本文主要是介绍【Ucore操作系统】8. 并发,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 【 0. 引言 】
- 0.1 线程定义
- 0.2 同步互斥
- 【 1. 内核态的线程管理 】
- 1.1 线程概念
- 1.2 线程模型与重要系统调用
- 1.2.1 线程创建系统调用
- 1.2.2 等待子线程系统调用
- 1.2.3 进程相关的系统调用
- 1.3 应用程序示例
- 1.3.1 系统调用封装
- 1.3.2 多线程应用程序 – threads
- 1.4 线程管理的核心数据结构
- 1.4.1 线程控制块
- 1.4.2 包含线程的进程控制块
- 1.5 线程管理机制的设计与实现
- 1.5.1线程创建、线程退出与等待线程结束
- 1.5.1.1 线程创建
- 1.5.1.2 线程退出
- 1.5.1.3 等待线程结束
- 1.5.2 线程执行中的特权级切换和调度切换
- 【 2. 锁机制 】
- 2.1 为什么需要锁
- 2.2 锁的基本思路
- 2.3 内核态操作系统级方法实现锁 — mutex 系统调用
- 2.3.1 使用 mutex 系统调用
- 2.3.2 mutex 系统调用的实现
- 【 3. 信号量机制 】
- 3.1 信号量的起源和基本思路
- 3.2 实现信号量
- 3.2.1 使用 semaphore 系统调用
- 3.2.2 实现 semaphore 系统调用
- 【 4. 条件变量机制 】
- 4.1 条件变量的基本思路
- 4.2 实现条件变量
- 4.2.1 使用 condvar 系统调用
- 4.2.2 实现 condvar 系统调用
【 0. 引言 】
- 到本章开始之前,我们完成了组成应用程序执行环境的操作系统的三个重要抽象:进程、地址空间和文件。 操作系统基于处理器的时间片不断地切换进程可以实现宏观的多应用并发,但仅限于进程间。 下面我们引入 线程(Thread):提高一个进程内的并发性。
- 为什么有了进程还需要线程呢?因为 对于很多单进程应用,逻辑上存在多个可并行执行的任务, 如果没有多线程,其中一个任务被阻塞,将会引起不依赖该任务的其他任务也被阻塞。 譬如我们用 Word 时,会有一个定时自动保存功能,如果你电脑突然崩溃关机或者停电,已有的文档内容或许已被提前保存。 假设没有多线程,自动保存时由于磁盘性能导致写入较慢,可能导致整个进程被操作系统挂起, 对我们来说便是 Word 过一阵子就卡一会儿,严重影响体验。
0.1 线程定义
- 简单地说,线程是进程的组成部分,进程可包含 1~n 个线程, 属于同一个进程的线程共享进程的资源, 比如地址空间、打开的文件等。基本的线程由线程ID、执行状态、当前指令指针 (PC)、寄存器集合和栈组成。 线程是可以被操作系统或用户态调度器独立调度(Scheduling)和分派(Dispatch)的基本单位。
- 在本章之前,进程是程序的基本执行实体,是程序关于某数据集合上的一次运行活动,是系统进行资源(处理器、 地址空间和文件等)分配和调度的基本单位。在有了线程后,对进程的定义也要调整了,进程是线程的资源容器, 线程成为了程序的基本执行实体。
0.2 同步互斥
- 当多个线程共享同一进程的地址空间时, 每个线程都可以访问属于这个进程的数据(全局变量)。
- 如果每个线程使用到的变量都是其他线程不会读取或者修改的话, 那么就不存在 一致性 问题。如果变量是只读的,多个线程读取该变量也不会有一致性问题。
- 但是,当一个线程修改变量时, 其他线程在读取这个变量时,可能会看到一个不一致的值,这就是数据不一致性的问题。
并发相关术语
- 共享资源(shared resource):不同的线程/进程都能访问的变量或数据结构。
- 临界区(critical section):访问共享资源的一段代码。
- 竞态条件(race condition):多个线程/进程都进入临界区时,都试图更新共享的数据结构,导致产生了不期望的结果。
- 不确定性(indeterminate): 多个线程/进程在执行过程中出现了竞态条件,导致执行结果取决于哪些线程在何时运行, 即执行结果不确定,而开发者期望得到的是确定的结果。
- 互斥(mutual exclusion):一种操作原语,能 保证只有一个线程进入临界区,从而避免出现竞态,并产生确定的执行结果。
- 原子性(atomic):一系列操作要么全部完成,要么一个都没执行,不会看到中间状态。在数据库领域, 具有原子性的一系列操作称为事务(transaction)。
- 同步(synchronization): 多个并发执行的进程/线程在一些关键点上需要互相等待,这种相互制约的等待 称为进程/线程同步。
- 死锁(dead lock):一个线程/进程集合里面的每个线程/进程都在等待只能由这个集合中的其他一个线程/进程 (包括他自身)才能引发的事件,这种情况就是死锁。
- 饥饿(hungry):指一个可运行的线程/进程尽管能继续执行,但由于操作系统的调度而被无限期地忽视,导致不能执行的情况。
【 1. 内核态的线程管理 】
1.1 线程概念
- 这里会结合与进程的比较来说明线程的概念。到本章之前,我们看到了进程这一抽象, 操作系统让进程拥有相互隔离的虚拟的地址空间, 让进程感到在独占一个虚拟的处理器。其实这只是操作系统通过时分复用和空分复用技术来让每个进程复用有限的物理内存和物理CPU。 而线程是在进程内中的一个新的抽象。在没有线程之前,一个进程在一个时刻只有一个执行点(即程序计数器 (PC) 寄存器保存的要执行指令的指针)。但 线程的引入把进程内的这个单一执行点给扩展为多个执行点,即在进程中存在多个线程, 每个线程都有一个执行点。而且这些线程共享进程的地址空间,所以可以不必采用相对比较复杂的 IPC 机制(一般需要内核的介入), 而可以很方便地直接访问进程内的数据。
- 在线程的具体运行过程中,需要有程序计数器寄存器来记录当前的执行位置,需要有一组通用寄存器记录当前的指令的操作数据, 需要有一个栈来保存线程执行过程的函数调用栈和局部变量等,这就形成了线程上下文的主体部分。 这样 如果两个线程运行在一个处理器上,就需要采用类似两个进程运行在一个处理器上的调度/切换管理机制, 即需要在一定时刻进行线程切换,并进行线程上下文的保存与恢复。这样在一个进程中的多线程可以独立运行, 取代了进程,成为操作系统调度的基本单位。
