本文主要是介绍【图像分类】2022-UniFormer IEEE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 2022-UniFormer IEEE
- 1. 简介
- 1.1 动机
- 2. 网络架构
- 2.1 整体架构
- 2.2 UniFormer block
- 2.3 MHRA
- 2.3.1 Local MHRA
- 2.3.2 Global MHRA
- 2.4 Dynamic Position Embedding
- 3. 代码
2022-UniFormer IEEE
论文题目:UniFormer: Unifying Convolution and Self-attention for Visual Recognition
论文链接: https://arxiv.org/abs/2201.09450
论文代码:https://github.com/sense-x/uniformer‘
发表时间:2022年1月
引用:Li K, Wang Y, Zhang J, et al. Uniformer: Unifying convolution and self-attention for visual recognition[J]. arXiv preprint arXiv:2201.09450, 2022.
引用数:24
网络翻译:https://blog.csdn.net/weixin_45782047/article/details/123952524
1. 简介
1.1 动机
对image和video上的representation learning而言,有两大痛点:
- local redundancy: 视觉数据在局部空间/时间/时空邻域具有相似性,这种局部性质容易引入大量低效的计算。
- global dependency: 要实现准确的识别,需要动态地将不同区域中的目标关联,建模长时依赖。
现有的两大主流模型CNN和ViT,往往只关注解决问题之一。convolution只在局部小邻域聚合上下文,天然地避免了冗余的全局计算,但受限的感受野难以建模全局依赖。而self-attention通过比较全局相似度,自然将长距离目标关联,但如下可视化可以发现,ViT在浅层编码局部特征十分低效。

DeiT可视化,可以看到即便是经过了三层的self-attention,输出特征仍保留了较多的局部细节。我们任选一个token作为query,可视化attention矩阵可以发现,被关注的token集中在3x3邻域中(红色越深关注越多)。

TimeSformer可视化,同样可以看到即便是经过了三层的self-attention,输出的每一帧特征仍保留了较多的局部细节。我们任选一个token作为query,可视化spatial attention和temporal attention矩阵都可以发现,被关注的token都只在局部邻域中(红色越深关注越多)。
无论是spatial attention抑或temporal attention,在ViT的浅层,都仅会倾向于关注query token的邻近token。要知道attention矩阵是通过全局token相似度计算得到的,这无疑带来了大量不必要的计算。相较而言,convolution在提取这些浅层特征时,无论是在效果上还是计算量上都具有显著的优势。那么为何不针对网络不同层特征的差异,设计不同的特征学习算子,将convolution和self-attention有机地结合物尽其用呢?
2. 网络架构
2.1 整体架构
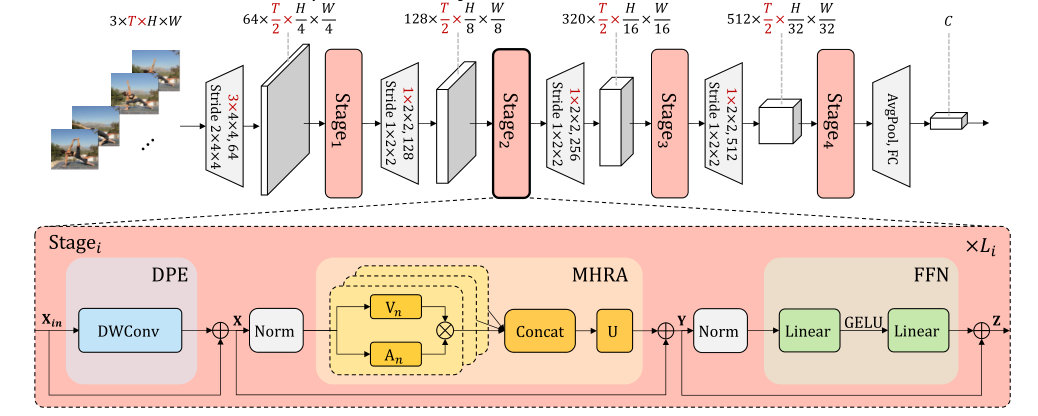
2.2 UniFormer block
模型整体框架如上所示,借鉴了CNN的层次化设计,每层包含多个Transformer风格的UniFormer block。
X = DPE ( X i n ) + X i n , Y = MHRA ( Norm ( X ) ) + X , Z = FFN ( Norm ( Y ) ) + Y . \begin{array}{l} \mathbf{X}=\operatorname{DPE}\left(\mathbf{X}_{i n}\right)+\mathbf{X}_{i n}, \\ \mathbf{Y}=\operatorname{MHRA}(\operatorname{Norm}(\mathbf{X}))+\mathbf{X}, \\ \mathbf{Z}=\operatorname{FFN}(\operatorname{Norm}(\mathbf{Y}))+\mathbf{Y} . \end{array} X=DPE(Xin)+Xin,Y=MHRA(Norm(X))+X,Z=FFN(Norm(Y))+Y.
