本文主要是介绍Hyperledger Fabric 私有数据(2)操作流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 私有数据资产转移的案例
collections_config.json文件定义了3个私有数据集合定义:assetCollection、Org1MSPPrivateCollection和Org2MSPPrivateCollection。
eg. collections_config.json文件内容
[{"name": "assetCollection","policy": "OR('Org1MSP.member', 'Org2MSP.member')","requiredPeerCount": 1,"maxPeerCount": 1,"blockToLive":1000000,"memberOnlyRead": true,"memberOnlyWrite": true},{"name": "Org1MSPPrivateCollection","policy": "OR('Org1MSP.member')","requiredPeerCount": 0,"maxPeerCount": 1,"blockToLive":3,"memberOnlyRead": true,"memberOnlyWrite": false,"endorsementPolicy": {"signaturePolicy": "OR('Org1MSP.member')" }},{"name": "Org2MSPPrivateCollection","policy": "OR('Org2MSP.member')","requiredPeerCount": 0,"maxPeerCount": 1,"blockToLive":3,"memberOnlyRead": true,"memberOnlyWrite": false,"endorsementPolicy": {"signaturePolicy": "OR('Org2MSP.member')" }}]
2. 数据结构
2.1 chaincode内部结构体
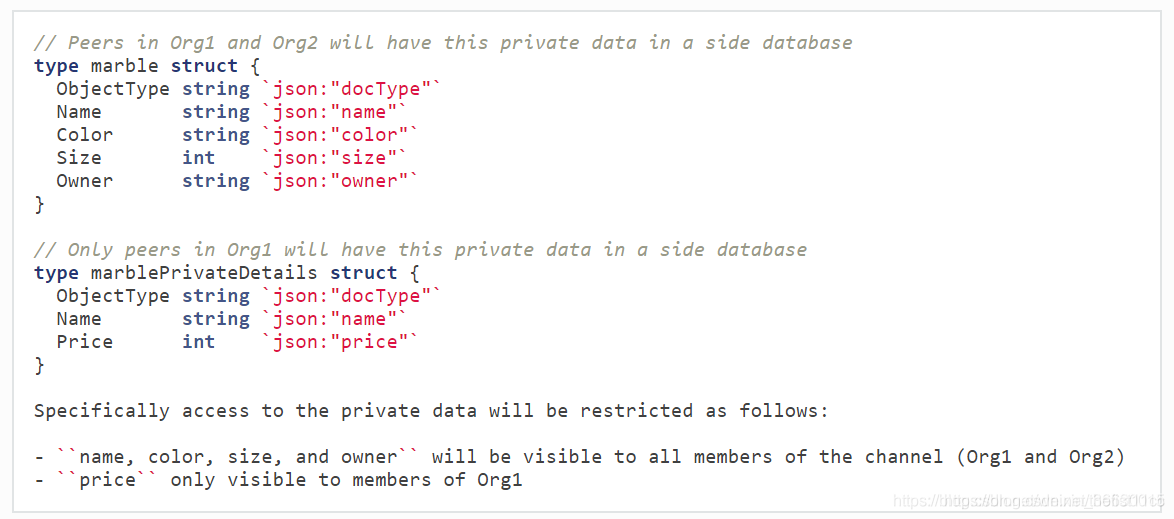
2.2 物理存储结构

3. 操作流程
3.1. 链码流程
step1. base64格式化编码私有数据参数
export private_create=$(echo -n “{“assetID”:“10004” , “objectType”:“1” , “color” : “red” , “appraisedValue” : 1000 , “size”:100 }” | base64 | tr -d \n)
step2. 安装智能合约
peer lifecycle chaincode install /opt/gopath/src/github.com/chaincode/private.tar.gz
step3. 配置合约参数ID
export CC_PACKAGE_ID=private:939ab0bae5f72a707fffac97f38600db7d4fb116d3d7c45bc0be2082c58f33c0
step4. 导入私有参数的配置路径
export CC_COLL_CONFIG=/opt/gopath/src/github.com/chaincode/collections_config.json
step5. 节点授权安装合约
peer lifecycle chaincode approveformyorg --signature-policy “OR(‘Org1MSP.member’,‘Org2MSP.member’,‘Org3MSP.member’)” -o orderer.xxx.com:7050 --channelID mychannel --name private --version 1.0 --package-id $CC_PACKAGE_ID --sequence 10 --collections-config $CC_COLL_CONFIG --tls --cafile $ORDERER_TLSCA
step6. 提交合约
peer lifecycle chaincode commit --signature-policy “OR(‘Org1MSP.member’,‘Org2MSP.member’,‘Org3MSP.member’)” -o orderer.xxx.com:7050 --channelID mychannel --name private --version 1.0 --sequence 11 --tls --cafile $ORDERER_TLSCA --collections-config $CC_COLL_CONFIG --peerAddresses peer0.org1.xxx.com:7051 --tlsRootCertFiles ${PWD}/config/crypto-config/peerOrganizations/org1.xxx.com/peers/peer0.org1.xxx.com/tls/ca.crt --peerAddresses peer0.org2.xxx.com:7051 --tlsRootCertFiles ${PWD}/config/crypto-config/peerOrganizations/org2.xxx.com/peers/peer0.org2.xxx.com/tls/ca.crt --peerAddresses peer0.org3.xxx.com:7051 --tlsRootCertFiles ${PWD}/config/crypto-config/peerOrganizations/org3.xxx.com/peers/peer0.org3.xxx.com/tls/ca.crt
