本文主要是介绍分类算法-朴素贝叶斯NB,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CSDN截取后半部内容,所以迁移到简书,点开即可
分类技术概述
• 最常见的机器学习任务
• 定义:给定一个对象X,将其划分到预定义好的某一个类别Yi中
– 输入:X
– 输出:Y(取值于有限集合{y1,y2,……,yn})
• 应用:
– 人群,新闻分类,query分类,商品分类,网页分类,垃圾邮件过滤,网页排序
不同类型的分类
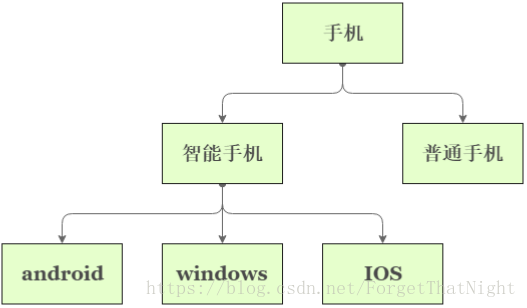
• 类别数量
– 二值分类
• Y的取值只有两种,如:email是否垃圾邮件
– 多值分类
• Y的取值大于两个,如:网页分类{政治,经济,体育,……}
• 类别关系
– 水平关系
• 类别之间无包含关系
– 层级关系
• 类别形成等级体系
新闻分类
• 任务– 为任一新闻,例如{股市,反弹,有力,基金,建仓,加速……}--找出刻画特征能力特别强的词语
– 指定其类别=>{军事,科技,财经,生活……}
• 基于规则的方式
– 列举每个类别的常用词
• 军事:导弹,军舰,军费……
• 科技:云计算,siri,移动互联网……
– 问题、局限性
• 如何保证列举全?
• 冲突如何处理?苹果:科技?生活?
• 不同的词有不同的重要度,如何决定?
• 如果类别很多怎么办?
分类任务解决流程
• 新闻分类• 特征表示:X={昨日,是,国内,投资,市场……}
• 特征选择:X={国内,投资,市场……}--筛选比较好的特征
• 数据建模:朴素贝叶斯分类器
• 训练数据准备
• 模型训练
• 预测(分类)
• 评测
分类技术

– NB
– 计算待分类对象属于每个类别的概率,选择概率最大的类别作为最终输出
• 空间分割
– SVM
• 其他
– KNN(没有训练,上来就预测,计算量很大,好性能,但是可能是最好的分类算法)
朴素贝叶斯分类
• 朴素贝叶斯(NaiveBeyesian Classification,NB)分类器– 概率模型
– 基于贝叶斯原理
• X:代表一个item,比如文章
• yi:类别
• P(yi):每个类别的先验概率,如P(军事)
• P(X|yi):每个类别产生该对象的概率
• P(xi|yi):每个类别产生该特征的概率,如P(苹果|科技)--众多特征组成一个item,然后对所有的特征token做一个连乘,所以公式成立建立在所有的特征相互独立同分布的假设上,所谓的朴素贝叶斯的朴素就是忽略了一些元素。
模型训练、参数估计
• 策略:最大似然估计(maximum likehood estimation,MLE)– P(Yi) 每个类别的先验概率
• Count(yi):类别为yi的对象在训练数据中出现的次数
– 例如:
• 总共训练数据1000篇,其中军事类300篇,科技类240篇,生活类140篇,……
• P(军事)=0.3, P(科技)=0.24, P(生活)=0.14,……
• 最大似然估计(maximum likehood estimation,MLE)
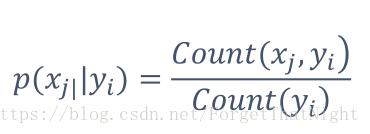
• Count(xj, yi):特征xj和类别yi在训练数据中同时出现的次数
– 例如:
• 总共训练数据1000篇,其中军事类300篇,科技类240篇,生活类140篇,……
• 军事类新闻中,谷歌出现15篇,投资出现9篇,上涨出现36篇
• P(谷歌|军事)=0.05, P(投资|军事)=0.03, P(上涨|军事)=0.12,……
这篇关于分类算法-朴素贝叶斯NB的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