- 由于把进程的结构进行了细化,通过线程来表示对处理器的虚拟化,使得进程成为了管理线程的容器。 在进程中的线程没有父子关系,大家都是兄弟,但还是有个老大。这个代表老大的线程其实就是创建进程(比如通过 fork 系统调用创建进程)时,建立的 第一个线程,它的线程标识符(TID)为 0 。
1.2 线程模型与重要系统调用
- 目前,我们只介绍本章实现的内核中采用的一种非常简单的线程模型。这个线程模型有三个运行状态: 就绪态、运行态和等待态;共享所属进程的地址空间和其他共享资源(如文件等);可被操作系统调度来分时占用CPU执行; 可以动态创建和退出;可通过系统调用获得操作系统的服务。我们实现的线程模型建立在进程的地址空间抽象之上: 每个线程都共享进程的代码段和和可共享的地址空间(如全局数据段、堆等),但有自己的独占的栈。 线程模型需要操作系统支持一些重要的系统调用:创建线程、等待子线程结束等,来支持灵活的多线程应用。 接下来会介绍这些系统调用的基本功能和设计思路。
1.2.1 线程创建系统调用
- 在一个进程的运行过程中,进程可以创建多个属于这个进程的线程,每个线程有自己的 线程标识符(TID,Thread Identifier)。 系统调用 thread_create 的原型如下:
- 当进程调用 thread_create 系统调用后,内核会在这个进程内部创建一个新的线程,这个线程能够访问到进程所拥有的代码段, 堆和其他数据段。但 内核会给这个新线程分配一个它专有的用户态栈,这样每个线程才能相对独立地被调度和执行。 另外,由于用户态进程与内核之间有各自独立的页表,所以二者需要有一个 跳板页 TRAMPOLINE 来 处理用户态切换到内核态的地址空间平滑转换的事务,所以当出现线程后,在进程中的每个线程也需要有一个独立的跳板页 TRAMPOLINE 来完成同样的事务。
/// 功能:当前进程创建一个新的线程
/// 参数:entry 表示线程的入口函数地址
/// 参数:arg:表示线程的一个参数
int sys_thread_create(uint64 entry, uint64 arg)
- 相比于创建进程的 fork 系统调用,创建线程不需要要建立新的地址空间,这是二者之间最大的不同。 另外属于同一进程中的线程之间没有父子关系,这一点也与进程不一样。
1.2.2 等待子线程系统调用
- 当一个线程执行完代表它的功能后,会通过 exit 系统调用退出,内核在收到线程发出的 exit 系统调用后, 会回收线程占用的部分资源,即用户态用到的资源,比如用户态的栈,用于系统调用和异常处理的跳板页等。 而该线程的内核态用到的资源,比如内核栈等,需要通过进程/主线程调用 waittid 来回收了, 这样整个线程才能被彻底销毁。系统调用 waittid 的原型如下:
/// 参数:tid表示线程id
/// 返回值:如果线程不存在,返回-1;如果线程还没退出,返回-2;其他情况下,返回结束线程的退出码
int sys_waittid(int tid);
- 一般情况下进程/主线程要负责通过 waittid 来等待它创建出来的线程(不是主线程)结束并回收它们在内核中的资源 (如线程的内核栈、线程控制块等)。如果进程/主线程先调用了 exit 系统调用来退出,那么整个进程 (包括所属的所有线程)都会退出,而对应父进程会通过 waitpid 回收子进程剩余还没被回收的资源。
1.2.3 进程相关的系统调用
- 在引入了线程机制后,进程相关的重要系统调用: fork 、 exec 、 waitpid 虽然在接口上没有变化, 但在它要完成的功能上需要有一定的扩展。首先,需要注意到把以前进程中与处理器执行相关的部分拆分到线程中。这样,在通过 fork 创建进程其实也意味着要单独建立一个主线程来使用处理器,并为以后创建新的线程建立相应的线程控制块向量。 相对而言, exec 和 waitpid 这两个系统调用要做的改动比较小,还是按照与之前进程的处理方式来进行。总体上看, 进程相关的这三个系统调用还是保持了已有的进程操作的语义,并没有由于引入了线程,而带来大的变化。
1.3 应用程序示例
- 我们刚刚介绍了 thread_create/waittid 两个重要系统调用,我们可以借助它们和之前实现的系统调用, 开发出功能更为灵活的应用程序。下面我们通过描述一个多线程应用程序 threads 的开发过程来展示这些系统调用的使用方法。
1.3.1 系统调用封装
- 可以在 user/lib/syscall.c 中看到系统调用的封装:
- waittid 等待一个线程标识符的值为 tid 的线程结束。在具体实现方面,我们看到当 sys_waittid 返回值为 -2 ,即要等待的线程存在但它却尚未退出的时候,主线程调用 yield_ 主动交出 CPU 使用权,待下次 CPU 使用权被内核交还给它的时候再次调用 sys_waittid 查看要等待的线程是否退出。这样做是为了减小 CPU 资源的浪费。这种方法是为了尽可能简化内核的实现。
- 特别的,注意这里 thread_create 中有一个全局变量 buffer_lock_enabled 的判断,这是因为我们的输出使用了输出缓冲区,在旧版本里它没有考虑线程安全性,为了在多线程模式下正常使用缓冲区,我们新增了一个互斥锁用于输出,这一模式会在主线程首次调用 thread_create 时被启用。
int thread_create(void *entry, void *arg)
{// on first thread create enable, here must be single threadif (!buffer_lock_enabled) {enable_thread_io_buffer();}return syscall(SYS_thread_create, (uint64)entry, (uint64)arg);
}int waittid(int tid)
{int ret = syscall(SYS_waittid, tid);while (ret == -2) {sched_yield();ret = syscall(SYS_waittid, tid);}return ret;
}
1.3.2 多线程应用程序 – threads
- 多线程应用程序 – threads 开始执行后,先调用 thread_create 创建了三个线程,加上进程自带的主线程,其实一共有四个线程。每个线程在打印了1000个字符后,会执行 exit 退出。进程通过 waittid 等待这三个线程结束后,最终结束进程的执行。下面是多线程应用程序 – threads 的源代码:
//user/src/ch8b_threads.c
...
