本文主要是介绍Spark SQL— Catalyst 优化器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spark SQL— Catalyst 优化器
1. 目的
本文的目标是描述Spark SQL 优化框架以及它如何允许开发人员用很少的代码行表达复杂的查询转换。我们还将描述Spark SQL如何通过大幅提高其查询优化能力来提高查询的执行时间。在本教程中,我们还将介绍什么是优化、为什么使用 Catalyst 优化器、其基本工作单元是什么以及 Spark 执行流程的各个阶段。
2. Apache Spark SQL优化简介
“优化一词是指修改系统以使其工作更高效或使用更少资源的过程。”
Spark SQL是 Apache Spark 中技术含量最高的组件。Spark SQL 处理 SQL 查询和 DataFrame API。Spark SQL 的深处有一个催化剂优化器。Catalyst 优化允许一些高级编程语言功能,使您可以构建可扩展的查询优化器。
一种名为 Catalyst 的新型可扩展优化器出现了,用于实现 Spark SQL。该优化器基于**Scala中的函数式编程构造。
Catalyst Optimizer 支持基于规则和基于成本的**优化。在基于规则的优化中,基于规则的优化器使用一组规则来确定如何执行查询。而基于成本的优化则找到最合适的方式来执行SQL语句。在基于成本的优化中,使用规则生成多个计划,然后计算它们的成本。
3. Catalyst Optimizer 的需求是什么?
Catalyst 的可扩展设计背后有两个目的:
- 我们希望添加简单的解决方案来解决**大数据**的各种问题,例如半结构化数据和高级数据分析的问题。
- 我们想要一种简单的方法,以便外部开发人员可以扩展优化器。
4. Catalyst Optimizer 的基础知识
Catalyst 优化器利用Scala 编程的标准功能,例如模式匹配。在深度上,Catalyst 包含树和操作树的规则集。有特定的库来处理关系查询。有各种规则集可以处理查询执行的不同阶段,例如分析、查询优化、物理规划和代码生成,以将部分查询编译为 Java 字节码。让我们详细讨论树和规则 -
4.1. 树木
树是催化剂中的主要数据类型。树包含节点对象。对于每个节点,都有一个节点。一个节点可以有一个或多个子节点。新节点被定义为 TreeNode 类的子类。这些对象本质上是不可变的。可以使用函数变换来操纵对象。
