本文主要是介绍【物联网】Qinghub Kafka 数据采集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基础信息
组件名称 : kafka-connector
组件版本: 1.0.0
组件类型: 系统默认
状 态: 正式发布
组件描述:通用kafka连接网关,消费来自kafka的数据,并转发给下一个节点做相关的数据解析。
配置文件:
注: 配置文件仅供修改升级组件式利用,一般情况下对用户透明。无需做任何更改,除非用户需要手动维护组件心跳或通信端口时,一般情况下禁止修改。
df:component:##全局参数name: tcp-connectortype: 2 #1:采集器;2:接收器;3:转换器;4:存储器;5:解析器;6:状态解析器:7:同步器;8:消息通知transportPort: 49096 #内部akkaheartbeatCron: 0/30 * * ? * * * #网关心跳数据上报时间##全局参数结束##组件参数parameter:connection[0]:name: TCP服务端口号key: tcp.portrequired: truedefault-value: 16060input-type: inputdescription: TCP服务占用的端口value-type: intbase[0]:name: 数据包类型key: tcp.packet.typerequired: truedefault-value: 1value-type: intinput-type: selectselect-option: 字符串类型|1,字节类型|2base[1]:name: 数据包固定分割字节数组ASCII值key: tcp.delimiterrequired: falsedefault-value: 13,10input-type: inputdescription: TCP数据包固定分割符十进制ASCII值,多个用英文,分割value-type: stringbase[2]:name: Byte类型数据包长度字节数key: tcp.length.field.lengthrequired: falsedefault-value: 2input-type: inputdescription: 整个Byte类型的TCP数据包,包长度字节段一共有几个字节,用于长度拆包模式value-type: intbase[3]:name: Byte类型数据包长度数据段起始位置偏移key: tcp.length.field.offsetrequired: falsedefault-value: 0input-type: inputdescription: 长度字节段在整个数据包中从起始位置的偏移,用于长度拆包模式value-type: intbase[4]:name: Byte类型数据包长度含义key: tcp.length.meaningrequired: falsedefault-value: 1input-type: selectselect-option: 长度字节后数据长度|1,整个TCP包长度|2description: 数据包中字节长度的含义,是长度字节后面的字节长度,还是整个TCP包的长度value-type: intadvance[0]:name: 连接最大空闲时间秒数key: tcp.timeout.secondsrequired: falsevalue-type: intdefault-value: 60input-type: inputdescription: TCP连接最大空闲时间,单位秒,默认60秒advance[1]:name: TCP包每一帧最大字节数key: tcp.max.frame.lengthrequired: falsevalue-type: intdefault-value: 2048input-type: inputdescription: TCP包每一帧最大字节数,超过最大字节数会丢弃数据并关闭连接,默认2048组件测试
针对所有网关,操作方式均为,拖动网关-》配置网关-》启动网关
- 配置网关
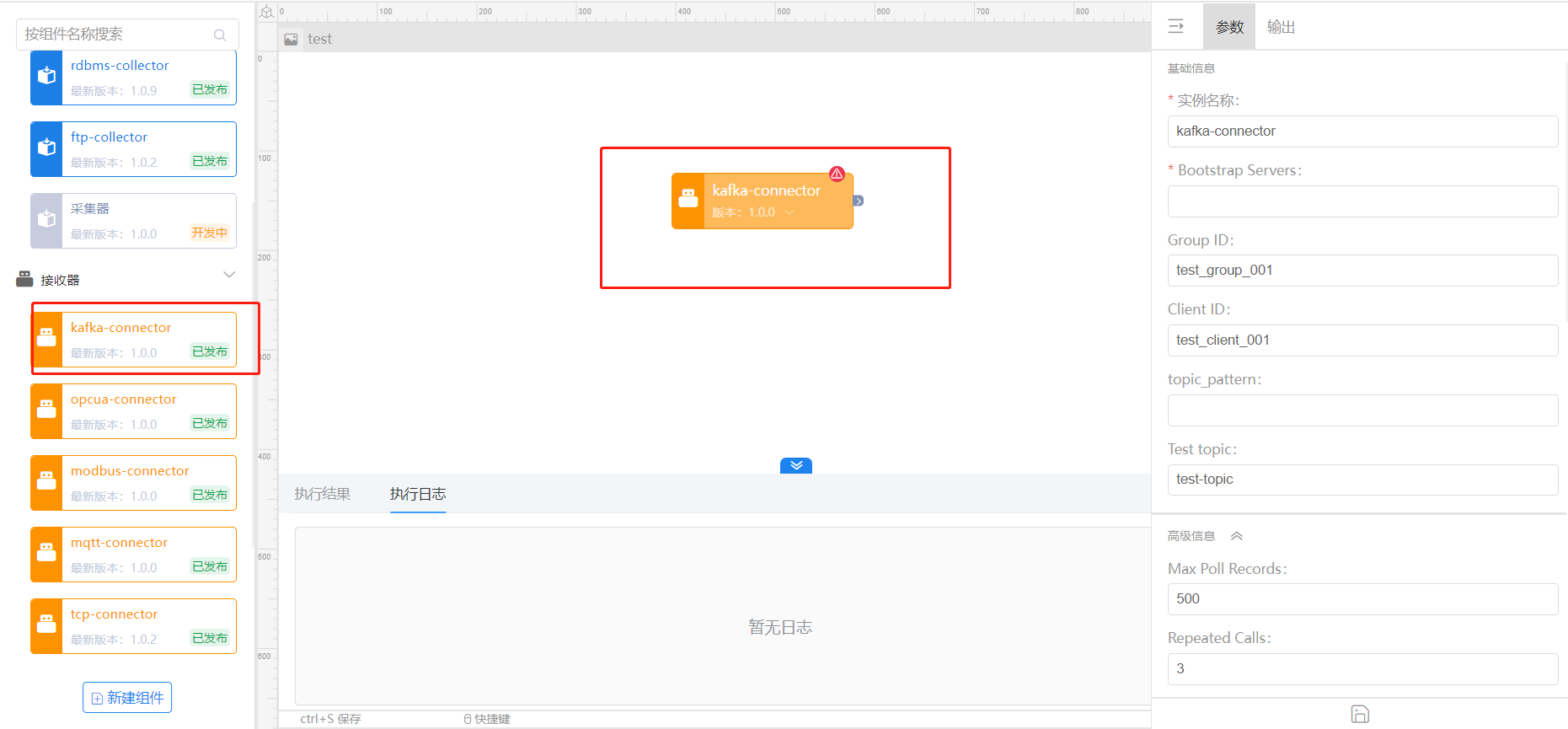
- 参数说明

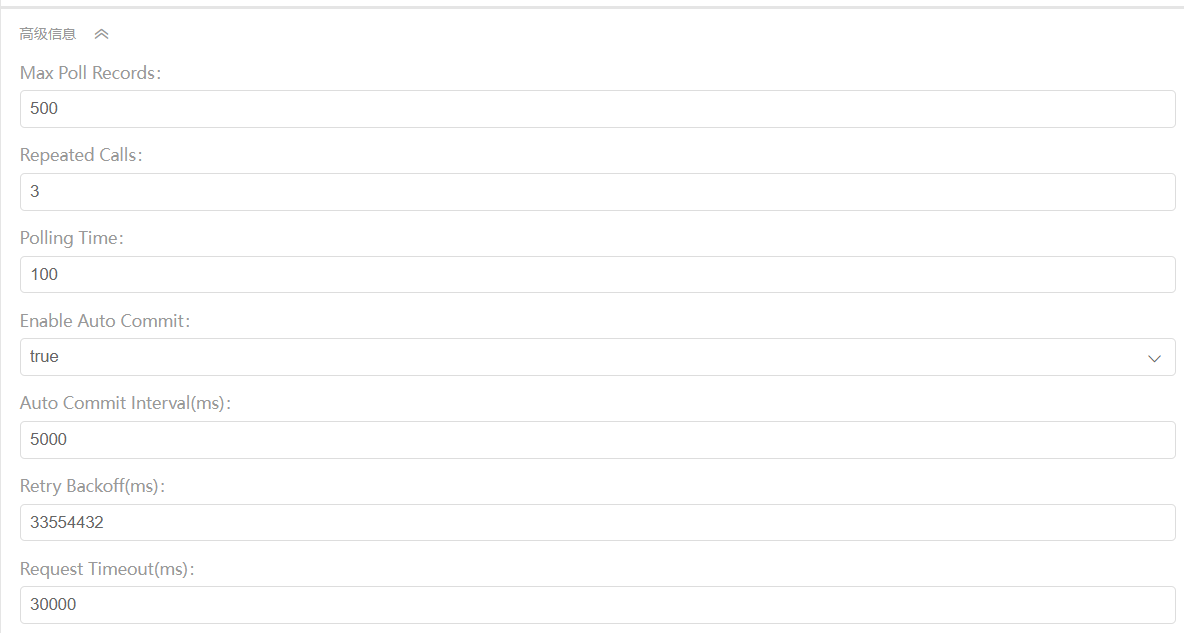
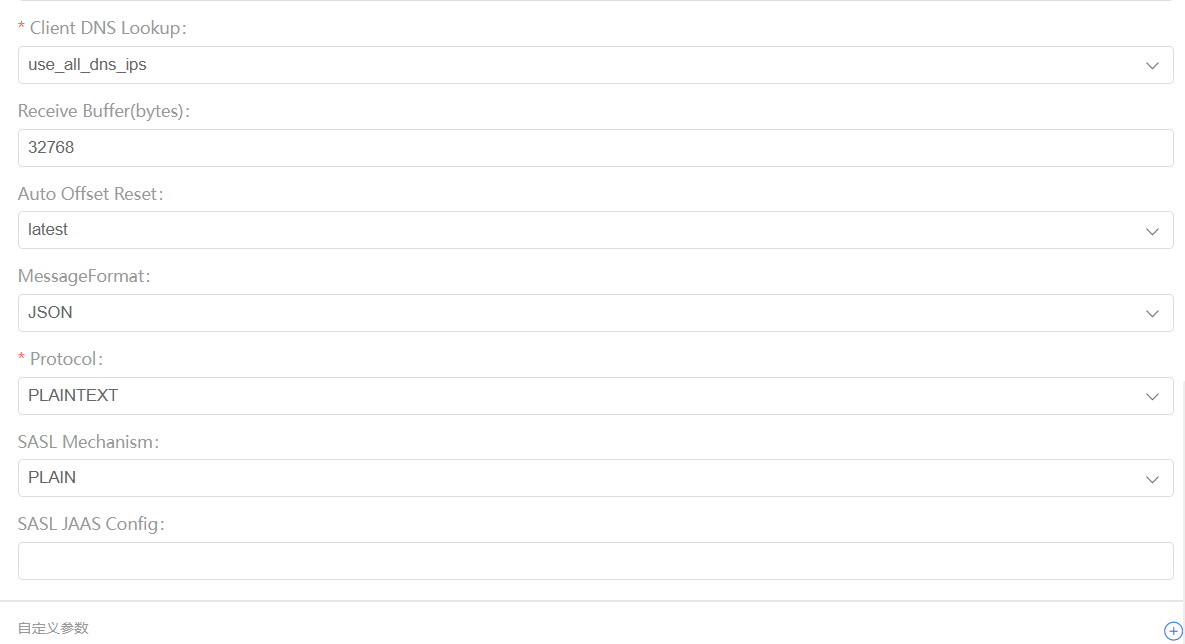
- 启动网关
注意观察执行日志,确保网关正常运行,状态status 字段为1时表示正常运行中
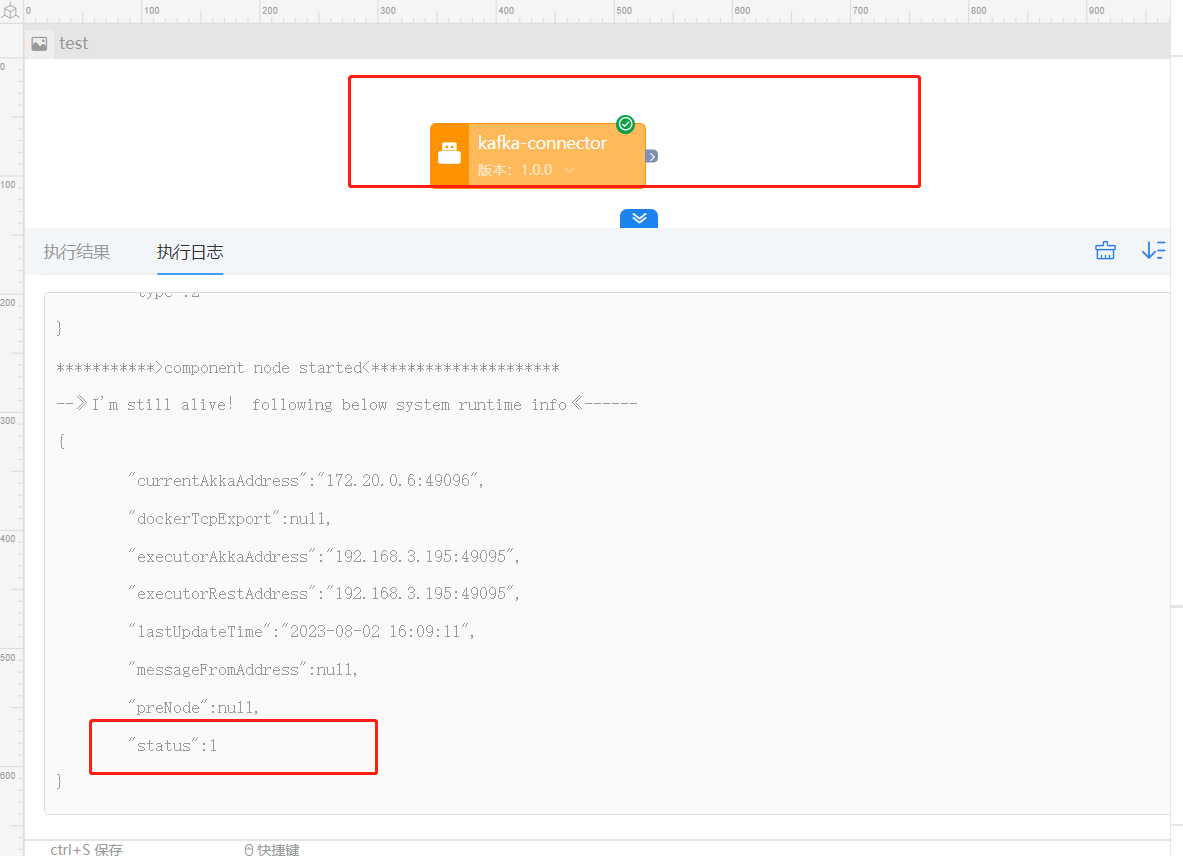
- 测试验证
1)前提准备:
已经安装好kafka 节点并一正常启动,测试环境kafka信息如下:
IP: 192.168.3.195
PORT: 19092
用户/密码: NONE
2)配置参数

我们只关注到主要的配置信息。高级配置保持默认即可。
3)启动网关