#define LOOP 1000
#define NTHREAD 3void thread_a()
{for (int i = 0; i < LOOP; ++i) {putchar('a');}exit(1);
}void thread_b()
{for (int i = 0; i < LOOP; ++i) {putchar('b');}exit(2);
}void thread_c()
{for (int i = 0; i < LOOP; ++i) {putchar('c');}exit(3);
}int main(void)
{int tids[NTHREAD];tids[0] = thread_create(thread_a, 0);tids[1] = thread_create(thread_b, 0);tids[2] = thread_create(thread_c, 0);for (int i = 0; i < NTHREAD; ++i) {int tid = tids[i];int exit_code = waittid(tid);printf("thread %d exited with code %d\n", tid, exit_code);assert_eq(tid, exit_code);}puts("threads test passed!");return 0;
}
1.4 线程管理的核心数据结构
- 为了在现有进程管理的基础上实现线程管理,我们需要改进一些数据结构包含的内容及接口。 基本思路就是把进程中与处理器相关的部分分拆出来,形成线程相关的部分。
- 本节将按照如下顺序来进行介绍:
- 线程控制块 thread :表示线程的核心数据结构。
- 调度器 scheduler :用于线程调度。
1.4.1 线程控制块
- 在内核中,每个线程的执行状态和线程上下文等均保存在一个被称为线程控制块 的结构中,它是内核对线程进行管理的核心数据结构。在内核看来,它就等价于一个线程。
struct thread {enum threadstate state; // Thread stateint tid; // Thread IDstruct proc *process;uint64 ustack; // Virtual address of user stackuint64 kstack; // Virtual address of kernel stackstruct trapframe *trapframe; // data page for trampoline.Sstruct context context; // swtch() here to run processuint64 exit_code;
};
- 之前进程中的定义不存在的:
- tid:线程标识符
- process:线程所属的进程
- 与之前进程中的定义相同/类似的部分:
- trapframe 线程的 Trap 上下文在内核中的地址。
- context 保存暂停线程的线程上下文,用于线程切换。
- state 维护当前线程的执行状态。
- exit_code 线程退出码。
1.4.2 包含线程的进程控制块
- 把线程相关数据单独组织成数据结构后,进程的结构也需要进行一定的调整:
从中可以看出,进程把与处理器执行相关的部分都移到了 thread 中,并组织为一个线程控制块数组, 这就自然对应到多个线程的管理上了。此外由于多个线程拥有各自不同的用户栈空间, 需要在进程控制块中记录用户栈的基地址,每个线程的用户栈基地址为 ustack_base + tid * USTACK_SIZE 。
// Per-process state
struct proc {...uint64 ustack_base; // Virtual address of user stack basestruct thread threads[NTHREAD];
};
1.5 线程管理机制的设计与实现
- 在上述线程模型和内核数据结构的基础上,我们还需完成线程管理的基本实现,从而构造出一个完整的“达科塔盗龙”操作系统。 本节将分析如何实现线程管理:
- 线程创建、线程退出与等待线程结束
- 线程执行中的特权级切换
1.5.1线程创建、线程退出与等待线程结束
1.5.1.1 线程创建
- 当一个进程执行中发出了创建线程的系统调用 sys_thread_create 后,操作系统就需要在当前进程的基础上创建一个线程了, 这里重点是需要了解初始化线程控制块的各个成员变量,建立好进程和线程的关系等。只有建立好这些成员变量, 才能给线程建立一个灵活方便的执行环境。这里列出支持线程正确运行所需的重要的执行环境要素:
- 线程的用户态栈:确保在用户态的线程能正常执行函数调用;
- 线程的内核态栈:确保线程陷入内核后能正常执行函数调用;
- 线程的跳板页:确保线程能正确的进行用户态<–>内核态切换;
- 线程上下文:即线程用到的寄存器信息,用于线程切换。
- 线程创建的具体实现如下:
- 第 4 行,找到当前正在执行的线程所属的进程 p 。
- 第 5 行,调用 allocthread 函数,创建一个新的线程,线程编号 tid 即为该函数的返回值。在创建过程中, 建立与进程 p 的所属关系,分配了线程用户态栈、内核态栈、用于异常/中断的跳板页,设置线程的函数入口点、 任务上下文、内核栈和用户栈地址。
- 第 11-12 行,设置线程的传入参数,并将其状态设为可被调度运行。
- 第 13 行,把线程挂到调度队列中。
1// os/syscall.c2int sys_thread_create(uint64 entry, uint64 arg)3{4 struct proc *p = curr_proc();5 int tid = allocthread(p, entry, 1);6 if (tid < 0) {7 errorf("fail to create thread");8 return -1;9 }
10 struct thread *t = &p->threads[tid];
11 t->trapframe->a0 = arg;
12 t->state = RUNNABLE;
13 add_task(t);
14 return tid;
15}
1.5.1.2 线程退出
- 当一个非主线程的其他线程发出 sys_exit 系统调用时,内核会调用 exit 函数退出当前线程并切换到下一个线程,但不会导致其所属进程的退出。当 主线程 即进程发出这个系统调用, 内核会回收整个进程(这包括了其管理的所有线程)资源,并退出。具体实现如下:
- 第 10 行,调用 freethread 回收线程的各种资源。
- 第 11-26 行,如果是主线程发出的退出请求,则回收整个进程的部分资源,并退出进程。第 20-25 行所做的事情是将当前进程的所有子进程的父进程置为 NULL。
- 第 27 行,进行线程调度切换。
- 很大一部分与第五章讲解的 进程的退出 的功能实现大致相同。
1// os/proc.c2void exit(int code)3{4 struct proc *p = curr_proc();5 struct thread *t = curr_thread();6 t->exit_code = code;7 t->state = EXITED;8 int tid = t->tid;9 debugf("thread exit with %d", code);
10 freethread(t);
11 if (tid == 0) {
12 p->exit_code = code;
13 freeproc(p);
14 debugf("proc exit");
15 if (p->parent != NULL) {
16 // Parent should `wait`
17 p->state = ZOMBIE;
18 }
19 // Set the `parent` of all children to NULL
20 struct proc *np;
21 for (np = pool; np < &pool[NPROC]; np++) {
22 if (np->parent == p) {
23 np->parent = NULL;
24 }
25 }
26 }
27 sched();
28}
1.5.1.3 等待线程结束
- 主线程通过系统调用 sys_waittid 来等待其他线程的结束。具体实现如下:
- 第 4-11 行,如果是线程等待一个不存在的 tid 或自己,则返回错误.
- 第 12-14 行,如果 tid 对应的线程还未退出,则返回错误。
- 第 16-18 行,对应的线程已经退出,则将该线程的线程控制块标记为已释放,并返回该线程的退出码。
1// os/syscall.c2int sys_waittid(int tid)3{4 if (tid < 0 || tid >= NTHREAD) {5 errorf("unexpected tid %d", tid);6 return -1;7 }8 struct thread *t = &curr_proc()->threads[tid];9 if (t->state == T_UNUSED || tid == curr_thread()->tid) {
10 return -1;
11 }
12 if (t->state != EXITED) {
13 return -2;
14 }
15 memset((void *)t->kstack, 7, KSTACK_SIZE);
16 t->tid = -1;
17 t->state = T_UNUSED;
18 return t->exit_code;
19}