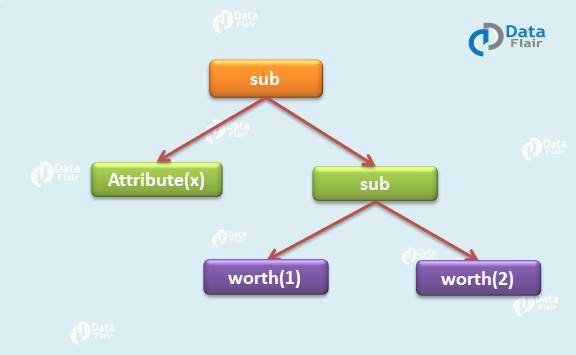
例如,如果我们有三个节点类:worth、attribute和sub,其中 -
- value(value: Int): 常量值
- 属性(名称:字符串)
- sub(左:TreeNode,右:TreeNode):两个表达式相减。
4.2. 规则
我们可以使用规则来操纵树。我们可以将规则定义为从一棵树到另一棵树的函数。通过规则,我们可以在输入树上运行任意代码,这是使用模式匹配函数并用特定结构替换子树的常见方法。在树中,借助变换函数,我们可以在树的所有节点上递归地应用模式匹配。我们得到将每个模式与结果相匹配的模式。
例如-
tree.transform {case Sub(worth(c1),worth(c2)) =>worth(c1+c2) }
在模式匹配期间传递给transform的表达式是一个偏函数。通过部分函数,这意味着它只需要匹配所有可能的输入树的子集。Catalyst 将查看给定规则适用于树的哪个部分,并自动跳过不匹配的树。使用相同的转换调用,规则可以匹配多个模式。
例如 -
*tree.transform {*
*case Sub(worth(c1),worth(c2)) =>worth(c1-c2)*
*case Sub(left ,worth(0)) => left*
*case Sub(worth(0), right ) => right*
*}*
为了完全转换一棵树,规则可能需要执行多次。
催化剂通过将规则分组为批次来工作,并且执行这些批次直到达到固定点。固定点是指即使在应用规则之后树也停止变化的点。
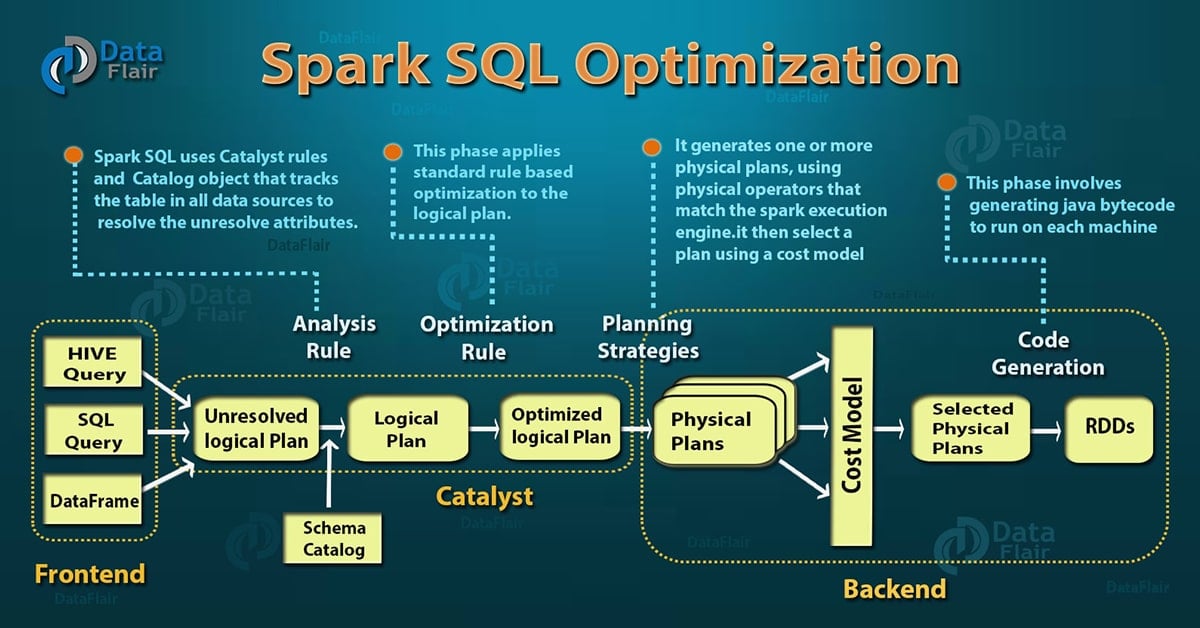
5.Spark SQL执行计划
在详细介绍了 Apache Spark SQL 催化剂优化器之后,现在我们将讨论 Spark SQL 查询执行阶段。我们分四个阶段使用 Catalyst 的通用树转换框架:
- 分析
- 逻辑优化
- 物理规划
- 代码生成
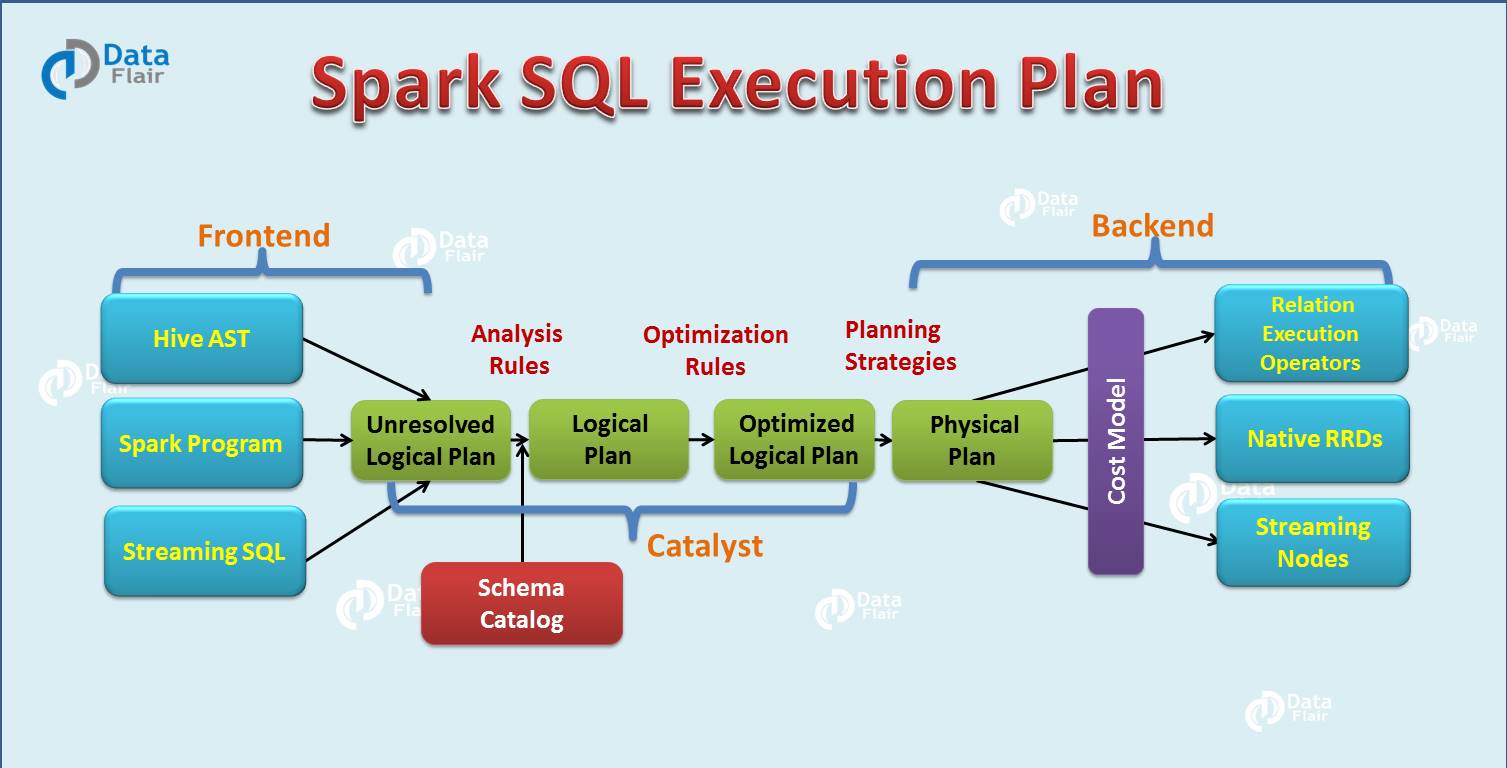
5.1. 分析
Spark SQL优化从要计算的关系开始。它是根据SQL 解析器返回的**抽象语法树 (AST)**或使用 API 创建的DataFrame对象计算的。两者都可能包含未解析的属性引用或关系。未解析的属性意味着我们不知道其类型或未将其与输入表匹配。Spark SQL 利用 Catalyst 规则和一个 Catalog 对象来跟踪所有数据源中的数据来解析这些属性。首先创建一个未解决的逻辑计划,然后应用以下步骤:
