本文主要是介绍分类算法 朴素贝叶斯(NB算法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python代码及相关数据
链接:https://pan.baidu.com/s/1DhSsi5LdDlERv_g_v2-XVQ
提取码:sn53
第一部分 分类算法 NB算法
朴素贝叶斯 (NaiveBeyesian Classification)
一、概述
-
是基于贝叶斯定理与特征条件独立假设的分类方法
-
一种常见的机器学习任务
- 给定一个对象,将其划分到预定好的某类别中
-
(贝叶斯决策理论)核心思想
- 选择高概率对应的类别
二、贝叶斯原理
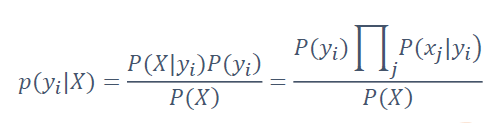
- P(X):待分类对象自身的概率,可忽略
- P(yi):每个类别的先验概率
- P(X|yi):每个类别产生对象概率
- P(xj|yi):每个类别产生该特征的概率
一共100篇文章,其中科技50篇,经济30篇,体育20篇
x-特征 y-类别 比如:苹果、电脑、手机就属于特征,科技、经济、体育就属于类别
所以科技先验概率P(yi)=50/100=0.5
P(xj|yi)就是每个类别中各个特征出现的概率
三、朴素贝叶斯的一般过程
- 1.搜集数据
- 2.准备数据
- 3.分析数据
- 4.训练算法
- 5.测试算法——计算错误率
- 6.使用算法——常用于文档分类
第二部分 实现步骤
零、搜集数据
根据搜集的数据,将数据进行分类,并重命名文件(文件id+文件类型),具体操作暂不赘述
一、准备数据
- 1.将80%的文章作为训练集,20%的文章作为测试集
- 2.将文章切割成词组,组成词典
- 3.将文章以id形式输出
比如(例子不太恰当,但是比较出名):
| 文章名 | 文章内容 | |
|---|---|---|
| 原文 | 《背影》 | 我与父亲不相见已二年余了,我最不能忘记的是他的背影 |
| 数据准备 | 001_prose | 我与父亲不相见已二年余了,我最不能忘记的是他的背影 |
| 分词 | 001_prose | 我 与 父亲 不 相见 已 二年 余 了 , 我 最 不能 忘记 的 是 他 的 背影 |
| 形成词典 | 001_prose_test | P 1 2 3 4 5 6 7 8 9 1 10 11 12 13 14 15 13 16 |
注意:形成词典,是指把所有文章的词语都包含了,无论训练数据还是测试数据,只是在文件名做区分xxx_test,yyy_train,训练数据时,只需读取文件名以test结尾的文件。
二、训练数据
此步骤只读取训练数据
1 获取文本特征
1.1 将未出现的词语保存在词典wordDic中
记录词语对应的id
wordDic={1:1, 2:1, 3:1 …}
wordDic{词语id:1}
1.2 统计词语出现的次数,保存在词典classDic中
统计词语出现的次数
classDic={‘P’:{1:10, 2:5 …}, ‘F’:{5:6, 11:7…}}
classDic{[文章类型]:[{词语id:出现次数}]}
2 求先验概率
2.1 文章类型先验概率
P(yi)=每类文章个数/文章总数
2.2文章每个词的先验概率(最大似然——特征x和类别y,在训练中出现的次数)
-
2.2.1 求出各类文章所有词语出现的次数
遍历classDic{[文章类型]:[词语id]}——获取各个词语id对应的出现次数word_id_count,相加即可得总词数
对P类文章 wordSumP = 10+5…
对F类文章 wordSumF = 6+7…
换言之,统计各类文章的总词数。比如:“苹果 手机 和 苹果 笔记本 电脑”的wordSum=6
-
2.2.2 求出各类文章每个词语的先验概率
word_id_count/wordSum
对P类文章 P(xj|yi)=word_id_count/wordSumP
对F类文章 P(xj|yi)=word_id_count/wordSumF
比如:“苹果 手机 和 苹果 笔记本 电脑”P(苹果|科技)=2/6
3.记录文章类型、文章先验概率、词语id、词语先验概率(最大似然)(空格分隔)
P类 P(yp) F类 P(yf) …(P类文章 P类文章先验概率 F类文章 F类文章先验概率…)
P类 word_id_1 p(x1|yp) word_id_2 p(x1|yp)…(P类文章 词语1 词语1先验概率 词语2 词语2先验概率…)
F类 word_id_5 p(x5|yf) word_id_11 p(x11|yf)…(F类文章 词语5 词语5先验概率 词语11 词语11先验概率…)
三、测试算法(评估模型)
此步骤只读取测试数据及训练数据得到的模型
1.读取模型
读出文章类型、文章先验概率、词语id、词语先验概率P(xj|yi)
2.获取测试文章的类型、词频
3.根据公式计算所有文章的概率
上步的每个词语id已知——词语先验概率P(xj|yi)已知,文章先验概率P(yi)已知,分别计算出在P类文章的概率(代入下列公式即可)
4.贝叶斯公式可转化为
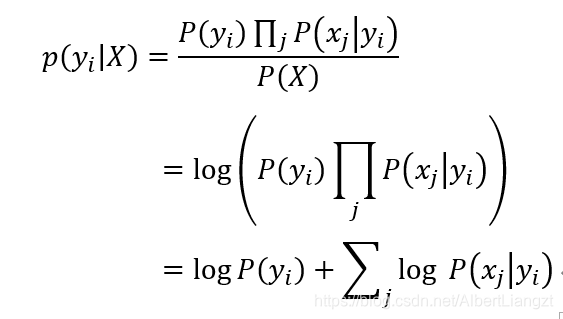
5.代入各个类型求解,取出最大值
根据上列公式可求出不同的概率,最大概率所对应的类型,就是预测类型
6.同理,求出所有预测结果,与原有类型进行比较
可将实际分类放入一个origin_list
每预测一篇文章,添加到predict_list
在下步操作中,直接遍历origin_list,对应predict_list中i下标即为实际类型和预测类型
7.准确度、精确度、召回率
准确度Accuracy=所有预测成功的/所有测试数据
精确率(P类)Precision=预测P类成功的/所有预测结果为P类
召回率(P类)Recall=预测P类成功的/P类实际总数
注意:需要预先给定一个词语默认概率,以防在字典中找不到该词语(只将测试集加入了词典,训练集可能存在新的词)
这篇关于分类算法 朴素贝叶斯(NB算法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







