本文主要是介绍Ubuntu上安装d4rl数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Ubuntu上安装d4rl数据集
D4RL的官方 github: https://github.com/Farama-Foundation/D4RL
一、安装Mujoco
1.1 官网下载mujoco210文件
如果装过可以跳过这步
链接:https://github.com/deepmind/mujoco/releases/tag/2.1.0
下载第一个文件即可。我这里是在windows系统上下载了,然后上传到linux系统服务器上的。
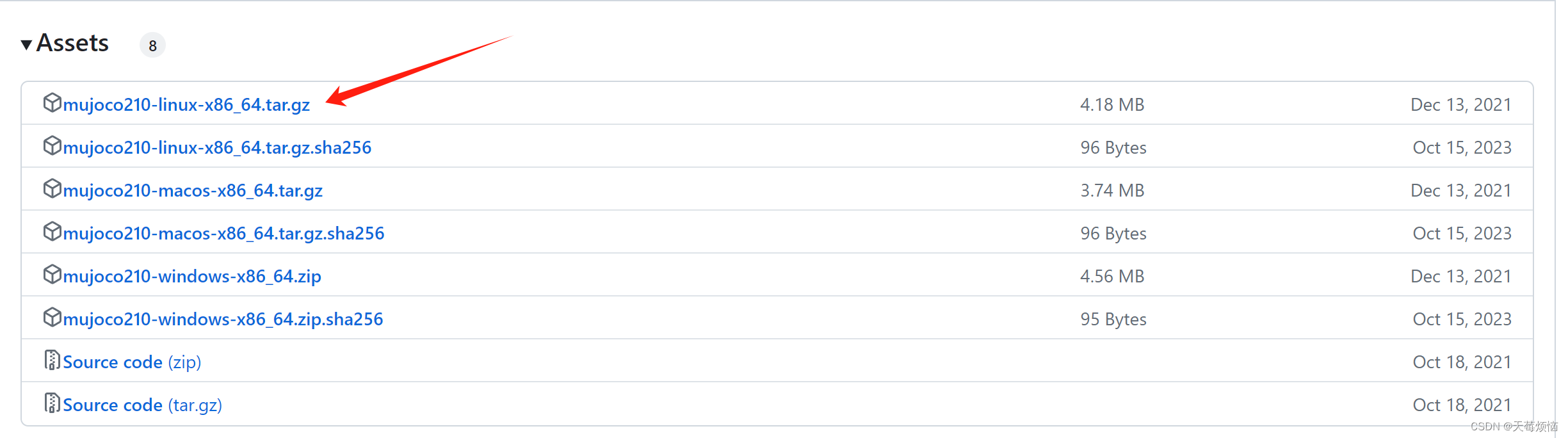
1.2 解压该文件
查看自己的用户目录下是否有 .mujoco 文件夹
ls -a
如果没有的话,可以新建一个
mkdir ~/.mujoco
将下载好的压缩文件放在这个目录下,然后进行解压
tar -zxvf mujoco210-linux-x86_64.tar.gz -C ~/.mujoco
解压完后应该有一大堆的 .h .cc 文件在命令行里。
1.3 配置环境
vim ~/.bashrc
在文件末尾加上一行
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/user_name/.mujoco/mujoco210/bin
保存退出并运行
source ~/.bashrc
1.4测试是否安装完成
cd ~/.mujoco/mujoco210/bin
./simulate ../model/humanoid.xml
出现 Mujoco Pro Version 就算成功
二、下载 D4RL 项目
可以运行命令行
git clone https://github.com/Farama-Foundation/d4rl.git
也可以直接手动下载到 Linux 上或者手动下载到 Windows 上然后上传到 Linux 服务器上。
三、安装依赖库
3.1 新建虚拟环境
运行以下命令新建一个虚拟环境
python -m venv /path/to/your/venv
/path/to/your/venv 是你的虚拟环境路径
然后运行
source /path/to/your/venv/bin/activate
命令行前面出现 (your_venv_name) 就算成功
3.2 提前安装部分库
pip install mujoco-py
pip install absl-py
pip install matplotlib
pip install dm_control
提前安装这四个库
3.3 注释部分库
到你路径下的 D4RL 项目去修改 setup.py
cd your/directory/to/D4RL
vim setup.py
注释掉如下几行,因为已经提前安装好这些库。mjrl 我们最后再装!mjrl 我们最后再装!mjrl 我们最后再装!