每个UniFormer block主要由三部分组成,动态位置编码DPE、多头关系聚合器MHRA及Transformer必备的前馈层FFN,
2.3 MHRA
其中最关键的为多头关系聚合器:
R n ( X ) = A n V n ( X ) MHRA ( X ) = Concat ( R 1 ( X ) ; R 2 ( X ) ; ⋯ ; R N ( X ) ) U \begin{aligned} \mathrm{R}_{n}(\mathbf{X}) &=\mathbf{A}_{n} \mathrm{~V}_{n}(\mathbf{X}) \\ \operatorname{MHRA}(\mathbf{X}) &=\operatorname{Concat}\left(\mathrm{R}_{1}(\mathbf{X}) ; \mathrm{R}_{2}(\mathbf{X}) ; \cdots ; \mathrm{R}_{N}(\mathbf{X})\right) \mathbf{U} \end{aligned} Rn(X)MHRA(X)=An Vn(X)=Concat(R1(X);R2(X);⋯;RN(X))U
与多头注意力相似,我们将关系聚合器设计为多头风格,每个头单独处理一组channel的信息。每组的channel先通过线性变换生成上下文token V n ( X ) V_n(X) Vn(X),然后在token affinity A n ( X ) A_n(X) An(X)的作用下,对上下文进行有机聚合。
2.3.1 Local MHRA
基于前面的可视化观察,我们认为在网络的浅层,token affinity应该仅关注局部邻域上下文,这与convolution的设计不谋而合。因此,我们将局部关系聚合 A n l o c a l A_n^{local} Anlocal设计为可学的参数矩阵:
A n local ( X i , X j ) = a n i − j , where j ∈ Ω i t × h × w , \mathrm{A}_{n}^{\text {local }}\left(\mathbf{X}_{i}, \mathbf{X}_{j}\right)=a_{n}^{i-j} \text {, where } j \in \Omega_{i}^{t \times h \times w} \text {, } Anlocal (Xi,Xj)=ani−j, where j∈Ωit×h×w,
其中 X i X_i Xi为anchor token, X j X_j Xj为局部邻域 Ω i t × h × w \Omega_{i}^{t \times h \times w} Ωit×h×w任一token, a n a_n an为可学参数矩阵, i − j i-j i−j为二者相对位置,表明token affinity的值只与相对位置有关。这样我们的local UniFormer block实际是MobileNet block的风格相似,都是PWConv-DWConv-PWConv(见原论文解析),不同的是我们引入了额外的位置编码以及前馈层,这种特别的结合形式有效地增强了token的特征表达。
说的这么花里胡哨的其实就是使用了稍微大一点的卷积代替(5x5)实现局部关系
2.3.2 Global MHRA
在网络的深层,我们需要对整个特征空间建立长时关系,这与self-attention的思想一致,因此我们通过比较全局上下文相似度建立token affinity:
A n global ( X i , X j ) = e Q n ( X i ) T K n ( X j ) ∑ j ′ ∈ Ω T × H × W e Q n ( X i ) T K n ( X j ′ ) , \mathrm{A}_{n}^{\text {global }}\left(\mathbf{X}_{i}, \mathbf{X}_{j}\right)=\frac{e^{Q_{n}\left(\mathbf{X}_{i}\right)^{T} K_{n}\left(\mathbf{X}_{j}\right)}}{\sum_{j^{\prime} \in \Omega_{T \times H \times W}} e^{Q_{n}\left(\mathbf{X}_{i}\right)^{T} K_{n}\left(\mathbf{X}_{j^{\prime}}\right)}}, Anglobal (Xi,Xj)=∑j′∈ΩT×H×WeQn(Xi)TKn(Xj′)eQn(Xi)TKn(Xj),
其中 Q n ( ⋅ ) , K n ( ⋅ ) Q_n(\cdot),K_n(\cdot) Qn(⋅),Kn(⋅)为不同的线性变换。先前的video transformer,往往采用时空分离的注意力机制,以减少video输入带来的过量点积运算,但这种分离的操作无疑割裂了token的时空关联。相反,我们的UniFormer在网络的浅层采用local MHRA节省了冗余计算量,使得网络在深层可以轻松使用联合时空注意力,从而可以得到更具辨别性的video特征表达。
在网络的stage3和stage4,使用self-attention的结构,并进行了一些放缩。
2.4 Dynamic Position Embedding
流行的ViT往往采用绝对或者相对位置编码,但绝对位置编码在面对更大分辨率的输入时,需要进行线性插值以及额外的参数微调,而相对位置编码对self-attention的形式进行了修改。为了适配不同分辨率输入的需要,我们采用了最近流行的卷积位置编码设计动态位置编码:
DPE ( X i n ) = DWConv ( X i n ) , \operatorname{DPE}\left(\mathbf{X}_{i n}\right)=\operatorname{DWConv}\left(\mathbf{X}_{i n}\right), DPE(Xin)=DWConv(Xin),
其中DWConv为零填充的的深度可分离卷积。一方面,卷积对任何输入形式都很友好,也很容易拓展到空间维度统一编码时空位置信息。另一方面,深度可分离卷积十分轻量,额外的零填充可以帮助每个token确定自己的绝对位置。
3. 代码
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
from collections import OrderedDict
import torch
import torch.nn as nn
from functools import partial
import torch.nn.functional as F
import math
from timm.models.vision_transformer import _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, DropPath, to_2tuplelayer_scale = False
init_value = 1e-6class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass CMlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Conv2d(in_features, hidden_features, 1)self.act = act_layer()self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headshead_dim = dim // num_heads# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weightsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass CBlock(nn.Module):def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)self.norm1 = nn.BatchNorm2d(dim)self.conv1 = nn.Conv2d(dim, dim, 1)self.conv2 = nn.Conv2d(dim, dim, 1)self.attn = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = nn.BatchNorm2d(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def forward(self, x):x = x + self.pos_embed(x)x = x + self.drop_path(self.conv2(self.attn(self.conv1(self.norm1(x)))))x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass SABlock(nn.Module):def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)self.norm1 = norm_layer(dim)self.attn = Attention(dim,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop=attn_drop, proj_drop=drop)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)global layer_scaleself.ls = layer_scaleif self.ls:global init_valueprint(f"Use layer_scale: {layer_scale}, init_values: {init_value}")self.gamma_1 = nn.Parameter(init_value * torch.ones((dim)),requires_grad=True)self.gamma_2 = nn.Parameter(init_value * torch.ones((dim)),requires_grad=True)def forward(self, x):x = x + self.pos_embed(x)B, N, H, W = x.shapex = x.flatten(2).transpose(1, 2)if self.ls:x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))else:x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))x = x.transpose(1, 2).reshape(B, N, H, W)return x class head_embedding(nn.Module):def __init__(self, in_channels, out_channels):super(head_embedding, self).__init__()self.proj = nn.Sequential(nn.Conv2d(in_channels, out_channels // 2, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),nn.BatchNorm2d(out_channels // 2),nn.GELU(),nn.Conv2d(out_channels // 2, out_channels, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),nn.BatchNorm2d(out_channels),)def forward(self, x):x = self.proj(x)return xclass middle_embedding(nn.Module):def __init__(self, in_channels, out_channels):super(middle_embedding, self).__init__()self.proj = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),nn.BatchNorm2d(out_channels),)def forward(self, x):x = self.proj(x)return xclass PatchEmbed(nn.Module):""" Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])self.img_size = img_sizeself.patch_size = patch_sizeself.num_patches = num_patchesself.norm = nn.LayerNorm(embed_dim)self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)def forward(self, x):B, C, H, W = x.shape# FIXME look at relaxing size constraintsassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."x = self.proj(x)B, C, H, W = x.shapex = x.flatten(2).transpose(1, 2)x = self.norm(x)x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()return xclass UniFormer(nn.Module):""" Vision TransformerA PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` -https://arxiv.org/abs/2010.11929"""def __init__(self, depth=[3, 4, 8, 3], img_size=224, in_chans=3, num_classes=1000, embed_dim=[64, 128, 320, 512],head_dim=64, mlp_ratio=4., qkv_bias=True, qk_scale=None, representation_size=None,drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=None, conv_stem=False):"""Args:depth (list): depth of each stageimg_size (int, tuple): input image sizein_chans (int): number of input channelsnum_classes (int): number of classes for classification headembed_dim (list): embedding dimension of each stagehead_dim (int): head dimensionmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueqk_scale (float): override default qk scale of head_dim ** -0.5 if setrepresentation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if setdrop_rate (float): dropout rateattn_drop_rate (float): attention dropout ratedrop_path_rate (float): stochastic depth ratenorm_layer (nn.Module): normalization layerconv_stem (bool): whether use overlapped patch stem"""super().__init__()self.num_classes = num_classesself.