本文主要是介绍新库上线 | CnOpenData交通运输、仓储和邮政业工商注册企业基本信息数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
交通运输、仓储和邮政业工商注册企业基本信息数据
一、数据简介
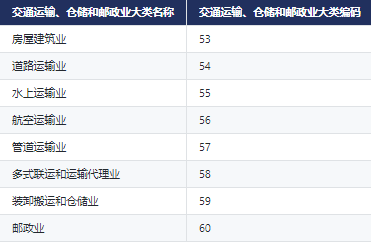
根据国民经济行业分类,交通运输、仓储和邮政业分为房屋建筑业、道路运输业、水上运输业、航空运输业、管道运输业、多式联运和运输代理业、装卸搬运和仓储业、邮政业。
交通运输、仓储和邮政业作为国民经济中的基础性和先导性行业,长期持续平稳健康发展,为支持全国经济高质量发展、保障和改善民生作出了积极贡献。作为交通运输、仓储和邮政大国,我国正着力加快构建现代化综合运输体系,推进全区域性综合交通枢纽建设,建立海陆空三位一体的交通运输大格局,为推动全国经济社会的科学发展提供强有力的交通支撑。
CnOpenData依据国民经济行业分类,整理了我国1950年至2021年的交通运输、仓储和邮政业工商注册企业基本信息,生动展现了我国建国以来交通运输、仓储和邮政业的发展历程。
二、数据规模

三、时间区间
1950-2021.12.31
四、行业明细
五、字段展示
这篇关于新库上线 | CnOpenData交通运输、仓储和邮政业工商注册企业基本信息数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







