本文主要是介绍政安晨:【Keras机器学习实践要点】(五)—— 通过子类化创建新层和模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras实战演绎机器学习
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
介绍
本文将涵盖构建自己的子类化层和模型所需的所有知识。
您将了解以下功能:
层类
add_weight()方法
可训练和不可训练的权重
build()方法
确保您的层可以与任何后端一起使用
add_loss()方法
call()中的训练参数
call()中的掩码参数
确保您的层可以序列化
让我们开始吧。

安装
import numpy as np
from tensorflow import keras
from keras import ops
from keras import layers层级:状态(权重)与某些计算的组合
Keras 的核心抽象之一是层类。
层封装了状态(层的 "权重")和从输入到输出的转换("调用",层的前向传递)。
下面是一个密集连接的层。它有两个状态变量:变量 w 和 b。
class Linear(keras.layers.Layer):def __init__(self, units=32, input_dim=32):super().__init__()self.w = self.add_weight(shape=(input_dim, units),initializer="random_normal",trainable=True,)self.b = self.add_weight(shape=(units,), initializer="zeros", trainable=True)def call(self, inputs):return ops.matmul(inputs, self.w) + self.b你可以通过调用一个层函数来使用它,就像调用Python函数一样,传入一些张量输入。
x = ops.ones((2, 2))
linear_layer = Linear(4, 2)
y = linear_layer(x)
print(y)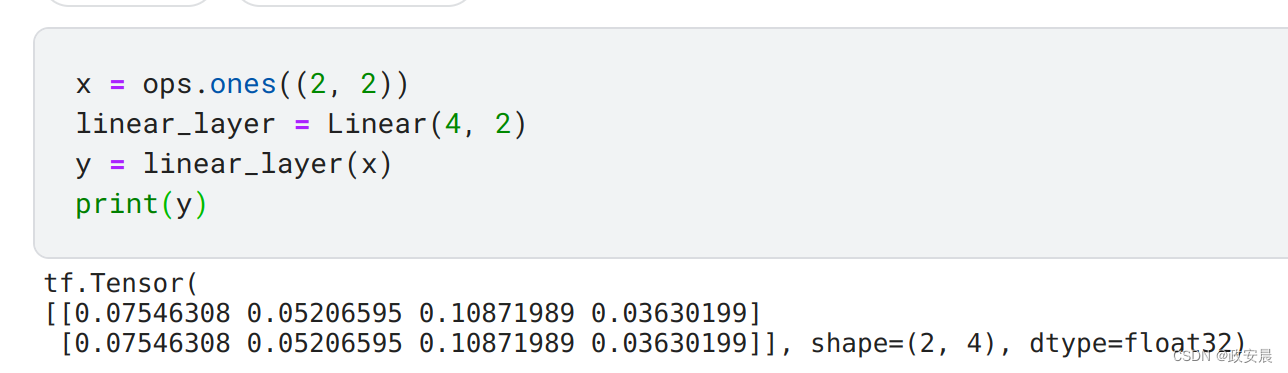
请注意,权重 w 和 b 在被设置为层属性后,会被层自动跟踪:
assert linear_layer.weights == [linear_layer.w, linear_layer.b]层可以有不可训练的重量
除了可训练权重外,还可以向层添加不可训练权重。在反向传播过程中,这些权重在训练层时不会被考虑在内。
下面介绍如何添加和使用不可训练权重:
class ComputeSum(keras.layers.Layer):def __init__(self, input_dim):super().__init__()self.total = self.add_weight(initializer="zeros", shape=(input_dim,), trainable=False)def call(self, inputs):self.total.assign_add(ops.sum(inputs, axis=0))return self.totalx = ops.ones((2, 2))
my_sum = ComputeSum(2)
y = my_sum(x)
print(y.numpy())
y = my_sum(x)
print(y.numpy())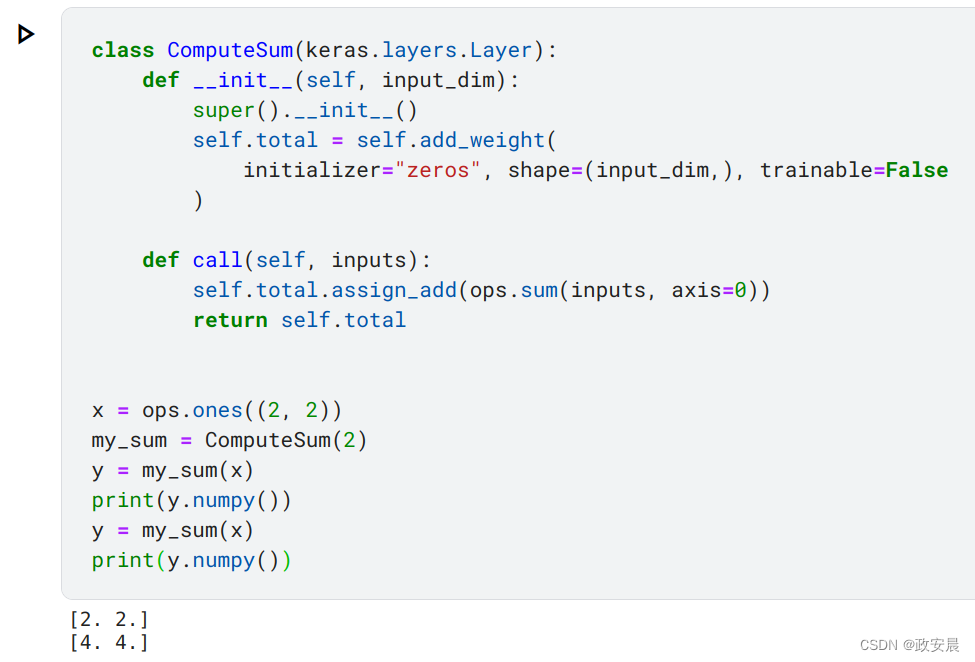
它是层权重的一部分,但被归类为不可训练的权重。
print("weights:", len(my_sum.weights))
print("non-trainable weights:", len(my_sum.non_trainable_weights))# It's not included in the trainable weights:
print("trainable_weights:", my_sum.trainable_weights)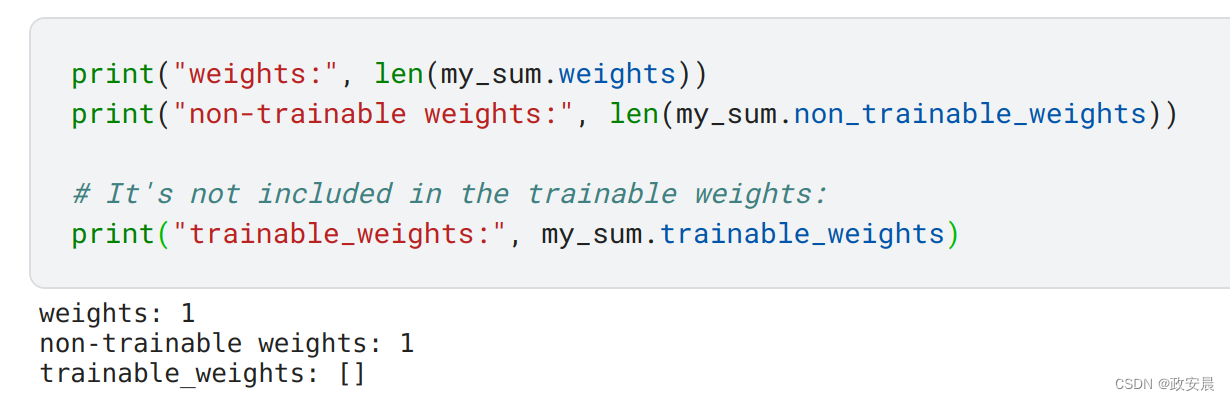
最佳实践:推迟权重的创建,直到输入的形状已知。
我们上面的线性层接受了一个input_dim参数,该参数用于在__init__()函数中计算权重w和偏置b的形状。