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsnorm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) if conv_stem:self.patch_embed1 = head_embedding(in_channels=in_chans, out_channels=embed_dim[0])self.patch_embed2 = middle_embedding(in_channels=embed_dim[0], out_channels=embed_dim[1])self.patch_embed3 = middle_embedding(in_channels=embed_dim[1], out_channels=embed_dim[2])self.patch_embed4 = middle_embedding(in_channels=embed_dim[2], out_channels=embed_dim[3])else:self.patch_embed1 = PatchEmbed(img_size=img_size, patch_size=4, in_chans=in_chans, embed_dim=embed_dim[0])self.patch_embed2 = PatchEmbed(img_size=img_size // 4, patch_size=2, in_chans=embed_dim[0], embed_dim=embed_dim[1])self.patch_embed3 = PatchEmbed(img_size=img_size // 8, patch_size=2, in_chans=embed_dim[1], embed_dim=embed_dim[2])self.patch_embed4 = PatchEmbed(img_size=img_size // 16, patch_size=2, in_chans=embed_dim[2], embed_dim=embed_dim[3])self.pos_drop = nn.Dropout(p=drop_rate)dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depth))] # stochastic depth decay rulenum_heads = [dim // head_dim for dim in embed_dim]self.blocks1 = nn.ModuleList([CBlock(dim=embed_dim[0], num_heads=num_heads[0], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)for i in range(depth[0])])self.blocks2 = nn.ModuleList([CBlock(dim=embed_dim[1], num_heads=num_heads[1], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]], norm_layer=norm_layer)for i in range(depth[1])])self.blocks3 = nn.ModuleList([SABlock(dim=embed_dim[2], num_heads=num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]], norm_layer=norm_layer)for i in range(depth[2])])self.blocks4 = nn.ModuleList([SABlock(dim=embed_dim[3], num_heads=num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]+depth[2]], norm_layer=norm_layer)for i in range(depth[3])])self.norm = nn.BatchNorm2d(embed_dim[-1])# Representation layerif representation_size:self.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([('fc', nn.Linear(embed_dim, representation_size)),('act', nn.Tanh())]))else:self.pre_logits = nn.Identity()# Classifier headself.head = nn.Linear(embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity()self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):return {'pos_embed', 'cls_token'}def get_classifier(self):return self.headdef reset_classifier(self, num_classes, global_pool=''):self.num_classes = num_classesself.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):x = self.patch_embed1(x)x = self.pos_drop(x)for blk in self.blocks1:x = blk(x)x = self.patch_embed2(x)for blk in self.blocks2:x = blk(x)x = self.patch_embed3(x)for blk in self.blocks3:x = blk(x)x = self.patch_embed4(x)for blk in self.blocks4:x = blk(x)x = self.norm(x)x = self.pre_logits(x)return xdef forward(self, x):x = self.forward_features(x)x = x.flatten(2).mean(-1)x = self.head(x)return x@register_model
def uniformer_small(pretrained=True, **kwargs):model = UniFormer(depth=[3, 4, 8, 3],embed_dim=[64, 128, 320, 512], head_dim=64, mlp_ratio=4, qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)model.default_cfg = _cfg()return model@register_model
def uniformer_small_plus(pretrained=True, **kwargs):model = UniFormer(depth=[3, 5, 9, 3], conv_stem=True,embed_dim=[64, 128, 320, 512], head_dim=32, mlp_ratio=4, qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)model.default_cfg = _cfg()return model@register_model
def uniformer_small_plus_dim64(pretrained=True, **kwargs):model = UniFormer(depth=[3, 5, 9, 3], conv_stem=True,embed_dim=[64, 128, 320, 512], head_dim=64, mlp_ratio=4, qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)model.default_cfg = _cfg()return model@register_model
def uniformer_base(pretrained=True, **kwargs):model = UniFormer(depth=[5, 8, 20, 7],embed_dim=[64, 128, 320, 512], head_dim=64, mlp_ratio=4, qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)model.default_cfg = _cfg()return model@register_model
def uniformer_base_ls(pretrained=True, **kwargs):global layer_scalelayer_scale = Truemodel = UniFormer(depth=[5, 8, 20, 7],embed_dim=[64, 128, 320, 512], head_dim=64, mlp_ratio=4, qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)model.default_cfg = _cfg()return model参考资料
ICLR2022高分论文 UniFormer 卷积与自注意力的高效统一 - 知乎 (zhihu.com)
论文阅读|Uniformer_xiaoweiyuya的博客-CSDN博客
这篇关于【图像分类】2022-UniFormer IEEE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