确保kafka-connector已经正常启动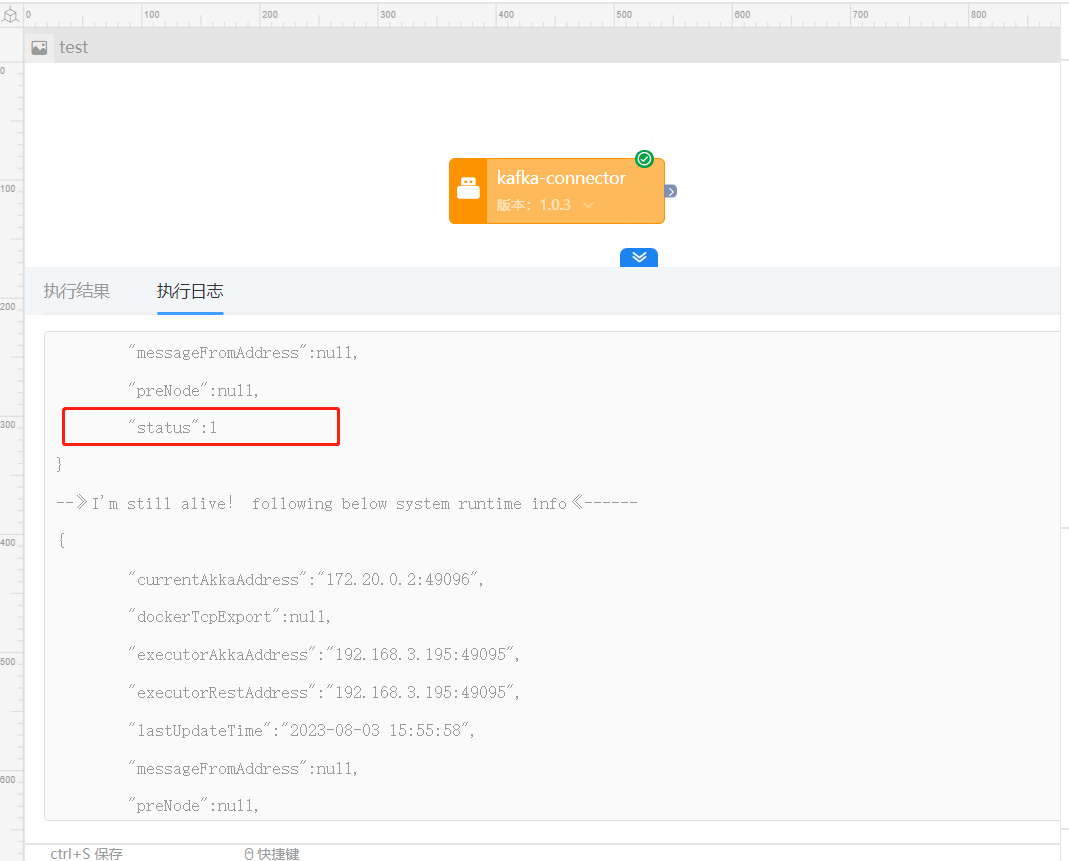
通过kafka客户端直接发送测试数据:
/opt/kafka_2.13-3.3.1/bin
[develop@itserver01 bin]$ ./kafka-console-producer.sh --broker-list 192.168.3.195:19092 --topic test-topic
4)状态确认
使用TCP 测试工具连接tcp-connector并发送数据执行测试
观察tcp-connector网关日志信息确认是否成功
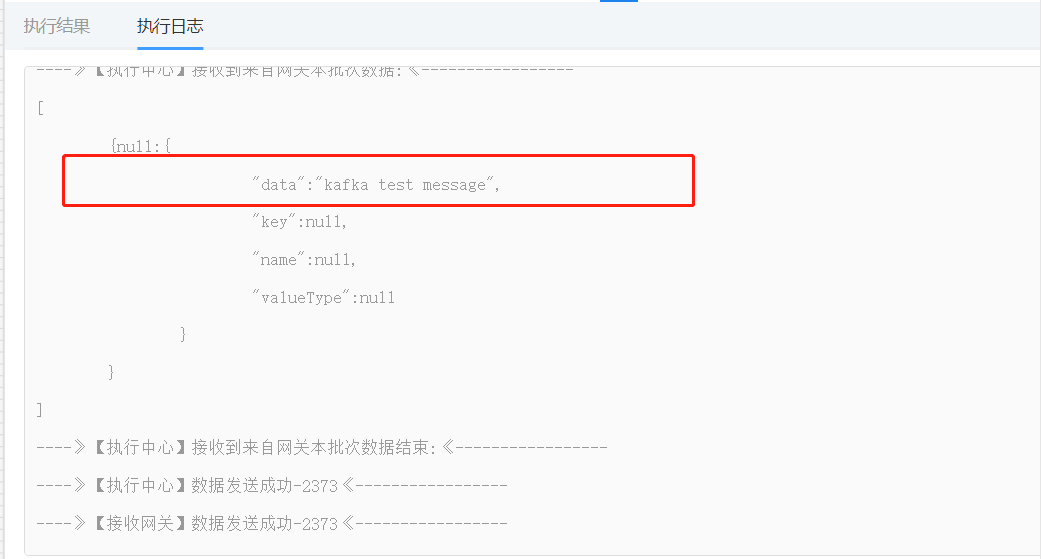
如果收到与发送的消息一致即配置成功。
注意:这里返回消息日志中大量的null,请不用关注,在整个架构设计中,我们数据发送的格式全都采用的统一的格式,而所有结构网关类型的组件上传的数据完全不关心数据格式,只负责转发数据,由其他对应的组件做相关的数据处理。
这篇关于【物联网】Qinghub Kafka 数据采集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