1.5.2 线程执行中的特权级切换和调度切换
- 线程执行中的特权级切换与第三章中 多道程序与协作式调度 小节中讲解的过程是一致的, 而线程执行中的调度切换过程与第五章的 进程管理的核心数据结构 小节中讲解的过程是一致的。 这里就不用再赘述一遍了。
【 2. 锁机制 】
- 到目前为止,我们已经实现了进程和线程,也能够理解 在一个时间段内,会有多个线程在执行,这就是并发。 而且,由于线程的引入,多个线程可以共享进程中的全局数据。如果多个线程都想读和更新全局数据, 那么谁先更新取决于操作系统内核的抢占式调度和分派策略。在一般情况下,每个线程都有可能先执行, 且可能由于中断等因素,随时被操作系统打断其执行,而切换到另外一个线程运行, 形成在一段时间内,多个线程交替执行的现象。如果没有一些保障机制(比如互斥、同步等), 那么这些对共享数据进行读写的交替执行的线程,其期望的共享数据的正确结果可能无法达到。
- 所以,我们需要研究一种保障机制 — 锁 , 确保无论操作系统如何抢占线程,调度和切换线程的执行, 都可以保证对拥有锁的线程,可以独占地对共享数据进行读写,从而能够得到正确的共享数据结果。 这种机制的 能力来自于处理器的指令、操作系统系统调用的基本支持,从而能够保证线程间互斥地读写共享数据。 下面各个小节将从为什么需要锁、锁的基本思路、锁的不同实现方式等逐步展开讲解。
2.1 为什么需要锁
- 没有保障机制的多个线程,在对共享数据进行读写的过程中,可能得不到预期的结果。 我们来看看这个简单的例子:
// 线程的入口函数
int a=0;
void f() {a = a + 1;
}
- 对于上述函数中的第 4 行代码,一般人理解处理器会一次就执行完这条简单的语句,但实际情况并不是这样。 我们可以用 GCC 编译出上述函数的汇编码:
cpp1$ riscv64-unknown-elf-gcc -o f.s -S f.c,可以看到生成的汇编代码如下:- 从中可以看出,对于高级语言的一条简单语句(C 代码的第 4 行,对全局变量进行读写),很可能是由多条汇编代码 (汇编代码的第 18到23 行)组成。如果这个函数是多个线程要执行的函数,那么在上述汇编代码第 18 行到第 23 行中的各行之间,可能会发生中断,从而导致操作系统执行抢占式的线程调度和切换, 就会得到不一样的结果。由于执行这段汇编代码(第 18到23 行))的 多个线程在访问全局变量过程中可能导致竞争状态, 因此我们将此段代码称为 临界区(critical section), 临界区是访问共享变量(或共享资源)的代码片段, 不能由多个线程同时执行,即需要保证互斥。
1//f.s2 .text3 .globl a4 .section .sbss,"aw",@nobits5 .align 26 .type a, @object7 .size a, 48a:9 .zero 4
10 .text
11 .align 1
12 .globl f
13 .type f, @function
14f:
15 addi sp,sp,-16
16 sd s0,8(sp)
17 addi s0,sp,16
18 lui a5,%hi(a)
19 lw a5,%lo(a)(a5)
20 addiw a5,a5,1
21 sext.w a4,a5
22 lui a5,%hi(a)
23 sw a4,%lo(a)(a5)
24 nop
25 ld s0,8(sp)
26 addi sp,sp,16
- 下面是有两个线程T0、T1在一个时间段内的一种可能的执行情况:
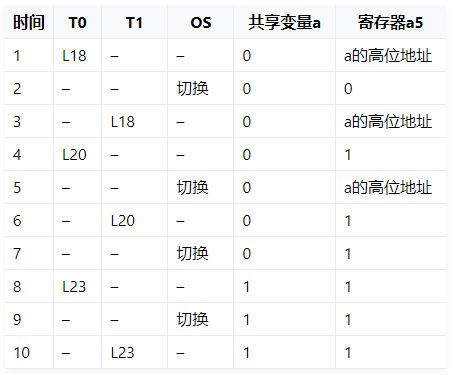
- 一般情况下,线程 T0 执行完毕后,再执行线程 T1,那么共享全局变量 a 的值为 2 。但在上面的执行过程中, 可以看到在线程执行指令的过程中会发生线程切换,这样在时刻 10 的时候,共享全局变量 a 的值为 1 , 这不是我们预期的结果。出现这种情况的原因是 两个线程在操作系统的调度下(在哪个时刻调度具有不确定性), 交错执行 a = a + 1 的不同汇编指令序列,导致虽然增加全局变量 a 的代码被执行了两次, 但结果还是只增加了 1 。这种多线程的最终执行结果 不确定(indeterminate),取决于由于调度导致的、 不确定指令执行序列的情况就是 竞态条件(race condition)。
- 如果每个线程在执行 a = a + 1 这个 C 语句所对应多条汇编语句过程中,不会被操作系统切换, 那么就不会出现多个线程交叉读写全局变量的情况,也就不会出现结果不确定的问题了。所以,访问(特指写操作)共享变量代码片段,不能由多个线程同时执行(即并行)或者在一个时间段内都去执行 (即并发)。要做到这一点,需要互斥机制的保障。从某种角度上看,这种互斥性也是一种 原子性, 即 线程在临界区的执行过程中,不会出现只执行了一部分,就被打断并切换到其他线程执行的情况。即, 要么线程执行的这一系列操作/指令都完成,要么这一系列操作/指令都不做,不会出现指令序列执行中被打断的情况。
2.2 锁的基本思路
- 要保证多线程并发执行中的临界区的代码具有互斥性或原子性,我们可以建立一种锁, 只有拿到锁的线程才能在临界区中执行。这里的锁与现实生活中的锁的含义很类似。比如,我们可以写出如下的伪代码:
lock(mutex); // 尝试取锁
a = a + 1; // 临界区,访问临界资源 a
unlock(mutex); // 是否锁
... // 剩余区
- 对于一个应用程序而言,它的执行是受到其执行环境的管理和限制的,而执行环境的主要组成就是用户态的系统库、 操作系统和更底层的处理器,这说明我们 需要有硬件和操作系统来对互斥进行支持。一个自然的想法是,这个 lock/unlock 互斥操作就是CPU提供的机器指令,那上面这一段程序就很容易在计算机上执行了。 但需要注意,这里 互斥的对象是线程的临界区代码,而临界区代码可以访问各种共享变量(简称临界资源)。 只靠两条机器指令,难以识别各种共享变量,不太可能约束可能在临界区的各种指令执行共享变量操作的互斥性。 所以,我们还是需要有一些相对更灵活和复杂一点的方法,能够 设置一种所有线程能看到的标记, 在一个能进入临界区的线程设置好这个标记后,其他线程都不能再进入临界区了。总体上看, 对临界区的访问过程分为四个部分:
- 1.尝试取锁:查看锁是否可用,即临界区是否可访问(看占用临界区标志是否被设置),如果可以访问, 则设置占用临界区标志(锁不可用)并转到步骤 2 ,否则线程忙等或被阻塞;
- 2.临界区: 访问临界资源的系列操作
- 3.释放锁: 清除占用临界区标志(锁可用),如果有线程被阻塞,会唤醒阻塞线程;
- 4.剩余区: 与临界区不相关部分的代码
- 根据上面的步骤,可以看到锁机制有两种:让线程忙等的 忙等锁(spin lock),以及让线程阻塞的 睡眠锁 (sleep lock)。锁的实现大体上基于三类机制:用户态软件、机器指令硬件、内核态操作系统。 下面我们介绍来 rCore 中基于内核态操作系统级方法实现的支持互斥的锁。
- 我们还需要知道如何评价各种锁实现的效果。一般我们需要关注锁的三种属性:
- 互斥性(mutual exclusion),即锁是否能够有效阻止多个线程进入临界区,这是最基本的属性。
- 公平性(fairness),当锁可用时,每个竞争线程是否有公平的机会抢到锁。
- 性能(performance),即使用锁的时间开销。
2.3 内核态操作系统级方法实现锁 — mutex 系统调用
2.3.1 使用 mutex 系统调用
- 如何能够实现轻量的可睡眠锁?一个自然的想法就是, 让等待锁的线程睡眠,让释放锁的线程显式地唤醒等待锁的线程。 如果有多个等待锁的线程,可以全部释放,让大家再次竞争锁;也可以只释放最早等待的那个线程。 这就需要更多的操作系统支持,特别是需要一个等待队列来保存等待锁的线程。
- 我们先看看多线程应用程序如何使用mutex系统调用的:
- 第24行,创建了一个ID为 mutex_id 的互斥锁,对应的是第35行 SYS_mutex_create 系统调用;
- 第10行,尝试获取锁(对应的是第45行 SYS_mutex_lock 系统调用),如果取得锁, 将继续向下执行临界区代码;如果没有取得锁,将阻塞;
- 第16行,释放锁(对应的是第50行 SYS_mutex_unlock 系统调用),如果有等待在该锁上的线程, 则唤醒这些等待线程。
1// user/src/ch8b_mut_race.c2...3int mutex_id;4int a;5int threads[thread_count];6void fun(long i)7{8 int t = i + 1;9 for (int i = 0; i < per_thread; i++) {
10 assert_eq(mutex_lock(mutex_id), 0);
11 int old_a = a;
12 for (int i = 0; i < 500; i++) {
13 t = t * t % 10007;
14 }
15 a = old_a + 1;
16 assert_eq(mutex_unlock(mutex_id), 0);
17 }
18 exit(t);
19}
20
21int main()
22{
23 int64 start = get_mtime();
24 assert((mutex_id = mutex_blocking_create()) >= 0);
25 for (int i = 0; i < thread_count; i++) {
26 threads[i] = thread_create(fun, (void *)i);
27 assert(threads[i] > 0);
28 }
29 ...