step7. 通过以上参数的设置好后,调用合约的命令就会非常简洁
peer chaincode invoke -o orderer.xxx.com:7050 --tls --cafile KaTeX parse error: Can't use function '\"' in math mode at position 84: … --transient "{\̲"̲asset_propertie…private_create"}"
step8. 实例化chaincode时需要指定定义的json文件
注意–collections-config参数
peer chaincode instantiate -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C mychannel -n marblesp -v 1.0 -c ‘{“Args”:[“init”]}’ -P “OR(‘Org1MSP.member’,‘Org2MSP.member’)” --collections-config $GOPATH/src/github.com/chaincode/marbles02_private/collections_config.json
3.2. 链码相关操作
step1. 初始化私有数据,不是执行init而是执行invoke的initMarble
peer chaincode invoke -o orderer.example.com:7050 --tls --cafile /opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem -C mychannel -n marblesp -c ‘{“Args”:[“initMarble”,“marble1”,“blue”,“35”,“tom”,“99”]}’
step2.在org1上查询私有数据
eg.
peer chaincode query -C mychannel -n marblesp -c ‘{“Args”:[“readMarble”,“marble1”]}’
结果
{“color”:“blue”,“docType”:“marble”,“name”:“marble1”,“owner”:“tom”,“size”:35}
eg2.
peer chaincode query -C mychannel -n marblesp -c ‘{“Args”:[“readMarblePrivateDetails”,“marble1”]}’
结果
{“docType”:“marblePrivateDetails”,“name”:“marble1”,“price”:99}
step3. 在org2上查询私有数据
eg1.
peer chaincode query -C mychannel -n marblesp -c ‘{“Args”:[“readMarble”,“marble1”]}’
结果
{“docType”:“marble”,“name”:“marble1”,“color”:“blue”,“size”:35,“owner”:“tom”}
eg2.
peer chaincode query -C mychannel -n marblesp -c ‘{“Args”:[“readMarblePrivateDetails”,“marble1”]}’
{“Error”:“Failed to get private details for marble1: GET_STATE failed:
transaction ID: b04adebbf165ddc90b4ab897171e1daa7d360079ac18e65fa15d84ddfebfae90:
Private data matching public hash version is not available. Public hash
version = &version.Height{BlockNum:0x6, TxNum:0x0}, Private data version =
(*version.Height)(nil)”}"
step4. 删除数据
私有数据可以复制到离线数据库中,同时,可以通过blockToLive这个属性指定产生几个块以后,删除私有数据,在链上只保存hash值。当数据被删除的时候,再查询数据时,会发生下面的错误
Error: endorsement failure during query. response: status:500
message:"{“Error”:“Marble private details does not exist: marble1”}"
这篇关于Hyperledger Fabric 私有数据(2)操作流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