- 按目录中的名称搜索关系。
- 将名称属性(例如 col)映射到给定运算符子级提供的输入。
- 确定哪些属性与相同的值匹配,从而为它们提供唯一的 ID。
- 通过表达式传播和推送类型。
5.2. 逻辑优化
在 Spark SQL 优化的此阶段,标准的基于规则的优化应用于逻辑计划。它包括常量折叠、谓词下推、投影剪枝等规则。为各种情况添加规则变得非常容易。
5.3. 物理规划
物理规划规则大约有500行代码。在这一阶段,使用物理运算符匹配Spark执行引擎,从逻辑计划形成一个或多个物理计划。它使用成本模型选择计划。它仅使用基于成本的优化来选择连接算法。对于使用广播连接的小关系 SQL,该框架支持更广泛地使用基于成本的优化。它可以使用该规则递归地估计整个树的成本。
基于规则的物理优化,例如将投影或过滤器管道化到一个 Spark地图中操作也由物理规划器执行。除此之外,它还可以将逻辑计划中的操作推送到支持谓词或投影下推的数据源中。
5.4. 代码生成
Spark SQL 优化的最后阶段是代码生成。它涉及生成在每台机器上运行的 Java 字节码。Catalyst 使用 Scala 语言的特殊功能“ Quasiquotes ”来使代码生成变得更容易,因为构建代码生成引擎非常困难。Quasiquotes 允许以 Scala 语言以编程方式构造抽象语法树 (AST),然后可以在运行时将其提供给 Scala 编译器以生成字节码。在催化剂的帮助下,我们可以将表示 SQL 表达式的树转换为 Scala 代码的 AST,以计算该表达式,然后编译并运行生成的代码。
6. 总结
因此,Spark SQL 优化提高了开发人员的工作效率以及他们编写的查询的性能。一个好的查询优化器会自动重写关系查询以更有效地执行,使用早期过滤数据、利用可用索引等技术,甚至确保不同的数据源以最有效的顺序连接。
通过执行这些转换,优化器可以缩短关系查询的执行时间,并使开发人员不再关注应用程序的语义而不是性能。
Catalyst 利用 Scala 的强大功能(例如模式匹配和运行时元编程)来允许开发人员简洁地指定复杂的关系优化。
这篇关于Spark SQL— Catalyst 优化器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