30}
31
32// usr/lib/syscall.c
33int mutex_create()
34{
35 return syscall(SYS_mutex_create, 0);
36}
37
38int mutex_blocking_create()
39{
40 return syscall(SYS_mutex_create, 1);
41}
42
43int mutex_lock(int mid)
44{
45 return syscall(SYS_mutex_lock, mid);
46}
47
48int mutex_unlock(int mid)
49{
50 return syscall(SYS_mutex_unlock, mid);
51}
2.3.2 mutex 系统调用的实现
- 操作系统如何实现这些系统调用呢?首先考虑一下与此相关的核心数据结构, 然后考虑与数据结构相关的相关函数/方法的实现。
注解
互斥锁根据 lock 一个已被占用的锁时的行为也分 阻塞互斥锁(blocking mutex)与 自旋互斥锁(spinning mutex), 下文我们主要聚焦阻塞互斥锁,但是 ucore 里两者都通过结构体 struct mutex 与几个函数的不同分支实现。
- 在线程的眼里, 互斥 是一种每个线程能看到的资源,且在一个进程中,可以存在多个不同互斥资源, 所以我们可以把所有的互斥资源放在一起让进程来管理,如下面代码第 4 行所示。这里需要注意的是: struct mutex mutex_pool[LOCK_POOL_SIZE] 表示的是实现了 mutex 的一个“互斥资源”的内存池。而 struct mutex 是会实现 mutex 的内核数据结构,它就是我们提到的 互斥资源 即 互斥锁 。操作系统需要显式地施加某种控制,来确定当一个线程释放锁时,等待的线程谁将能抢到锁。 为了做到这一点,操作系统需要有一个等待队列来保存等待锁的线程,如下面代码的第 10 行所示。
1struct proc {2 ...3 uint next_mutex_id;4 struct mutex mutex_pool[LOCK_POOL_SIZE];5};67struct mutex {8 uint blocking;9 uint locked;
10 struct queue wait_queue;
11 // "alloc" data for wait queue
12 int _wait_queue_data[WAIT_QUEUE_MAX_LENGTH];
13};
- 这样,在操作系统中,需要设计实现几个核心成员变量。互斥锁的成员变量有四个:表示是阻塞锁还是自旋锁的 blocking, 是否锁上的 locked,和(阻塞锁会用到的)管理等待线程的等待队列 wait_queue 及其内存单元 _wait_queue_data; 进程的成员变量:锁内存池 mutex_pool 及记录互斥锁分配情况的 next_mutex_id。
- 首先需要创建一个互斥锁,下面是应对 SYSCALL_MUTEX_CREATE 系统调用的创建互斥锁的函数:
- 第16~19行,互斥锁池还没用完,就找下一个可行的锁,否则返回NULL。
1// os/syscall.c2int sys_mutex_create(int blocking)3{4 struct mutex *m = mutex_create(blocking);5 if (m == NULL) {6 return -1;7 }8 int mutex_id = m - curr_proc()->mutex_pool;9 return mutex_id;
10}
11
12// os/sync.c
13struct mutex *mutex_create(int blocking)
14{
15 struct proc *p = curr_proc();
16 if (p->next_mutex_id >= LOCK_POOL_SIZE) {
17 return NULL;
18 }
19 struct mutex *m = &p->mutex_pool[p->next_mutex_id];
20 p->next_mutex_id++;
21 m->blocking = blocking;
22 m->locked = 0;
23 if (blocking) {
24 // blocking mutex need wait queue but spinning mutex not
25 init_queue(&m->wait_queue, WAIT_QUEUE_MAX_LENGTH,
26 m->_wait_queue_data);
27 }
28 return m;
29}
- 有了互斥锁,接下来就是实现 Mutex 的内核函数:对应 SYSCALL_MUTEX_LOCK 系统调用的 sys_mutex_lock 。操作系统主要工作是,在锁已被其他线程获取的情况下,把当前线程放到等待队列中, 并调度一个新线程执行。主要代码如下:
- 第 7 行,以 ID 为 mutex_id 的互斥锁指针 m 为参数调用 mutex_lock 方法,具体工作由该方法来完成。
- 第 18 行,分类讨论了自旋互斥锁的实现细节,这里我们聚焦阻塞互斥锁,省略了这一分支的细节;
- 第 14 行,如果互斥锁 m 已经被其他线程获取了,那么在第 23 行,将把当前线程放入等待队列中; 在第 25~26 行,让当前线程处于等待状态,并调度其他线程执行。
- 第 15~16 行,如果互斥锁 m 还没被获取,那么当前线程会获取给互斥锁,并返回系统调用。
1// os/syscall.c2int sys_mutex_lock(int mutex_id)3{4 if (mutex_id < 0 || mutex_id >= curr_proc()->next_mutex_id) {5 return -1;6 }7 mutex_lock(&curr_proc()->mutex_pool[mutex_id]);8 return 0;9}
10
11// os/sync.c
12void mutex_lock(struct mutex *m)
13{
14 if (!m->locked) {
15 m->locked = 1;
16 return;
17 }
18 if (!m->blocking) {
19 ...
20 }
21 // blocking mutex will wait in the queue
22 struct thread *t = curr_thread();
23 push_queue(&m->wait_queue, task_to_id(t));
24 // don't forget to change thread state to SLEEPING
25 t->state = SLEEPING;
26 sched();
27 // here lock is released (with locked = 1) and passed to me, so just do nothing
28}
- 最后是实现 Mutex 的内核函数:对应 SYSCALL_MUTEX_UNLOCK 系统调用的 sys_mutex_unlock 。 操作系统的主要工作是,如果有等待在这个互斥锁上的线程,需要唤醒最早等待的线程。主要代码如下:
- 第 7 行,以 ID 为 mutex_id 的互斥锁 m 为参数调用 mutex_unlock 方法,具体工作由该方法来完成的。
- 第 18 行,如果等待队列为空,直接释放锁。
- 第 21-22 行,如果等待队列非空,则唤醒等待最久的线程 t,注意这里不改变 m->locked,可以想想为什么(实验问答题之一)。
1// os/syscall.c2int sys_mutex_unlock(int mutex_id)3{4 if (mutex_id < 0 || mutex_id >= curr_proc()->next_mutex_id) {5 return -1;6 }7 mutex_unlock(&curr_proc()->mutex_pool[mutex_id]);8 return 0;9}
10
11// os/sync.c
12void mutex_unlock(struct mutex *m)
13{
14 if (m->blocking) {
15 struct thread *t = id_to_task(pop_queue(&m->wait_queue));