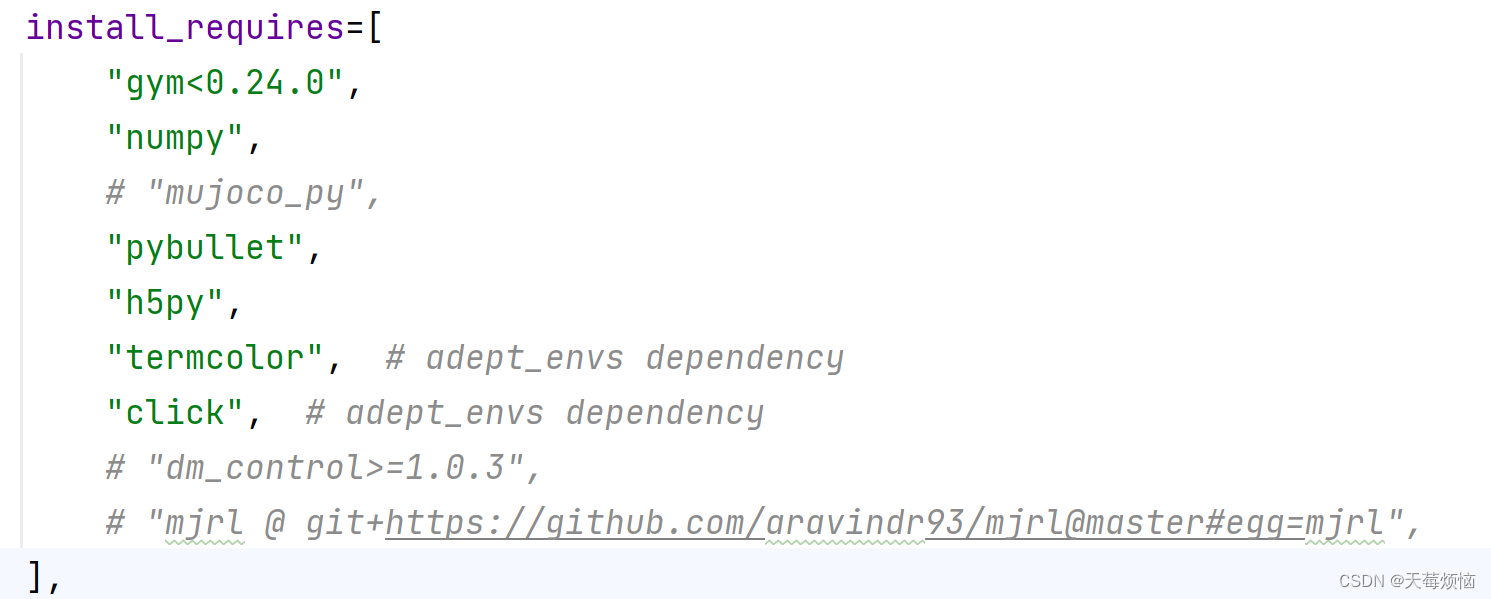
在 D4RL 目录下,运行
pip install -e .
3.4 安装 mjrl
运行
pip install git+https://github.com/aravindr93/mjrl@master#egg=mjrl
到这里所有环境基本已经安装完成。可以用
pip list
查看这些库是否都已经装上。
四、查漏补缺
在 D4RL 目录下新建一个 example.py 文件,复制官方github的测试内容
import gym
import d4rl # Import required to register environments, you may need to also import the submodule# Create the environment
env = gym.make('maze2d-umaze-v1')# d4rl abides by the OpenAI gym interface
env.reset()
env.step(env.action_space.sample())# Each task is associated with a dataset
# dataset contains observations, actions, rewards, terminals, and infos
dataset = env.get_dataset()
print(dataset['observations']) # An N x dim_observation Numpy array of observations# Alternatively, use d4rl.qlearning_dataset which
# also adds next_observations.
dataset = d4rl.qlearning_dataset(env)
尝试运行上述文件
python example.py
出现报错:
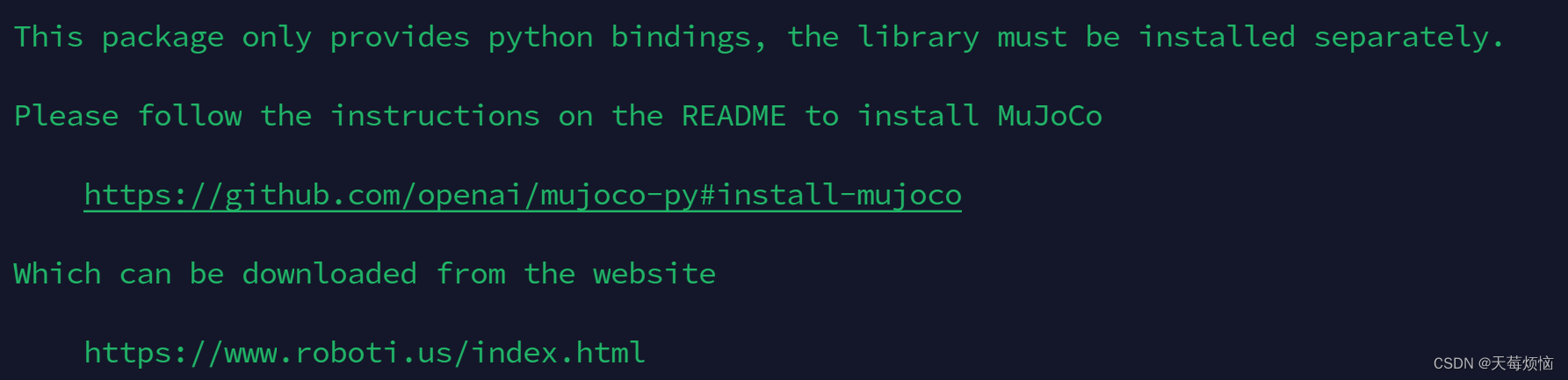
4.1 获取 key
点击下面的 Activation key 会得到一个 mjkey.txt 文件
