本文主要是介绍新能源风电数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

需要的同学私信联系,推荐关注上面图片右下角的订阅号平台 自取下载。
AI+新能源风电数据可以促进风电领域人工智能及智能运维新技术产、学、研、用协作,引领行业技术创新,助力风电人工智能及智能运维高质量发展,进一步推广人工智能、智能巡检、状态检测、在线监测、智慧运维、无损检测等方向的创新应用,如风机无人机智能巡检、风电机组智慧故障预警、基于AI技术的风电功率预测、基于AI技术的风机关键部件预测性维护等等。因此小编在这里整理了一份AI+新能源风电数据集,共包含6+细分场景数据集,助力AI+新能源风电领域的研究与创新。
1. 风机叶片结冰预测数据集
2. 风机叶片开裂预警数据集
3. 风机叶片表面缺陷检测数据集
4. 龙源风力机组发电数据集
5. 风力电机异音AI诊断数据集
6. 风机运行故障诊断数据集
01
—
风机叶片结冰预测数据集

【背景介绍】叶片结冰是风电领域的一个全球范围难题。低温环境所导致的叶片结冰、材料及结构性能改变、载荷改变的问题等,对风机的发电性能和安全运行造成较大的威胁。在这样的情况下运行会增加叶片折断损坏的风险。实际应用中面临的挑战是很难对结冰的早期过程进行精确预测,以便能够尽早开启除冰系统。
【问题描述】SCADA系统每天产生大量的数据,但是目前大部分的系统依然局限于对已发生故障的报警。这些故障到达报警阶段时往往已经比较严重,需要对风机进行停机和维修,造成巨大的发电损失和维护成本。通过对SCADA系统产生的大数据环境进行挖掘和建模,能够对一些严重故障进行预测和诊断,从而使过去应激型的维护方式转变为主动预测型的维护方式,能够有效地改善风电设备的使用率和运维成本。
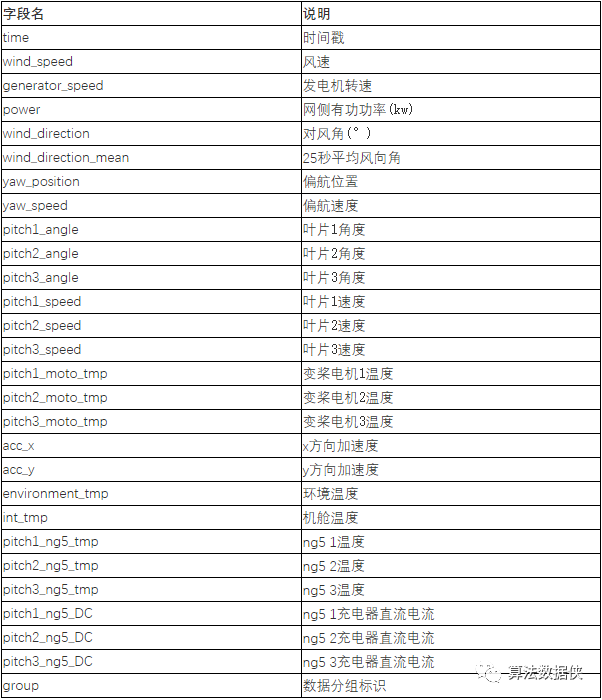
【数据描述】SCADA系统的数据通常有上百个变量,系统提供的数据经过筛选保留了其中28个连续数值型变量,涵盖了风机的工况参数、环境参数和状态参数等多个维度。变量的名称及说明如下表所示:
train训练集:包括两个风机的数据,存在两个以风机编号命名的文件夹中。每个文件夹中的数据包括3个文件:
编号_data.csv:风机连续时间内的SCADA原始数据(详细内容如上表所示)
编号_normalinfo.csv:风机正常状态的时间段,第一列为起始时间,第二列为结束时间
编号_failureinfo.csv:风机结冰故障的时间段,第一列为起始时间,第二列为结束时间
风机正常时间区间和风机结冰时间区间均不覆盖的数据视为无效数据
test测试数据集和final最终数据集:数据集中同样有若干个以风机编号为命名的文件夹,每个文件夹中包括1个文件:
编号_data.csv:风机连续时间内的SCADA原始数据。
需要注意的是,train数据集中time变量和一列为真实的时间戳,会存在数据不连续的情况,期间会出现停机或人为删除部分数据的情况;test和final数据集中的time变量为连续的数字序号,序号的排列是按照时间的先后顺序,但中间会存在由于停机等原因造成的数据不连续情况。可下载的训练数据包含了训练数据中一个风机的所有相关数据。
【代码说明】项目源码在Industrial_BigData_Code文件夹,主要包括以下10个脚本:
1、console.py——控制台,作为函数调用的总端口
2、labelGen.py——从原始数据中生成结冰标签信息
3、feature_selector_process.ipynb——用feature_selector库尝试预筛选数据的Jupyter Notebook草稿本
4、Script.ipynb—观察特征关系的草稿本
5、plot.py—两特征作图观察(与草稿本同)
6、avgData.py——根据时间戳对数据分组取平均值处理
7、cutPower.py——截去高功率数据(依据:观察得功率高时无结冰)
8、svm_method.py——使用SVM算法训练模型
9、score.py——计算模型准确率及得分
10、tmp.py—求C参量脚本(未接入console.py)
02
—
风机叶片开裂预警数据集