class Linear(keras.layers.Layer):def __init__(self, units=32, input_dim=32):super().__init__()self.w = self.add_weight(shape=(input_dim, units),initializer="random_normal",trainable=True,)self.b = self.add_weight(shape=(units,), initializer="zeros", trainable=True)def call(self, inputs):return ops.matmul(inputs, self.w) + self.b在许多情况下,您可能无法预先知道输入的大小,并且希望在实例化图层后的某个时间,当该值变为已知时,才懒惰地创建权重。
在Keras API中,我们建议在您的图层的build(self, inputs_shape)方法中创建图层权重。
像这样:
class Linear(keras.layers.Layer):def __init__(self, units=32):super().__init__()self.units = unitsdef build(self, input_shape):self.w = self.add_weight(shape=(input_shape[-1], self.units),initializer="random_normal",trainable=True,)self.b = self.add_weight(shape=(self.units,), initializer="random_normal", trainable=True)def call(self, inputs):return ops.matmul(inputs, self.w) + self.b您的层的__call__()方法在第一次被调用时会自动运行build。
现在您有一个懒惰的层,因此更容易使用。
# At instantiation, we don't know on what inputs this is going to get called
linear_layer = Linear(32)# The layer's weights are created dynamically the first time the layer is called
y = linear_layer(x)将build()单独实现如上所示,很好地将只创建权重一次与在每次调用中使用权重进行了分离。
层可以递归组合
如果你将一个 Layer 实例分配为另一个 Layer 的属性,外层将开始跟踪内层创建的权重。
我们建议在 init() 方法中创建这样的子层,并在第一个 call() 中触发构建它们的权重。
class MLPBlock(keras.layers.Layer):def __init__(self):super().__init__()self.linear_1 = Linear(32)self.linear_2 = Linear(32)self.linear_3 = Linear(1)def call(self, inputs):x = self.linear_1(inputs)x = keras.activations.relu(x)x = self.linear_2(x)x = keras.activations.relu(x)return self.linear_3(x)mlp = MLPBlock()
y = mlp(ops.ones(shape=(3, 64))) # The first call to the `mlp` will create the weights
print("weights:", len(mlp.weights))
print("trainable weights:", len(mlp.trainable_weights))
后端不可知层和特定后端层
只要一个层只使用 keras.ops 命名空间的 API(或者其他 Keras 命名空间,例如 keras.activations、keras.random 或 keras.layers),那么它就可以与任何后端一起使用——TensorFlow、JAX 或 PyTorch。
到目前为止,在本指南中看到的所有层都适用于所有Keras后端。
keras.ops命名空间提供了以下功能:
NumPy API,例如ops.matmul,ops.sum,ops.reshape,ops.stack等。
神经网络特定的API,例如ops.softmax,ops.conv,ops.binary_crossentropy,ops.relu等。
您还可以在层中使用本机后端API(例如tf.nn函数),但是如果这样做,您的层只能与特定的后端一起使用。
例如,您可以使用jax.numpy编写以下特定于JAX的层:
import jaxclass Linear(keras.layers.Layer):...def call(self, inputs):return jax.numpy.matmul(inputs, self.w) + self.b这将是等效的TensorFlow特定层:
import tensorflow as tfclass Linear(keras.layers.Layer):...def call(self, inputs):return tf.matmul(inputs, self.w) + self.b这将是等效的PyTorch特定层:
import torchclass Linear(keras.layers.Layer):...def call(self, inputs):return torch.matmul(inputs, self.w) + self.b由于跨后端兼容性是一种非常有用的特性,我们强烈建议您始终通过仅使用Keras APIs来使您的层与后端无关。
add_loss()方法
在编写层的call()方法时,您可以创建损失张量,以便在编写训练循环时稍后使用。通过调用self.add_loss(value)可以实现这一点。
# A layer that creates an activity regularization loss
class ActivityRegularizationLayer(keras.layers.Layer):def __init__(self, rate=1e-2):super().__init__()self.rate = ratedef call(self, inputs):self.add_loss(self.rate * ops.mean(inputs))return inputs这些损耗(包括任何内层创建的损耗)可以通过 layer.losses 检索到。
该属性在每次调用顶层层的 __call__() 开始时重置,因此 layer.losses 总是包含上次向前传递时创建的损耗值。
class OuterLayer(keras.layers.Layer):def __init__(self):super().__init__()self.activity_reg = ActivityRegularizationLayer(1e-2)def call(self, inputs):return self.activity_reg(inputs)layer = OuterLayer()
assert len(layer.losses) == 0 # No losses yet since the layer has never been called_ = layer(ops.zeros((1, 1)))
assert len(layer.losses) == 1 # We created one loss value# `layer.losses` gets reset at the start of each __call__
_ = layer(ops.zeros((1, 1)))
assert len(layer.losses) == 1 # This is the loss created during the call above此外,损失属性还包含为任何内层权重创建的正则化损失:
class OuterLayerWithKernelRegularizer(keras.layers.Layer):def __init__(self):super().__init__()self.dense = keras.layers.Dense(32, kernel_regularizer=keras.regularizers.l2(1e-3))def call(self, inputs):return self.dense(inputs)layer = OuterLayerWithKernelRegularizer()
_ = layer(ops.zeros((1, 1)))# This is `1e-3 * sum(layer.dense.kernel ** 2)`,
# created by the `kernel_regularizer` above.
print(layer.losses)打印结果:
[Array(0.00217911, dtype=float32)]在编写自定义训练循环时,应考虑到这些损失。
它们也可以与fit()方法无缝配合使用(如果有的话,会自动将它们求和并添加到主要损失中):
inputs = keras.Input(shape=(3,))
outputs = ActivityRegularizationLayer()(inputs)
model = keras.Model(inputs, outputs)# If there is a loss passed in `compile`, the regularization