16 if (t == NULL) {
17 // Without waiting thread, just release the lock
18 m->locked = 0;
19 } else {
20 // Or we should give lock to next thread
21 t->state = RUNNABLE;
22 add_task(t);
23 }
24 } else {
25 m->locked = 0;
26 }
27}
【 3. 信号量机制 】
- 在上一节中,我们介绍了互斥锁(mutex 或 lock)的起因、使用和实现过程。 通过互斥锁, 可以让线程在临界区执行时,独占临界资源。当我们需要更灵活的互斥访问或同步操作方式,如 提供了最多只允许 N 个线程访问临界资源的情况,让某个线程等待另外一个线程执行完毕后再继续执行的同步过程 等, 互斥锁这种方式就有点力不从心了。
- 在本节中,将介绍功能更加强大和灵活的同步互斥机制 – 信号量(Semaphore),它的设计思路、 使用和在操作系统中的具体实现。可以看到,信号量的实现需要互斥锁和处理器原子指令的支持, 它是一种更高级的同步互斥机制。
3.1 信号量的起源和基本思路
-
历史背景
1963 年前后,当时的数学家(其实是计算机科学家)Edsger Dijkstra 和他的团队在为 Electrologica X8 计算机开发一个操作系统(称为 THE multiprogramming system,THE 多道程序系统)的过程中,提出了 信号量 (Semphore)是一种变量或抽象数据类型, 用于控制多个线程对共同资源的访问。Dijkstra 对信号量设计了两种操作:P(Proberen(荷兰语),尝试)操作和 V(Verhogen(荷兰语),增加)操作。- P 尝试操作是检查信号量的值是否大于 0,若该值大于 0,则将其值减 1 并继续(表示可以进入临界区了);若该值为 0,则线程将睡眠。注意,此时 P 操作还未结束。而且由于信号量本身是一种临界资源(可回想一下上一节的锁, 其实也是一种临界资源),所以在 P 操作中,检查/修改信号量值以及可能发生的睡眠这一系列操作, 是一个不可分割的原子操作过程。通过原子操作才能保证,一旦 P 操作开始,则在该操作完成或阻塞睡眠之前, 其他线程均不允许访问该信号量。
- V 操作会对信号量的值加 1 ,然后检查是否有一个或多个线程在该信号量上睡眠等待。如有, 则选择其中的一个线程唤醒并允许该线程继续完成它的 P 操作;如没有,则直接返回。注意,信号量的值加 1, 并可能唤醒一个线程的一系列操作同样也是不可分割的原子操作过程。不会有某个进程因执行 V 操作而阻塞。
-
信号量是对互斥锁的一种巧妙的扩展。上一节中的互斥锁的初始值一般设置为 1 的整型变量, 表示临界区还没有被某个线程占用。互斥锁用 0 表示临界区已经被占用了,用 1 表示临界区为空,再通过 lock/unlock 操作来协调多个线程轮流独占临界区执行。而 信号量的初始值可设置为 N 的整数变量, 如果 N 大于 0, 表示最多可以有 N 个线程进入临界区执行,如果 N 小于等于 0 ,表示不能有线程进入临界区了, 必须在后续操作中让信号量的值加 1 ,才能唤醒某个等待的线程。
-
如果信号量是一个任意的整数,通常被称为 计数信号量(Counting Semaphore),或 一般信号量(General Semaphore);如果信号量只有0或1的取值,则称为 二值信号量(Binary Semaphore)。可以看出, 互斥锁是信号量的一种特例:二值信号量, 信号量很好地解决了最多允许 N 个线程访问临界资源的情况。
-
信号量的一种实现伪代码如下所示:
S 的取值范围为大于等于 0 的整数。S 的初值一般设置为一个大于 0 的正整数, 表示可以进入临界区的线程数。当 S 取值为 1,表示是二值信号量,也就是互斥锁了。
1void P(S) {2 if (S >= 1)3 S = S - 1;4 else5 <block and enqueue the thread>;6}7void V(S) {8 if <some threads are blocked on the queue>9 <unblock a thread>;
10 else
11 S = S + 1;
12}
- 使用信号量实现线程互斥访问临界区的伪代码如下:
1static struct semaphore S = {1};23// Thread i4void foo() {5 ...6 P(S);7 execute Cricital Section;8 V(S);9 ...
10}
- 下面是另外一种信号量实现的伪代码:
在这种实现中,S 的初值一般设置为一个大于 0 的正整数,表示可以进入临界区的线程数。但 S 的取值范围可以是小于 0 的整数,表示等待进入临界区的睡眠线程数。
1void P(S) {2 S = S - 1;3 if (S < 0)4 <block and enqueue the thread>;5}67void V(S) {8 S = S + 1;9 if <some threads are blocked on the queue>
10 <unblock a thread>;
11}
- 信号量的另一种用途是用于实现 同步(synchronization)。比如,把信号量的初始值设置为 0 , 当一个线程 A 对此信号量执行一个 P 操作,那么该线程立即会被阻塞睡眠。之后有另外一个线程 B 对此信号量执行一个 V 操作,就会将线程 A 唤醒。这样线程 B 中执行 V 操作之前的代码序列 B-stmts 和线程 A 中执行 P 操作之后的代码 A-stmts 序列之间就形成了一种确定的同步执行关系,即线程 B 的 B-stmts 会先执行,然后才是线程 A 的 A-stmts 开始执行。相关伪代码如下所示:
1static struct semaphore S = {1};2//Thread A3...4P(S);5Label_2:6A-stmts after Thread B::Label_1;7...89//Thread B
10...
11B-stmts before Thread A::Label_2;
12Label_1:
13V(S);
14...
3.2 实现信号量
3.2.1 使用 semaphore 系统调用
- 我们通过例子来看看如何实际使用信号量。下面是面向应用程序对信号量系统调用的简单使用, 可以看到对它的使用与上一节介绍的互斥锁系统调用类似。在这个例子中,主线程先创建了信号量初值为 0 的信号量 SEM_SYNC ,然后再创建两个线程 First 和 Second 。线程 First 会先睡眠 10ms,而当线程 Second 执行时,会由于执行信号量的 P 操作而等待睡眠;当线程 First 醒来后,会执行 V 操作,从而能够唤醒线程 Second。这样线程 First 和线程 Second 就形成了一种稳定的同步关系。
- 第 16 行,创建了一个初值为 0 ,ID 为 SEM_SYNC 的信号量,对应的是第 23 行 SYS_semaphore_create 系统调用;
- 第 10 行,线程 Second 执行信号量 P 操作(对应第 33 行 SYS_semaphore_down 系统调用),由于信号量初值为 0 ,该线程将阻塞;
- 第 5 行,线程 First 执行信号量 V 操作(对应第 28 行 SYS_semaphore_up 系统调用), 会唤醒等待该信号量的线程 Second。
1const int SEM_SYNC = 0; //信号量ID2void first() {3 sleep(10);4 puts("First work and wakeup Second");5 semaphore_up(SEM_SYNC); //信号量V操作6 exit(0);7}8void second() {9 puts("Second want to continue,but need to wait first");
10 semaphore_down(SEM_SYNC); //信号量P操作
11 puts("Second can work now");
12 exit(0);
13}
14int main() {
15 // create semaphores
16 assert_eq(semaphore_create(0), SEM_SYNC); // 信号量初值为0
17 // create first, second threads
18 ...