【数据背景】叶片作为风力发电机将风能转化为电能的主要连接部件,其健康状态受到业界的高度重视。根据某公司的统计,风场运行8年中,停机超过7天及以上的机组失效事故中因叶片开裂导致的事故,占事故总数的30%,且多发在盛风发电期间。叶片开裂危害发电机组轴系、塔筒等部件,甚至造成倒塔事件。如何检测叶片的健康状态,特别是在复杂工况下出现裂纹时候如何能够快速而准确的判断出叶片裂纹损伤状态,这是叶片健康状态监测的一个重要方面。
【问题描述】SCADA是风场设备管理、监测、和控制的重要系统,通过实时收集风机运行的环境参数、工况参数、状态参数和控制参数使风场管理者能够实时了解风电装备资产的运行和健康状态。基于SCADA数据建立叶片开裂模型,对早期叶片开裂故障进行告警,可以避免风场因叶片开裂导致的更大损失,提升风机运行稳定性,提升机组发电量。基于风机SCADA实时数据,通过机器学习、深度学习、统计分析等方法建立叶片开裂早期故障检测模型,对叶片开裂故障进行提前告警。
【数据描述】数据集包含3个文件,train.zip、test.zip和train_labels.csv:
train.zip: 存放用于训练的采集数据,每个CSV为10分钟内采样得到的一个样本点;
test.zip:存放用于测试的采集数据,每个CSV为10分钟内采样得到的一个样本点;
train_label.csv:存放用于训练的标注信息,如ID=×××,Label=0(1);ID为csv样本文件名称,Label为对应的标注信息,0表示该样本点对应风机一周内未发生故障,1表示该样本点对应的风机在一周内发生故障。
03
—
风机叶片表面缺陷检测数据集

【数据背景】由于风机叶片的复杂物理结构,它们的受力状态会随着风速的变化而发生变化,这使得它们成为最容易发生故障的部位。如果不能及时检测风机叶片的缺陷和故障隐患,提前预防故障的发生,并保证风机叶片的正常运行,就会因风机叶片缺陷而造成风机断裂、风机倒塌等严重损失。因此,风机叶片缺陷检测具有极其重要的意义和价值。
【问题描述】利用深度学习目标检测方法进行风机叶片缺陷检测,需要大量带类别标签的风机叶片损伤图像作为训练集、验证集和测试集。但到目前为止全球还没有公开的、带类别标签的风机叶片图像数据集。本数据集来源大部分是无人机航拍巡检拍摄的风机图片,通过目标检测、机器视觉、检测大模型等方法建立风机叶片缺陷检测模型,实现风机叶片的高效预测性维护。
【应用领域】AI+缺陷目标检测
【文件目录】train文件夹,内含原始图像与标注信息
【数据说明】共包含3688+实况风机叶片图像,均带有xml标注,图像已统一处理为640×640,未做数据增广,可自行划分训练集、验证集和测试集。
风机叶片缺陷类型包含10大类:前缘腐蚀、叶尖开放性损坏、表面涂料脱落、表面灰尘油污、表面砂眼不平、表面腐蚀、表面附着物、雷击烧痕、非开放性开裂。需要注意的是,一张图像样本可能有1个或多个缺陷。
04
—
龙源风力机组发电数据集