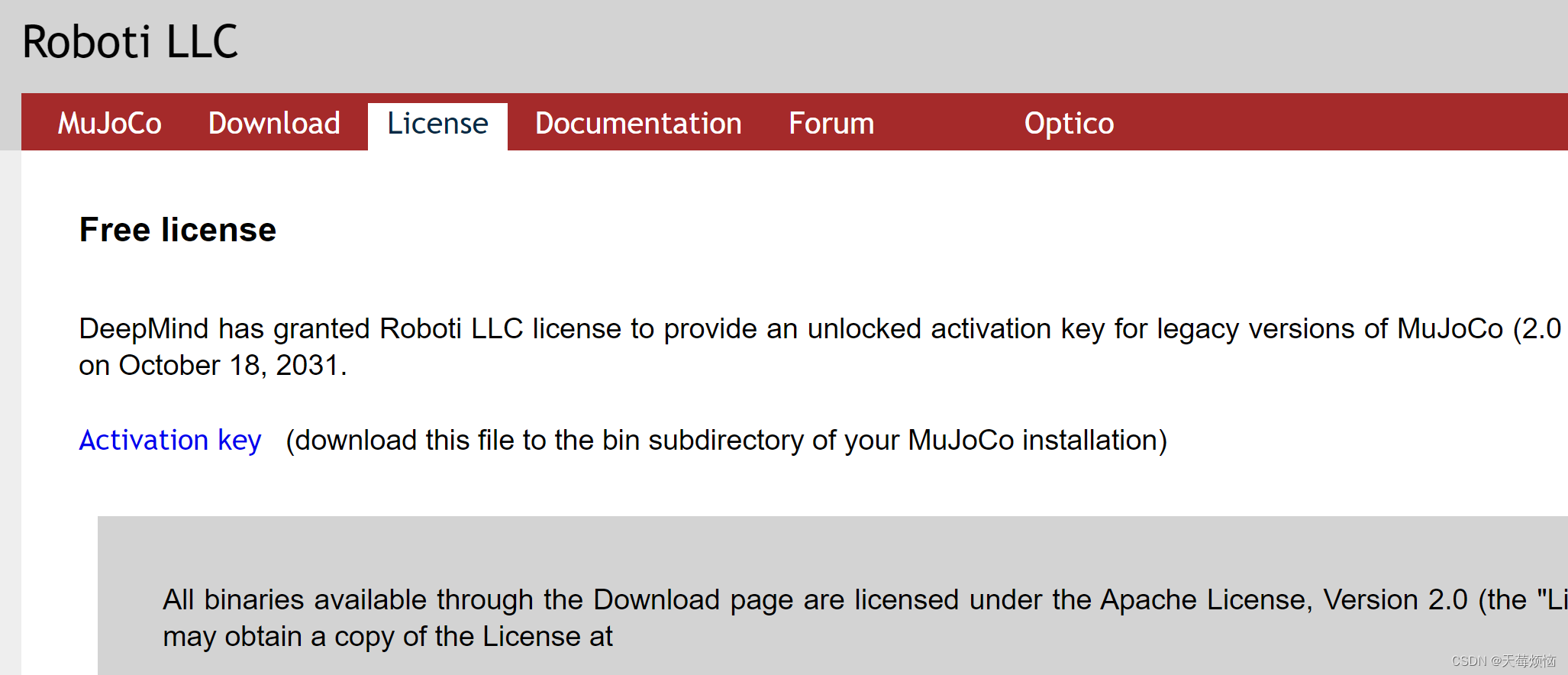
将mjkey.txt文件复制到 .mujoco/mujoco200/bin和./mujoco文件夹下
4.2 没有配置好路径
Exception:
Missing path to your environment variable.
Current values LD_LIBRARY_PATH=:/home/user_name/.mujoco/mujoco210/bin
Please add following line to .bashrc:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
博主到这里才发现原来还要配置一个地方
回到 1.3 的 ~/.bashrc,加多一行
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/user_name/.mujoco/mujoco210/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
然后重新
source ~/.bashrc
然后重新进入虚拟环境
source /path/to/your/venv/bin/activate
4.3 编译问题
再次运行文件遇到报错
Cython.Compiler.Errors.CompileError: /home/user_name/pyvenv/rl/lib/python3.8/site-packages/mujoco_py/cymj.pyx
这个需要更换版本
pip uninstall cython
pip install cython==0.29.21
4.4 软件问题
FileNotFoundError: [Errno 2] No such file or directory: 'patchelf'
运行以下命令解决
sudo apt-get -y install patchelf
安装完之后就可以成功运行测试代码了
这篇关于Ubuntu上安装d4rl数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