19}
20
21int semaphore_create(int res_count)
22{
23 return syscall(SYS_semaphore_create, res_count);
24}
25
26int semaphore_up(int sid)
27{
28 return syscall(SYS_semaphore_up, sid);
29}
30
31int semaphore_down(int sid)
32{
33 return syscall(SYS_semaphore_down, sid);
34}
3.2.2 实现 semaphore 系统调用
- 操作系统如何实现信号量系统调用呢?我们还是采用通常的分析做法:数据结构+方法, 即首先考虑一下与此相关的核心数据结构,然后考虑与数据结构相关的相关函数/方法的实现。
- 在线程的眼里,信号量是一种每个线程能看到的共享资源,且 在一个进程中,可以存在多个不同信号量资源, 所以我们可以把所有的信号量资源放在一起让进程来管理,如下面代码第 4 行所示。这里需要注意的是: struct semaphore semaphore_pool[LOCK_POOL_SIZE] 表示的是信号量资源的列表。而 struct semaphore 是信号量的内核数据结构,由信号量值和等待队列组成。操作系统需要显式地施加某种控制,来确定当一个线程执行 P 操作和 V 操作时,如何让线程睡眠或唤醒线程。在这里,P 操作是由 semaphore_down 方法实现,而 V 操作是由 semaphore_up 方法实现。
- 首先是核心数据结构:
第 4 行,进程控制块中管理的信号量列表。
第 9~12 行,信号量的核心数据成员:信号量值和等待队列。 - 然后是重要的三个成员函数:
第 15 行,创建信号量,信号量初值为参数 res_count ,信号量池的使用原理同互斥锁。
第 28 行,实现 V 操作的 up 函数,第 31 行,当信号量值小于等于 0 时, 将从信号量的等待队列中弹出一个线程放入线程就绪队列。
第 39 行,实现 P 操作的 down 函数,第 225 行,当信号量值小于 0 时, 将把当前线程放入信号量的等待队列,设置当前线程为挂起状态并选择新线程执行。
- 首先是核心数据结构:
1struct proc {2 int pid; // Process ID3 uint next_semaphore_id;4 struct semaphore semaphore_pool[LOCK_POOL_SIZE];5 ...6};78struct semaphore {9 int count;
10 struct queue wait_queue;
11 // "alloc" data for wait queue
12 int _wait_queue_data[WAIT_QUEUE_MAX_LENGTH];
13};
14
15struct semaphore *semaphore_create(int count)
16{
17 struct proc *p = curr_proc();
18 if (p->next_semaphore_id >= LOCK_POOL_SIZE) {
19 return NULL;
20 }
21 struct semaphore *s = &p->semaphore_pool[p->next_semaphore_id];
22 p->next_semaphore_id++;
23 s->count = count;
24 init_queue(&s->wait_queue, WAIT_QUEUE_MAX_LENGTH, s->_wait_queue_data);
25 return s;
26}
27
28void semaphore_up(struct semaphore *s)
29{
30 s->count++;
31 if (s->count <= 0) {
32 // count <= 0 after up means wait queue not empty
33 struct thread *t = id_to_task(pop_queue(&s->wait_queue));
34 t->state = RUNNABLE;
35 add_task(t);
36 }
37}
38
39void semaphore_down(struct semaphore *s)
40{
41 s->count--;
42 if (s->count < 0) {
43 // s->count < 0 means need to wait (state=SLEEPING)
44 struct thread *t = curr_thread();
45 push_queue(&s->wait_queue, task_to_id(t));
46 t->state = SLEEPING;
47 sched();
48 }
49}
【 4. 条件变量机制 】
- 到目前为止,我们已经了解了操作系统提供的互斥锁和信号量。但 应用程序在使用互斥锁和信号量时需要非常小心, 如果使用不当,就会产生效率低下、竞态条件、死锁或者其他一些不可预测的情况。为了简化编程、避免错误, 计算机科学家针对某些情况设计了一种更高层的同步互斥原语。具体而言, 在有些情况下, 线程需要检查某一条件(condition)满足之后,才会继续执行。
- 我们来看一个例子,有两个线程 first 和 second 在运行,线程 first 会把全局变量 A 设置为 1,而线程 second 在 A != 0 的条件满足后,才能继续执行,如下面的伪代码所示:
如果线程 second 先执行,会忙等在 while 循环中,在操作系统的调度下,线程 first 会执行并把 A 赋值为 1 后,然后线程 second 再次执行时,就会跳出 while 循环,进行接下来的工作。
1static int A = 0;2void first() {3 A=1;4 ...5}67void second() {8 while (A==0) {9 // 忙等或睡眠等待 A==1
10 };
11 //继续执行相关事务
12}
- 配合互斥锁,可以正确完成上述带条件的同步流程,如下面的伪代码所示:
1static int A = 0;2void first() {3 mutex.lock();4 A=1;5 mutex.unlock();6 ...7}89void second() {
10 mutex.lock();
11 while A == 0 {
12 mutex.unlock();
13 // give other thread chance to lock
14 mutex.lock();
15 }
16 mutex.unlock();
17 //继续执行相关事务
18}
- 这种实现能执行,但效率低下,因为线程 second 会忙等检查,浪费处理器时间。我们希望有某种方式让线程 second 休眠,直到等待的条件满足,再继续执行。于是,我们可以写出如下的代码:
1static int A = 0;2void first() {3 mutex.lock();4 A=1;5 wakup(second);6 mutex.unlock();7 ...8}9
10void second() {
11 mutex.lock();
12 while (A==0) {
13 wait();
14 };
15 mutex.unlock();
16 //继续执行相关事务
17}
- 粗略地看,这样就可以实现睡眠等待了。但请同学仔细想想,当线程 second 在睡眠的时候, mutex 是否已经上锁了? 确实,线程 second 是带着上锁的 mutex 进入等待睡眠状态的, 如果这两个线程的调度顺序是先执行线程 second,再执行线程first,那么线程 second 会先睡眠且拥有 mutex 的锁;当线程 first 执行时,会由于没有 mutex 的锁而进入等待锁的睡眠状态。 结果就是两个线程都睡了,都执行不下去,这就出现了 死锁 。
- 这里需要解决的两个关键问题: 如何等待一个条件? 和 在条件为真时如何向等待线程发出信号 。 我们的计算机科学家给出了 管程(Monitor) 和 条件变量(Condition Variables) 这种巧妙的方法。接下来,我们就会深入讲解条件变量的设计与实现。
4.1 条件变量的基本思路
- 管程有一个很重要的特性,即 任一时刻只能有一个活跃线程调用管程中的过程, 这一特性使线程在调用执行管程中过程时能保证互斥,这样线程就可以放心地访问共享变量。 管程是编程语言的组成部分,编译器知道其特殊性,因此可以采用与其他过程调用不同的方法来处理对管程的调用. 因为是由编译器而非程序员来生成互斥相关的代码,所以出错的可能性要小。
- 管程虽然借助编译器提供了一种实现互斥的简便途径,但这还不够,还需要一种线程间的沟通机制。 首先是等待机制:由于线程在调用管程中某个过程时,发现某个条件不满足,那就在无法继续运行而被阻塞。 其次是唤醒机制:另外一个线程可以在调用管程的过程中,把某个条件设置为真,并且还需要有一种机制, 及时唤醒等待条件为真的阻塞线程。为了避免管程中同时有两个活跃线程, 我们需要一定的规则来约定线程发出唤醒操作的行为。目前有三种典型的规则方案:
- Hoare 语义:线程发出唤醒操作后,马上阻塞自己,让新被唤醒的线程运行。注:此时唤醒线程的执行位置还在管程中。
- Hansen 语义:是执行唤醒操作的线程必须立即退出管程,即唤醒操作只可能作为一个管程过程的最后一条语句。 注:此时唤醒线程的执行位置离开了管程。
- Mesa 语义:唤醒线程在发出行唤醒操作后继续运行,并且只有它退出管程之后,才允许等待的线程开始运行。 注:此时唤醒线程的执行位置还在管程中。