# losses get added to it
model.compile(optimizer="adam", loss="mse")
model.fit(np.random.random((2, 3)), np.random.random((2, 3)))# It's also possible not to pass any loss in `compile`,
# since the model already has a loss to minimize, via the `add_loss`
# call during the forward pass!
model.compile(optimizer="adam")
model.fit(np.random.random((2, 3)), np.random.random((2, 3)))
可以选择在您的层上启用序列化功能
如果需要将自定义层作为功能模型的一部分进行序列化,可以选择实现 get_config() 方法:
class Linear(keras.layers.Layer):def __init__(self, units=32):super().__init__()self.units = unitsdef build(self, input_shape):self.w = self.add_weight(shape=(input_shape[-1], self.units),initializer="random_normal",trainable=True,)self.b = self.add_weight(shape=(self.units,), initializer="random_normal", trainable=True)def call(self, inputs):return ops.matmul(inputs, self.w) + self.bdef get_config(self):return {"units": self.units}# Now you can recreate the layer from its config:
layer = Linear(64)
config = layer.get_config()
print(config)
new_layer = Linear.from_config(config){'units': 64}请注意,基本的Layer类的__init__()方法接受一些关键字参数,特别是name和dtype。
在__init__()中将这些参数传递给父类,并将它们包含在层的配置中是一个好的做法。
class Linear(keras.layers.Layer):def __init__(self, units=32, **kwargs):super().__init__(**kwargs)self.units = unitsdef build(self, input_shape):self.w = self.add_weight(shape=(input_shape[-1], self.units),initializer="random_normal",trainable=True,)self.b = self.add_weight(shape=(self.units,), initializer="random_normal", trainable=True)def call(self, inputs):return ops.matmul(inputs, self.w) + self.bdef get_config(self):config = super().get_config()config.update({"units": self.units})return configlayer = Linear(64)
config = layer.get_config()
print(config)
new_layer = Linear.from_config(config){'name': 'linear_7', 'trainable': True, 'dtype': 'float32', 'units': 64}如果在从配置反序列化层时需要更大的灵活性,也可以覆盖 from_config() 类方法。
这是 from_config() 的基本实现:
def from_config(cls, config):return cls(**config)顺序模型主题咱们就到这里。
这篇关于政安晨:【Keras机器学习实践要点】(五)—— 通过子类化创建新层和模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







