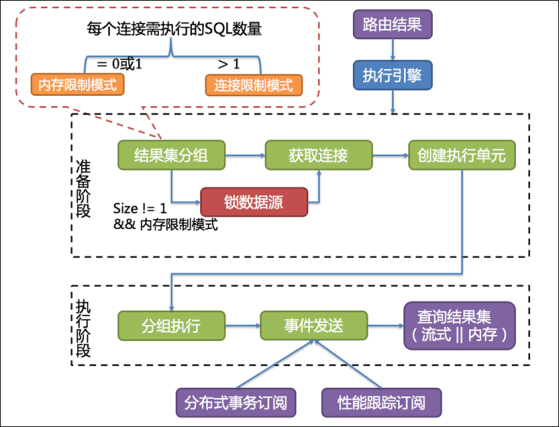
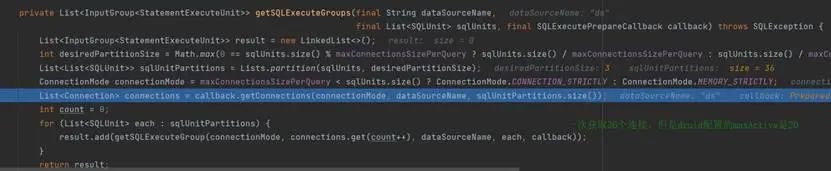
解决方案:
-
结合 check.table.metadata.enabled=true(启动时检查分表元数据一致性),合理配置maxConnectionSizePerQuery(每个查询可以打开的最大连接数量);
-
maxConnectionSizePerQuery 需要小于 druid 线程池配置的最大活跃线程数。
3. 从 1.X 升级后,SQL 执行出现 “Can not update sharding key” 错误,实际分片键值未更新
为避免修改分片键值导致数据查询失败,4.X 版本在 SQL update 加入了检测分片键,出现该错误可通过以下修改方式:
-
去除 update 中分片键
-
where 语句同步加入分片键
4. 使用 druid-spring-boot-starter 对 Sharding-datasource 冲突导致启动失败
druid 数据连接池 starter 会先加载并且其创建一个默认数据源,会使得 ShardingSphere-JDBC 创建数据源时发生冲突,去掉 druid starter 即可。
5. inline strategy 在范围查询查询时报错
inline stragegy 默认不支持范围查询,范围查询建议使用 standard stragegy。如需要 inline stragegy 支持范围查询,可添加以下配置:
spring.shardingsphere.props.allow.range.query.with.inline.sharding: true
注:此时所有的 inline strategy 范围查询将会使用广播的方式查询每一个分表。
6. 出现 Can not find owner from table 错误
SQL(简化):
select id from (select id from x) as a group by a.id
4.x 版本支持有限子查询,该问题是由于中间表名称引起,将 select 或 group order 等子段,去除表别名。
https://github.com/apache/shardingsphere/issues/4810
7. 表主键使用 SNOWFLAKE 生成主键时冲突
ShardingSphere 提供灵活的配置分布式主键生成策略方式。在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法(snowflake)生成 64bit 的长整型数据。雪花生成器需要配置:
spring.shardingsphere.sharding.tables.x.key-generator.props.worker.id = ${dcc.node.id}

公司使用 apollo 配置中心下发服务实例节点 id,该服务使用多数据源,yaml 文件方式加载 sharding 配置,无法自动将 workId 加载到 sharding 的配置项。
解决方案:
基于内置的 SnowflakeShardingKeyGenerator 自定义生成器类型:
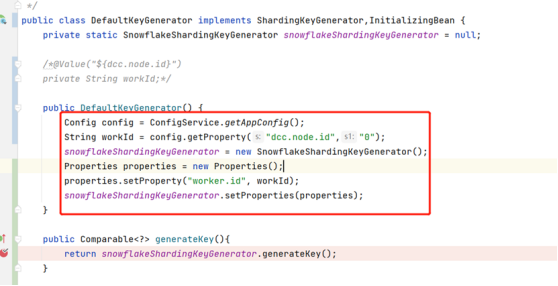
另如果主键用于分片键,需根据分库分表数配置 max.vibration.offset 以提高抖动范围。

8. 3.X 版本带 CASE WHEN 语句执行错误
首先 3.X 和 4.X 版本不支持 case when 语句。
3.X 版本和 4.X 版本对待 case when 的 update 语句解析分片键的逻辑不同,4.X parserEngine.parse 方法会忽略 case when 解析参数,导致和外部的 parameters 参数列表不对应,导致原先 3.X 执行正常的 SQL 会执行错误;3.X 版本之所以正确执行,是在于编写 SQL 的时候,将 case when 的第一个参数有意设置为分片键,而且 case when 语句放在最前面。
https://github.com/apache/shardingsphere/issues/13233
解决方案:
-
因不支持 case when,建议改写 SQL
-
结合 4.1.1 版本解析分片键逻辑,将 case when 放置在最后,case when 的第一个参数仍保持为分片键
9. 逻辑表 actualDataNodes 已配置,插入报主键无默认值错误
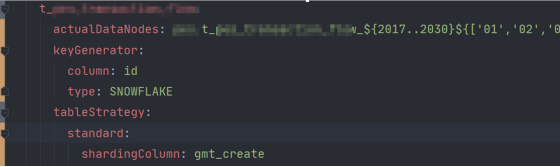

服务未配置 check.table.metadata.enabled=true,默认不检查分表元数据一致性。
服务配置的 actualDataNodes 第一个表实际并不存在,导致 GenerateKeyContenxt 为空。
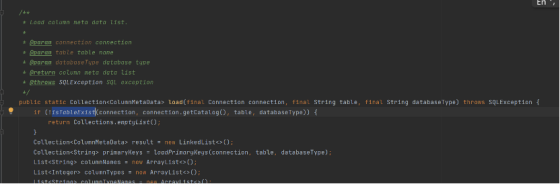

解决措施:
-
加上 check.table.metadata.enabled=true 配置,启动时检测到不存在的表并抛出错误;
-
改写 actualDataNodes inline 表达式,保证第一个表真实存在。
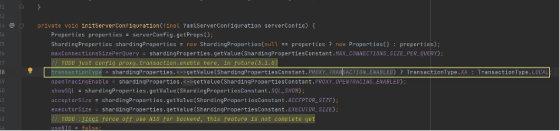
10. 3.0 版本全库表路由高并发下死锁现象
ShardingSphere-JDBC 默认使用本地事务,在本地事务下,异步获取数据库连接,在高并发下有几率导致获取不到本次查询全部的数据库连接,产生死锁现象。



3 写在最后
作为 Apache ShardingSphere 的核心用户,怪兽充电的版本升级历程在一定程度上也反应了目前社区用户在应用 ShardingSphere 过程中所会遇到的一部分问题。
目前 Apache ShardingSphere 稳定版已经更新到 5.1.1,在功能、性能、测试、文档、示例等方面均有不少优化。有需要了解的同学们,可以访问 Apache ShardingSphere 官网进行参考。如果您有任何问题或建议,也欢迎到 Apache ShardingSphere 在 Github 上的页面进行反馈,社区将积极回应用户问题,共同在 ShardingSphere 社区探讨。
Apache ShardingSphere 官网:https://shardingsphere.apache.org/
Apache ShardingSphere GitHub 地址: https://github.com/apache/shardingsphere
这篇关于怪兽充电基于 ShardingSphere 的“架构充电”全记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