- 一般开发者会采纳 Brinch Hansen 的建议,因为它在概念上更简单,并且更容易实现。这种沟通机制的具体实现就是 条件变量 和对应的操作:wait 和 signal。线程使用条件变量来等待一个条件变成真。 条件变量其实是一个线程等待队列,当条件不满足时,线程通过执行条件变量的 wait 操作就可以把自己加入到等待队列中,睡眠等待(waiting)该条件。另外某个线程,当它改变条件为真后, 就可以通过条件变量的 signal 操作来唤醒一个或者多个等待的线程(通过在该条件上发信号),让它们继续执行。
- 早期提出的管程是基于 Concurrent Pascal 来设计的,其他语言如 C 和 Rust 等,并没有在语言上支持这种机制。 我们还是可以用手动加入互斥锁的方式来代替编译器,就可以在 C 和 Rust 的基础上实现原始的管程机制了。 在目前的 C 语言应用开发中,实际上也是这么做的。这样,我们就可以用互斥锁和条件变量, 来重现上述的同步互斥例子:
1static int A = 0;2void first() {3 mutex.lock();4 A=1;5 condvar.wakup();6 mutex.unlock();7 ...8}9
10void second() {
11 mutex.lock();
12 while (A==0) {
13 condvar.wait(mutex); //在睡眠等待之前,需要释放mutex
14 };
15 mutex.unlock();
16 //继续执行相关事务
17}
有了上面的介绍,我们就可以实现条件变量的基本逻辑了。下面是条件变量的 wait 和 signal 操作的伪代码:1void wait(mutex) {
2 mutex.unlock();
3 <block and enqueue the thread>;
4 mutex.lock();
5}
6
7void signal() {
8 <unblock a thread>;
9}
- 条件变量的wait操作包含三步,1. 释放锁;2. 把自己挂起;3. 被唤醒后,再获取锁。条件变量的 signal 操作只包含一步:找到挂在条件变量上睡眠的线程,把它唤醒。
- 注意,条件变量不像信号量那样有一个整型计数值的成员变量,所以条件变量也不能像信号量那样有读写计数值的能力。 如果一个线程向一个条件变量发送唤醒操作,但是在该条件变量上并没有等待的线程,则唤醒操作实际上什么也没做。
4.2 实现条件变量
4.2.1 使用 condvar 系统调用
- 我们通过例子来看看如何实际使用条件变量。下面是面向应用程序对条件变量系统调用的简单使用, 可以看到对它的使用与上一节介绍的信号量系统调用类似。 在这个例子中,主线程先创建了初值为 1 的互斥锁和一个条件变量,然后再创建两个线程 First 和 Second。线程 First 会先睡眠 10ms,而当线程 Second 执行时,会由于条件不满足执行条件变量的 wait 操作而等待睡眠;当线程 First 醒来后,通过设置 A 为 1,让线程 second 等待的条件满足,然后会执行条件变量的 signal 操作,从而能够唤醒线程 Second。 这样线程 First 和线程 Second 就形成了一种稳定的同步与互斥关系。
- 第 26 行,创建了一个 ID 为 CONDVAR_ID 的条件量,对应第 34 行 SYSCALL_CONDVAR_CREATE 系统调用;
- 第 19 行,线程 Second 执行条件变量 wait 操作(对应第 44 行 SYSCALL_CONDVAR_WAIT 系统调用), 该线程将释放 mutex 锁并阻塞;
- 第 5 行,线程 First 执行条件变量 signal 操作(对应第 39 行 SYSCALL_CONDVAR_SIGNAL 系统调用), 会唤醒等待该条件变量的线程 Second。
1static int A = 0; //全局变量23const int CONDVAR_ID = 0;4const int MUTEX_ID = 0;56void first() {7 sleep(10);8 puts("First work, Change A --> 1 and wakeup Second");9 mutex_lock(MUTEX_ID);
10 A = 1;
11 condvar_signal(CONDVAR_ID);
12 mutex_unlock(MUTEX_ID);
13 ...
14}
15void second() {
16 puts("Second want to continue,but need to wait A=1");
17 mutex_lock(MUTEX_ID);
18 while (A == 0) {
19 condvar_wait(CONDVAR_ID, MUTEX_ID);
20 }
21 mutex_unlock(MUTEX_ID);
22 ...
23}
24int main() {
25 // create condvar & mutex
26 assert_eq(condvar_create(), CONDVAR_ID);
27 assert_eq(mutex_blocking_create(), MUTEX_ID);
28 // create first, second threads
29 ...
30}
31
32int condvar_create()
33{
34 return syscall(SYS_condvar_create);
35}
36
37int condvar_signal(int cid)
38{
39 return syscall(SYS_condvar_signal, cid);
40}
41
42int condvar_wait(int cid, int mid)
43{
44 return syscall(SYS_condvar_wait, cid, mid);
45}
4.2.2 实现 condvar 系统调用
- 操作系统如何实现条件变量系统调用呢?在线程的眼里,条件变量是一种每个线程能看到的共享资源, 且在一个进程中,可以存在多个不同条件变量资源,所以我们可以把所有的条件变量资源放在一起让进程来管理, 如下面代码第9行所示。这里需要注意的是: condvar_list: Vec<Option<Arc>> 表示的是条件变量资源的列表。而 Condvar 是条件变量的内核数据结构,由等待队列组成。 操作系统需要显式地施加某种控制,来确定当一个线程执行 wait 操作和 signal 操作时, 如何让线程睡眠或唤醒线程。在这里, wait 操作是由 Condvar 的 wait 方法实现,而 signal 操作是由 Condvar 的 signal 方法实现。
- 首先是核心数据结构:
第 5 行,进程控制块中管理的条件变量列表。
第 13 行,条件变量的核心数据成员:等待队列。 - 然后是重要的三个成员函数:
第 17 行,创建条件变量,即创建了一个空的等待队列。
第 29 行,实现 signal 操作,将从条件变量的等待队列中弹出一个线程放入线程就绪队列。
第 38 行,实现 wait 操作,释放 m 互斥锁,将把当前线程放入条件变量的等待队列, 设置当前线程为挂起状态并选择新线程执行。在恢复执行后,再加上 m 互斥锁。
- 首先是核心数据结构:
1// os/proc.h2struct proc {3 int pid; // Process ID4 uint next_condvar_id;5 struct condvar condvar_pool[LOCK_POOL_SIZE];6 ...7};89// os/sync.h
10struct condvar {
11 struct queue wait_queue;
12 // "alloc" data for wait queue
13 int _wait_queue_data[WAIT_QUEUE_MAX_LENGTH];
14};
15
16// os/sync.c
17struct condvar *condvar_create()
18{
19 struct proc *p = curr_proc();
20 if (p->next_condvar_id >= LOCK_POOL_SIZE) {
21 return NULL;
22 }
23 struct condvar *c = &p->condvar_pool[p->next_condvar_id];
24 p->next_condvar_id++;
25 init_queue(&c->wait_queue, WAIT_QUEUE_MAX_LENGTH, c->_wait_queue_data);
26 return c;
27}
28
29void cond_signal(struct condvar *cond)
30{
31 struct thread *t = id_to_task(pop_queue(&cond->wait_queue));
32 if (t) {
33 t->state = RUNNABLE;
34 add_task(t);
35 }
36}
37
38void cond_wait(struct condvar *cond, struct mutex *m)
39{
40 // conditional variable will unlock the mutex first and lock it again on return
41 mutex_unlock(m);
42 struct thread *t = curr_thread();
43 // now just wait for cond
44 push_queue(&cond->wait_queue, task_to_id(t));
45 t->state = SLEEPING;
46 sched();
47 mutex_lock(m);
48}
这篇关于【Ucore操作系统】8. 并发的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