【数据背景】随着清洁能源的快速发展,风力发电已经成为可再生能源的重要组成部分,然而风具有随机性特点,常规天气预报无法准确反映出风电场所在区域的真实风速,从而造成发电功率预测准确率低下,影响电力供需平衡。因此,提高风电功率预测的准确性,为电网调度提供科学支撑,对我国能源产业有十分重要的价值。
【应用领域】AI+风电功率预测
【文件目录】预选赛数据集.zip,区域赛训练集.zip
【数据说明】预选赛训练数据和区域赛训练数据分别为不同10个风电场近一年的运行数据共30万余条,每15分钟采集一次,包括风速、风向、温度、湿度、气压和真实功率等。根据官方提供的数据集,设计一种利用当日05:00之前的数据,预测次日00:00至23:45实际功率的方法。准确率按日统计,根据10个风电场平均准确率进行排名;准确率相同的情形下,根据每日单点的平均最大偏差绝对值排名。
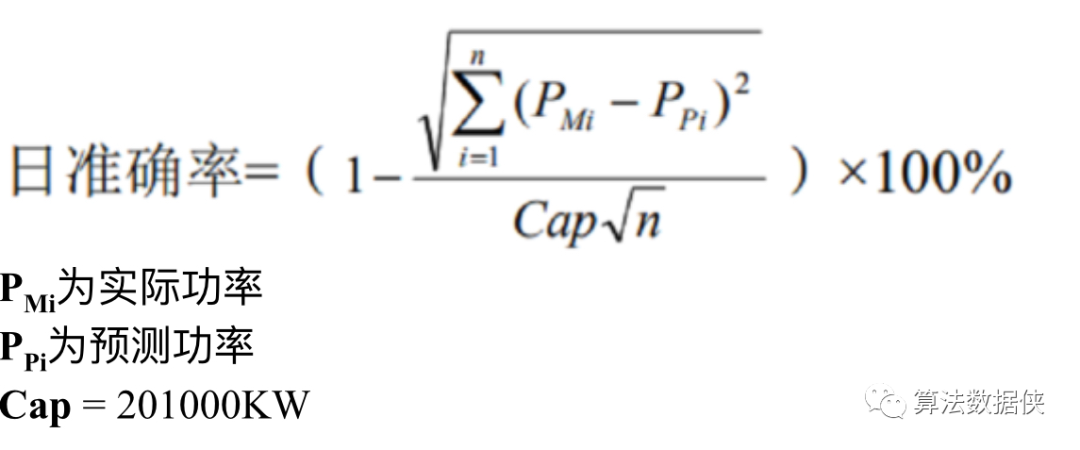
05
—
风力电机异音AI诊断数据集

【数据背景】在风力电机生产线上普遍采用人工听音的方法分辨良、次品,不仅成本高,而且重复、单调的听音工作极易引起人员疲劳,容易出现误判,若个别不良品混入整批成品中,会给工厂带来严重经济损失,甚至严重影响产品声誉。基于加速度传感器采集的振动信号,利用机器学习、深度学习等人工智能技术,设计智能检验的算法,要求算法对故障电机不能有漏识别,在召回100%的情况下,尽量提高预测准确率,以达到替代人工质检的目的。
【应用领域】AI+风机故障诊断
【数据描述】数据集包含2个文件,Motor_tain.zip和Motor_testP.zip:
Motor_tain.zip:用于训练的采集数据,其中文件夹“正样本”包含30个异常电机的数据样本,文件夹“负样本”包含500个正常电机的数据样本;
Motor_testP.zip:用于测试的采集数据,包含500个电机的数据样本;
【文件说明】采集数据时是分别对电机正转、反转时的振动信号进行采集。也就是说每台电机有两条数据,其中F代表正转,B代表反转。每条数据包含两路振动信号,数据文件命名规则:编号_旋转方向.csv。
06
—
风机运行故障诊断数据集

【数据背景】设备监测和故障诊断一直以来都是工业领域研究的热点,一方面随着现代企业生产大型化和连续化的发展,对工业设备的安全性、稳定性提出了更高的要求,另一方面及时了解设备运行状态、了解设备运行周期、预警故障发生等方面才能最大限度地发挥设备的生产潜力。风机是风电企业最主要的设备,对风机的运行状况和故障诊断具有重要的理论和实际意义。
【应用领域】AI+风机故障诊断
【文件目录】Wind Farm 1 - Failures 2016、Wind Farm 1 - Failures 2017、Wind Farm 1 - Logs 2016、Wind Farm 1 - Logs 2017、Wind Farm 1- Metmast 2016、Wind Farm 1 - Metmast 2017、Wind Farm 1 - Signals 2016、Wind Farm 1 - Signals 2017、Wind Farm 1 Locations、Wind Farm Power Curve等10个文件夹
【数据说明】包括2016—2017年EDP集团旗下某风电场的运行数据:
Failures:历史故障纪录;
Logs:历史运行记录(风机);
Metmast:气象数据,包含风速、风向、温度、压力等要素;
Signals:风机运行参数,包含转速、轴承温度、油温、风速等;
Locations:位置信息
Power Curve:功率发电数据
07
—
结束语
以上就是AI+新能源风电领域数据集的所有内容了,更多数据集下载请关注文章顶部图片右下角平台即可获取。
这篇关于新能源风电数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





